导言
由于单 CPU 核心的性能上限,现代计算机的进化方向很早就转向了多核心架构。多核心架构使得操作系统能够同时运行多个任务,这个时候高效的多任务调度就成为了刚需,因此多任务调度器应运而生,操作系统使用调度器来决定这些任务的执行顺序和管理资源分配。Linux 作为应用最广泛的开源操作系统内核,其调度器设计和实现一直是操作系统领域的重要研究课题。本文将全面解读 Linux 内核的调度器设计与实现,内容涵盖早期的 O(1) 调度器、服役时间最长的 CFS 调度器以及最新一代的 EEVDF 调度器。通过本文,你将了解到 Linux 调度器的设计理念、实现原理以及代码实现细节。
P.S. 本文中"任务"和"进程"是同义词,文中可能会交替使用这两个词,它们表示同一个概念。文中的代码片段来自不同的 Linux 内核版本:CFS 调度器的代码片段来自 v6.5 版本,EEVDF 调度器的代码片段来自 v6.15 版本。
进程和线程
在 Linux 内核中,进程 process 通过数据结构 task_struct 来表示,每一个进程都是一个任务 task,task_struct 也称之为进程描述符 (process descriptor)。对于每一个进程,task_struct 始终都是在内存中的,它包含了内核管理进程所需的所有信息,比如调度参数、已打开的文件描述符列表、进程状态、已挂起的信号、内存地址空间等。进程描述符从进程被创建开始就一直存在于内核堆栈之中,直至进程被销毁。
为了兼容其他 UNIX 系统,Linux 还通过进程标识符 (PID) 来唯一标识每一个进程。内核将所有进程的 task_struct 组成一个双向链表,PID 可以直接映射到 task_struct 的地址,因此可以通过 PID 快速访问进程描述符。
task_struct 包含的进程信息可以大致归纳为以下几大类:
- 调度参数:进程优先级、最近消耗的 CPU 时间、最近休眠的时间等。这些信息用于调度器决定进程的执行顺序。
- 内存映射:指向代码段、数据段、堆栈段或页表的指针。内核通过这些指针来管理进程的内存空间;如果代码段是共享的,代码指针会指向共享代码段的页表。如果进程不在内存中的话,那么进程在磁盘中的位置也会被记录在
task_struct中。 - 信号:信号掩码字段可以表示当前哪些信号被忽略、哪些信号需要被捕获、哪些信号被暂时阻塞,以及哪些信号正在被处理。
- 机器寄存器:当内核陷阱 (trap) 发生时,机器寄存器的内容 (包括被使用了的浮点寄存器里的内容) 会被保存到
task_struct中。这样,当进程被调度回来时,内核可以恢复寄存器的内容,继续执行之前的任务。 - 系统调用状态:关于当前系统调用的信息,包括参数和返回值。
- 文件描述符表:指向进程打开的文件描述符表的指针。每个文件描述符都对应一个打开的文件或设备,内核通过这些描述符来管理进程对文件的访问。
- 统计数据:关于进程运行状态的统计信息,包括 CPU 使用率、内存占用、I/O 等待时间等。
- 内核堆栈:每个进程都有一个内核堆栈,用于保存进程在内核态下的执行上下文。当进程发生系统调用或中断时,内核会使用这个堆栈来保存现场信息。这个堆栈的大小通常是固定的,足以容纳内核调用的参数和局部变量。
- 其他:进程当前的状态。包括正在等待的事件、距离警报时钟超时的时间、PID、父进程的 PID,以及其他用户标识符、组标识符等。
有别于其他操作系统会明确地区分进程和线程,线程在 Linux 内核中的实现比较独特:内核并不单独定义和实现线程,也就是说没有定义专门的数据结构来表示一个线程,而是统一使用 task_struct 来表示进程和线程,所有的执行单元都是一个 task_struct。因此,一个单线程的进程只有一个 task_struct,而一个多线程的进程则会为每一个线程分配一个 task_struct;从内核的角度来看,并没有线程这个概念,线程只不过是一个与其他进程共享某些资源 (比如地址空间、打开文件描述符等) 的进程,在内核中所有的执行单元都是一个 task,所以内核在调度任务时也不会区分进程和线程。
概括来说,进程是操作系统分配资源的最小单位,线程是操作系统调度任务的最小单位。也就是说,进程是资源容器,线程是执行单元。一个进程包含一个或多个线程,线程共享进程的资源比如地址空间、已打开文件描述符列表、信号处理函数等,但每个线程都有自己的执行上下文,比如堆栈、寄存器。
Linux 调度器
O(1) 调度器
在 2.6.23 之前,Linux 使用的是一种称之为 O(1) 的调度器,之所以叫这个名字是因为它能够在常数时间内完成一次任务调度:从运行队列中选择一个任务或者将一个可运行的任务加入到运行队列中,这个过程的时间复杂度是 O(1),与系统中的任务总数无关。在 O(1) 调度器中,调度队列被分成了两个数组:活跃数组和过期数组。如下图所示,每个数组都包含了 140 个链表头,每个链表具有不同的优先级,每一个链表头都指向一个特定优先级的双向进程链表。
-scheduler.png)
O(1) 调度器会从活跃数组中选择一个优先级最高的任务进行调度,如果这个任务的时间片过期失效了,就将其移动到过期数组中(可能会被插入到跟之前优先级不同的数组中)。如果正在运行的任务阻塞了,比如等待 I/O 事件,也会被移到过期数组,在时间片过期之前,一旦 I/O 事件发生,任务就会被重新放回活跃数组继续运行,时间片会根据它所消耗的 CPU 时间相应地减少,一旦任务的时间片消耗完,就会再次被移到过期数组中。当活跃数组中没有任务可调度时,O(1) 调度器会交换指针,将活跃数组和过期数组互换,使得过期数组变成活跃数组,活跃数组变成过期数组,重新开始调度。这样的话能够保证低优先级的任务不会被饿死。不同的优先级被赋予了不同的时间片长度,高优先级的进程会获得更长的时间片,而低优先级的进程则会获得更短的时间片。
O(1) 之所以采用这种调度模式,主要是为了让进程能够更快地从内核中退出来;如果一个进程试图读取一个磁盘文件,在调用 read(2) 系统调用之间等待一秒钟显然会及大地降低进程的效率,所以应该在每次系统调用完成之后立刻将进程从内核态中恢复到用户态运行,这样也能让下一次系统调用更快地被执行。而如果一个进程因为等待键盘输入而阻塞,那么这明显是一个交互进程,这一类进程应该被赋予更高的优先级,从而保证交互进程能提供更好的用户体验。在这种模式下,当 I/O 密集型的进程和交互进程阻塞之后,CPU 密集型的进程就会把 CPU 资源占满。
由于内核无法事先知道一个进程是 I/O 密集型还是 CPU 密集型,所以只能依赖于持续性的交互式启发式方法 (interactivity heuristics) 来判定。通过这种方式,内核会区分静态优先级和动态优先级,任务的动态优先级会被不断重新计算,这样做的主要目的是:
- 奖励交互型进程
- 惩罚 CPU 密集型进程
最高的优先级奖励是 -5,最低的优先级惩罚是 +5。这样一来,交互型进程就会获得更高的优先级从而获得更大的 CPU 时间片,而 CPU 密集型进程则会被惩罚,降低其优先级从而只能得到更小的 CPU 时间片。调度器会给每一个任务维护一个 sleep_avg 的变量,每当任务被唤醒时,这个变量就会增加,而当任务被抢占或者时间片用完时,这个变量就会相应地减少.这个变量的数值变化会被用来动态生成优先级奖励或惩罚,范围是 [-5, +5]。当一个任务从活跃数组移动到过期数组时,调度器会重新计算它的优先级。
O(1) 调度器的优势是性能极高,因为使用的数据结构是数组,能够在 O(1) 的时间复杂度内完成任务调度;缺点是使用了这种启发式方法来动态调整任务的优先级,会使得调度器的复杂度变得非常高,更要命的是这种方法首先并不是总是有效的,这也导致了 O(1) 调度器在调度交互型进程的时候表现得很糟糕。为了解决 O(1) 调度的缺陷,内核引入了一种新的调度器 —— CFS。
调度类
Linux 为了将内核的调度器模块化,增强扩展性,在版本 2.6.23 中引入了调度类 (scheduler class) 的概念。调度类是内核中用于管理不同调度器实现的抽象层,它定义了调度器的通用方法,可以理解成是一个接口。调度类定义了一组函数指针,指向具体的函数实现,这些函数是回调函数,对应多任务调度过程中的不同事件,比如任务入队、任务出队、任务选定等。如果要往内核中添加一个新的调度器,只需要实现一个新的调度类,并将其注册到内核中即可。这样,内核可以在不修改核心调度代码的前提下,不仅能够很方便地切换不同的调度器,还可以同时支持多个调度器。
调度器类的定义如下1 (删减了一些函数指针):
struct sched_class {
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq);
bool (*yield_to_task)(struct rq *rq, struct task_struct *p);
void (*check_preempt_curr)(struct rq *rq, struct task_struct *p, int flags);
struct task_struct *(*pick_next_task)(struct rq *rq);
void (*task_tick)(struct rq *rq, struct task_struct *p, int queued);
void (*update_curr)(struct rq *rq);
/* ... */
};
Linux 内核中一共有五种调度类实现,分别是:
stop_sched_classdl_sched_classrt_sched_classfair_sched_classidle_sched_class
stop_sched_class
Stop 是内核中优先级最高的调度类,调度的原理是通过一个内核线程抢占其他正在运行的任务并霸占 CPU,然后在 CPU 上运行一些特定的函数,Stop 调度类可以直接抢占任何正在 CPU 上运行的任务然后独占 CPU 执行自己的代码,Stop 调度的这个内核线程是不可被抢占的,其他任务想要拿到 CPU 资源必须等待 Stop 的内核线程执行完或者主动让出 CPU。Stop 调度类只支持在 SMP (Symmetric Multi-Processing) 系统中使用,不支持 UP (Uniprocessor) 系统。
Stop 调度类的主要用途是:
- 任务迁移
- CPU 热插拔
- RCU 同步机制
- ftrace 跟踪
- Clockevents 时钟事件
- ...
dl_sched_class
DL (Deadline) 调度类用于调度系统中最高优先级的任务,这些任务都有一个截止时间 (deadline),也就是任务必须在这个时间之前完成。DL 调度的任务以 deadline 为 key 从小到大组织成一棵时序红黑树,调度类每次都会选择红黑树的最左子节点,也就是截止时间最早的任务来运行。DL 调度类主要用于周期性实时任务的调度,比如音视频处理、机器人控制等需要严格时间限制的任务。
rt_sched_class
RT (Real-Time) 调度类用于调度符合 POSIX 标准的实时任务,这些任务具有严格的优先级要求,RT 调度类会根据任务的静态优先级来调度任务。RT 调度类的任务使用链表来存储,链表中的任务按照优先级从高到低排列,调度器每次都会选择链表头部的任务来运行。RT 调度类中的任务可以一直在 CPU 运行,这些任务只能被优先级更高的任务抢占。RT 调度类的使用场景是性能敏感的任务调度,也就是那些严格要求低延迟、实时响应的任务,比如 IRQ threads。
fair_sched_class
Fair 调度类也就是大家熟知的 CFS (Completely Fair Scheduler),是 Linux 内核的默认调度器。它用于调度系统中的大部分普通类型的任务。所有任务以 vruntime (虚拟时间) 为 key 从小到大组织成一棵时序红黑树,调度类每次都会选择红黑树的最左子节点,也就是 vruntime 最小的任务来运行。调度任务时使用动态时间片而非静态时间片,CFS 调度器会根据任务的权重和系统中可运行任务的数量动态计算每个任务的时间片。类似的,权重也会用于计算 vruntime 的流速,权重越大,vruntime 增长得越慢,反之 vruntime 增长得越快。关于 CFS 更具体的分析请见后文。
idle_sched_class
Idle 调度类是优先级最低的,用于调度 CPU 空闲时的任务,也就是当其他的调度类中已经没有可运行的任务时,Idle 调度类才会在 CPU 上运行一些 idle 任务,原理和 Stop 调度类相似,也是通过启动一个内核线程到 CPU 上运行。Idle 调度类的任务通常是一些优先级很低的任务,比如系统空闲时的后台任务等。Idle 调度类的这个内核线程还会尽量降低 CPU 的功耗和温度。
调度策略
在内核调度器调度任务时,还有一个重要概念是调度策略 (scheduling policies),调度策略是指内核调度器在调度任务时所采用的具体算法和规则,调度器基于调度策略来挑选下一个要运行的任务。Linux 内核中的调度策略可以换分为两大类:实时调度策略和非实时调度策略。
实时策略
- SCHED_FIFO:实时优先级队列,FIFO (First In First Out) 队列,任务按照优先级从高到低排列,优先级相同的任务按照到达时间顺序执行。SCHED_FIFO 的任务可以一直运行直到被更高优先级的任务抢占或者主动让出 CPU。
- SCHED_RR:实时轮转调度策略,类似于 SCHED_FIFO,但每个任务会有一个固定的 CPU 时间片,时间片用完之后会被抢占,轮转到下一个同优先级或者优先级更高的任务。SCHED_RR 的任务也按照优先级从高到低排列,优先级相同的任务按照到达时间顺序执行。时间片的值在
/proc/sys/kernel/sched_rr_timeslice_ms中定义。 - SCHED_DEADLINE:实时截止时间调度策略,任务按照截止时间从早到晚排列,调度器每次选择截止时间最早的任务来运行。SCHED_DEADLINE 策略的任务具有最高的优先级,可以抢占 SCHED_FIFO 和 SCHED_RR 策略的任务。
非实时策略
- SCHED_NORMAL:以前叫 SCHED_OTHER。用于普通进程调度的非实时调度策略,CFS 调度器使用的默认策略。每个任务会有一个权重值 nice,范围是 [-20, 19],nice 值越大优先级越低,反之越高,任务按照 vruntime (虚拟时间) 从小到大排列,调度器每次选择 vruntime 最小的任务来运行,vruntime 的计算是加权的,取决于 nice 值。SCHED_NORMAL 策略的任务的优先级低于 SCHED_FIFO 和 SCHED_RR 策略的任务,所以可以被后两类任务抢占。
- SCHED_BATCH:衍生自 SCHED_NORMAL,非实时批处理调度策略,适用于一些不需要实时响应的 CPU 密集型批处理任务。这类任务的一个优势是调度器会承诺尽量不抢占,所以它们运行的时间可以更长,所以能更充分地利用 CPU 缓存,但交互性差。
- SCHED_IDLE:空闲调度策略,优先级最低,用于调度 CPU 空闲时的任务。SCHED_IDLE 策略的任务只有在没有其他可运行任务时才会被调度。
内核中不同调度类选择的调度策略如下:
| 调度类 | 实现 | 调度策略 |
|---|---|---|
| stop_sched_class | Stop 调度器 | None |
| dl_sched_class | Deadline 调度器 | SCHED_DEADLINE |
| rt_sched_class | Real Time 调度器 | SCHED_FIFO、SCHED_RR |
| fair_sched_class | CFS 调度器 | SCHED_NORMAL、SCHED_BATCH、SCHED_IDLE |
| idle_sched_class | Idle 调度器 | None |
调度类链表
内核调度核心同时管理着上面介绍的这五个调度类,这五个调度类的优先级从高到低连成一个链表:
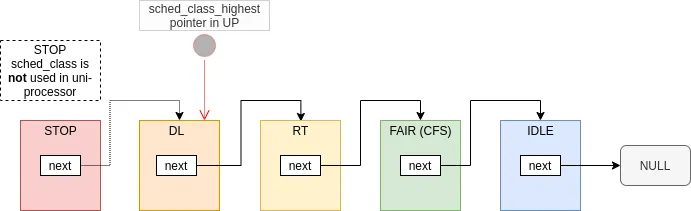
内核中通过一个宏定义来遍历调度类链表2:
#define for_class_range(class, _from, _to) \
for (class = (_from); class < (_to); class++)
#define for_each_class(class) \
for_class_range(class, __sched_class_highest, __sched_class_lowest)
#define sched_class_above(_a, _b) ((_a) < (_b))
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;
在调度器进行多任务调的时候,需要选择下一个最有资格运行的任务,此时调度器会遍历这个调度类链表,依次调用每一个调度类的 pick_next_task() 函数来挑选出下一个要运行的任务。因此,SCHED_FIFO 或者 SCHED_RR 调度策略的实时进程永远要比 SCHED_NORMAL 调度策略的普通进程被优先选中执行3。
/*
* Pick up the highest-prio task:
*/
static inline struct task_struct *
__pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
/* ... */
restart:
put_prev_task_balance(rq, prev, rf);
for_each_class(class) {
p = class->pick_next_task(rq);
if (p)
return p;
}
BUG(); /* The idle class should always have a runnable task. */
}
CFS 调度器
CFS 全称是 Completely Fair Scheduler,是 Linux 内核自 2.6.23 版本以来的默认调度器。CFS 调度器的核心设计目标是在真实硬件上实现理想的、精确的 CPU。所谓的“理想的 CPU”是指一个 CPU 可以在任意时刻并行地运行任意数量的 n 个任务,并且每个任务都能获得公平的 \frac 1 n 比例的CPU 资源。举例来说,有一个理想的 CPU,在 10ms 的时间内同时运行了 2 个任务 A 和 B,那么每个任务都能获得 50% 的 CPU 资源;但是真实世界中的 CPU 只能在任意时刻运行一个任务,该任务在运行期间独占 100% 的 CPU 资源,也就说 A 和 B 实际上是各自在 CPU 上运行 5ms;虽然不可能实现,但 CFS 调度器的目标就是尽可能地模拟这种理想的 CPU 行为。
要模拟理想这种理想的 CPU 行为,就要尽可能地缩减每个任务的单次运行时间,也就是时间片,时间片是指任务在被调度器抢占之前可以在 CPU 上连续运行的最长时间。时间片越小,任务被调度的频率就越高,任务切换就越频繁,CPU 资源分配就越公平,多个任务的行为就越像是并行执行,但时间片过小会导致调度开销过大 (调度器抢占任务时需要消耗 CPU 时间,同时还可能导致 CPU 缓存失效),反而降低了系统性能。因此 CFS 需要在时间片大小和调度开销之间找到一个平衡点:理想状态下为了追求调度的公平性,我们在任意时刻观测所有正在运行中的任务,每个任务到目前为止消耗的 CPU 时间应该是相同的;但这种理想状态在现实世界中是无法实现的,因为在多任务环境中,计算机无法预测每个任务的未来行为,任务的数量和状态是动态变化的,而且任务的数量通常要远超过 CPU 的核心数量,调度器无法完美地控制每个任务在任意时刻的 CPU 时间消耗总是相等的。
所以,类似于分布式理论中的"强一致性"和"最终一致性",CFS 放弃了"强公平性"的追求,而是通过某种方式来实现"最终公平性"。也就是 CFS 不保证每个任务在任意时刻的 CPU 时间消耗总是相等的,而是保证在一段时间之后,所有任务的 CPU 时间消耗总是趋近于相等。于是,CFS 舍弃了时间片的概念,转而引入了一个新的概念:虚拟运行时间 (vruntime)。vruntime 表示 virtual runtime,是一种用来记录任务已消耗 CPU 时间总量的虚拟时间,每个任务都有一个 vruntime,表示该任务在 CPU 上运行的时间;CFS 调度器算法永远倾向于选择那个具有最小 vruntime 的任务放到 CPU 上去运行。
进程权重
前面讨论的理想 CPU 的概念除了无法实现完全公平的时间片分配之外,也没有考虑到另一个至关重要的因素:任务的优先级。在现实世界中,任务肯定会有不同的优先级,理论上来说,高优先级的任务理应获得更多的 CPU 时间,而低优先级的任务则应该获得更少的 CPU 时间。
Linux 通过给每一个任务绑定一个 nice 值来表示进程的权重,nice 值和权重成反比:nice 值越高则权重越低,反之 nice 值越低则权重越高。以现实生活举例,一个人越 nice 就越愿意退让,让其他人优先,而越不 nice 的人越不愿意将自己的需求排在其他人之后。进程的 nice 值可以通过 nice(2) 系统调用来设置。
Linux 中普通进程的 nice 值范围是 [-20, 19], Linux 将 nice 值映射成了一个权重数组 sched_prio_to_weight4:
/*
* Nice levels are multiplicative, with a gentle 10% change for every
* nice level changed. I.e. when a CPU-bound task goes from nice 0 to
* nice 1, it will get ~10% less CPU time than another CPU-bound task
* that remained on nice 0.
*
* The "10% effect" is relative and cumulative: from _any_ nice level,
* if you go up 1 level, it's -10% CPU usage, if you go down 1 level
* it's +10% CPU usage. (to achieve that we use a multiplier of 1.25.
* If a task goes up by ~10% and another task goes down by ~10% then
* the relative distance between them is ~25%.)
*/
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
任务的权重值和 nice 值之间的关系可以通过公式来计算:weight = \frac{1024}{1.25^{nice}}
通过上面代码的注释可以知道,选取 1.25 作为 nice 值的底数是为了保证每次 nice 值每变化 1 时,CPU 时间的分配会有 10% 的变化。也就是说,如果一个任务的 nice 值从 0 变成 1,那么它将获得大约 10% 更少的 CPU 时间;反之,如果一个任务的 nice 值从 0 变成 -1,那么它将获得大约 10% 更多的 CPU 时间。
理论上来讲,当系统中有多个不同权重的进程时,任一个进程应该分配到的 CPU 时间应该是和它的权重成正比的,比例系数是该进程的权重除以所有可运行进程的权重之和,也就是说进程的 CPU 时间分配的计算公式如下:
有了权重值,就可以通过把当前所有运行的任务的权重值相加,然后将某一个任务的权重值除以总权重值来得到该任务的 CPU 时间分配比例。比如,现在有两个进程 A 和 B,A 的 nice 值是 -5,B 的 nice 值是 5,那么 A 的权重值是 3121,B 的权重值是 335,总权重值是 3456。A 的 CPU 时间分配比例就是 \frac{3121}{ 3456} = 0.902,B 的 CPU 时间分配比例就是 \frac {335}{3456} = 0.097。也就是说,A 将获得大约 90% 的 CPU 时间,而 B 将获得大约 10% 的 CPU 时间。如果此时系统已经运行了 100ms,那么理论上 A 应该获得 90ms 的 CPU 时间,而 B 将获得 10ms 的 CPU 时间;然而实际情况可能是 A 获得了 50ms 的 CPU 时间,而 B 同样获得了 50ms 的 CPU 时间,这说明过去的 100ms 中,A 的 CPU 时间分配比例并没有达到预期的 90% 和 10%,所以当 CFS 要选择下一个任务来运行时,就要选择 A 而不是 B,这样才能保证 A 在接下来的运行中能获得更多的 CPU 时间,从而渐进式地调整从而达到预期的 CPU 时间分配比例。
上面这种实现方式虽然直观,但是比较复杂:每次调度时都计算每个任务的权重值和总权重值的期望比例和实际比例,然后计算二者的差值,差值更大的任务需要更多的 CPU 时间,于是下次优先调度;而且 CFS 的核心理念是公平性,也就是要尽可能地保证每一个任务的 CPU 时间分配是相等的,如果引入权重值,那么就会导致不同任务之间的 CPU 时间分配不再相等,而是根据权重值来分配,这就违背了 CFS 的设计理念。但是不同任务具有不同的权重这个事是不可避免的,那么有没有一种方式可以既保证任务的优先级,又能使得调度器在调度任务的时候消除掉权重值这个因子呢?为了解决这个问题,CFS 调度器引入了 vruntime 的概念。
vruntime
vruntime 代表 virtual runtime,代表虚拟运行时间。内核会为每一个任务都分配一个 vruntime,它记录了任务截止到目前为止已消耗的 CPU 时间总量的虚拟时间,内核会及时更新这个 vruntime。之所以称之为虚拟时间,是因为这个时间并不是实际的物理时间,vruntime 的流速是基于任务的权重而定的,也就是说,任务的 vruntime 增长速度是和任务的权重成反比,权重越大,vruntime 的流速越慢,反之权重越小,vruntime 的流速越快。
在内核中,物理时间被称为 wall time,也可以称之为 runtime,进程 i 的 vruntime 和 runtime 之间的关系如下:
其中 NICE\_0\_LOAD 是内核中的一个宏,表示 nice 值为 0 时的权重值,也就是 1024。
通过这个公式可以看出,vruntime 的流速是和任务的权重成反比的,也就是说,权重越大,vruntime 增长得越慢;反之,权重越小,vruntime 增长得越快。看到这里大家应该能够明白了,vruntime 的引入就是为了消除掉权重值这个因子,或者更准确地说应该是将权重值这个因子转移到了 vruntime 上,这样就不需要在计算所有任务的 CPU 时间分配时考虑权重因子了,调度器在调度任务的时候每次都选择 vruntime 最小的那个任务来运行即可,也就是简单地维持所有任务的 vruntime 趋于相等就可以实现多任务调度的公平性了。
调度实体
前面提到,内核使用 task_struct 结构体来表示一个进程,然而 CFS 调度器却是使用 sched_entity 结构体来表示一个最小的调度单位,称之为调度实体 (scheduling entity),也就是一个可以被调度的任务。sched_entity 封装了调度时所需的各种信息:权重、vruntime 等,每个 task_struct 都包含一个 sched_entity,用于记录该任务的调度信息。
简化后的 task_struct 结构体如下所示5:
struct task_struct {
/* ... */
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;
const struct sched_class *sched_class;
}
正如上文所述,task_struct 表示进程,但是调度类实际管理和调度的基本单位却是 sched_entity,其基本属性如下6:
struct sched_entity {
/* For load-balancing: */
struct load_weight load; // 任务的权重值,由 nice 值计算得出
struct rb_node run_node; // 调度实体在红黑树中的节点
struct list_head group_node; // 组调度
unsigned int on_rq; // 任务是否在运行队列中
u64 exec_start; // 本次调度的起始时间戳,用于后面计算该任务本次调度运行的 CPU 时间
u64 sum_exec_runtime; // 任务到目前为止总计消耗的 CPU 时间
u64 vruntime; // 任务的虚拟运行时间,通过实际 CPU 时间乘上权重系数计算得出
u64 prev_sum_exec_runtime; // 上次调度时统计的任务总计消耗的 CPU 时间,抢占调度时会用到
u64 nr_migrations; // 任务在 CPU 间迁移的次数
struct cfs_rq *cfs_rq; // 任务所在的 CFS 运行队列
/* ... */
};
调度延迟
CFS 调度器不仅需要保证 CPU 时间分配的公平,还要保证每个任务都能够周期性地执行。在一个 CPU 上,所有可运行的任务都至少运行一次所需的时间周期就是调度延迟 (scheduling latency)。比如现在有 10 个可运行的进程,每个进程都运行 10ms,那么调度延迟就是 100ms。
回顾一下前面描述的 CFS 调度器是如何模拟理想的 CPU 行为的:尽可能缩减每个任务的单次运行时间,那么多个任务就可以被更频繁地调度到,每个任务的交互性就更好,系统也就更接近一个理想的多任务环境。同理,调度延迟越小,每个任务的单次运行时间 (时间片) 也就越小,任务被调度的频率就越高,系统的交互性就越好,任务调度就越公平。比如我们把前面的例子中的调度延迟从 100ms 缩减到 10ms,那么第一个任务在被调度之后,下一次被调度到的延迟也就缩短成了 10ms,每个任务平均分配到的 CPU 时间也从 10ms 降低到 1ms,也就是这个任务能够更快地被调度到 CPU 上去运行了,交互性大大提升了。然而,当系统中的可运行任务数量越来越多,每个任务的时间片也会越来越小,当可运行任务的数量趋于无限大时,时间片就会无限趋近于 0,这会导致调度器更加频繁地进行上下文切换,占用大量的 CPU 时间,系统开销飙升,降低系统性能。
因此,CFS 调度器不能使用固定的调度延迟,而是需要根据当前系统中可运行的任务数量动态调整调度延迟。调度延迟通过函数 __sched_period() 计算得出7:
/*
* The idea is to set a period in which each task runs once.
*
* When there are too many tasks (sched_nr_latency) we have to stretch
* this period because otherwise the slices get too small.
*
* p = (nr <= nl) ? l : l*nr/nl
*/
static u64 __sched_period(unsigned long nr_running)
{
if (unlikely(nr_running > sched_nr_latency))
return nr_running * sysctl_sched_min_granularity;
else
return sysctl_sched_latency;
}
这个函数通过一个名为 sched_nr_latency 的参数来控制调度延迟,这个参数表示系统中可运行的任务数量阀值,当可运行任务的数量不大过这个值时 (默认值 8),调度延迟就是一个固定值 sysctl_sched_latency (默认值 6ms)。而当可运行任务的数量超过这个阀值时,内核则为每一个任务设定一个最小 CPU 时间 sysctl_sched_min_granularity (默认值 0.75ms),承诺每个任务在 CPU 上会至少运行这个时间之后才会被抢占。这样一来,即便是可运行的任务趋于无限大,也能够保证每个任务的 CPU 时间片不会无限趋近于 0,而是至少有一个最小值,将上下文切换的频率控制在一个可接受的范围内。换句话说,调度延迟越小,CFS 就越公平,现在强制设定了一个最小的时间分片,也就是说 CFS 就不能做到完全公平了,不过 CFS 会为每个 CPU 都维护一个 runqueue (运行队列),当 runqueue 中的可运行任务数量不太多的时候,CFS 通常可以被认为是完全公平的。
引入 vruntime 之后,CFS 调度器就可以摒弃时间片 (timeslice) 的概念了,更准确地说,CFS 摒弃了固定时间片的概念,也就是说 CFS 并不会预先给每个任务分配一个固定的时间片,而是根据当前所有可运行的任务数量 n 来动态计算,平均分配给每一个任务 \frac 1 n 的 CPU 资源,任务的权重值也要考虑在内。可通过如下公式动态计算每个任务的时间片:
其中,sched_latency 是 CFS 调度器的一个参数,表示调度器的调度延迟,也就是所有可运行的任务都至少运行一次所需的时间。计算一个任务在调度延迟内的时间片时,首先需要计算所有可运行任务的权重值之和,然后将该任务的权重值除以总权重值,得到该任务在调度延迟内的 CPU 时间分配比例,最后将这个比例乘以调度延迟就得到了该任务的时间片。
内核中的具体实现如下8:
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
unsigned int nr_running = cfs_rq->nr_running;
struct sched_entity *init_se = se;
unsigned int min_gran;
u64 slice;
if (sched_feat(ALT_PERIOD))
nr_running = rq_of(cfs_rq)->cfs.h_nr_running;
// 动态计算当前的调度延迟
slice = __sched_period(nr_running + !se->on_rq);
// 如果是组调度,也就是涉及到进程组的调度,这里的循环会遍历任务组里的所有调度实体,
// 但是目前我们不考虑组调度,所以这里的循环只会执行一次。
for_each_sched_entity(se) {
struct load_weight *load;
struct load_weight lw;
struct cfs_rq *qcfs_rq;
qcfs_rq = cfs_rq_of(se);
// 获取当前调度实体所在的运行队列的总负载,也就是所有可运行任务的权重之和
load = &qcfs_rq->load;
if (unlikely(!se->on_rq)) {
lw = qcfs_rq->load;
update_load_add(&lw, se->load.weight);
load = &lw;
}
// 加权计算出当前调度实体在调度延迟内分配到的时间片,se->load.weight 是当前调度实体的权重值,
// load 是当前运行队列的总负载,也就是所有可运行任务的权重之和,具体计算方式就是上面
// 提到的 timeslice_k = (weight_k / \Sum weight_i) * sched_latency
slice = __calc_delta(slice, se->load.weight, load);
}
if (sched_feat(BASE_SLICE)) {
if (se_is_idle(init_se) && !sched_idle_cfs_rq(cfs_rq))
min_gran = sysctl_sched_idle_min_granularity;
else
min_gran = sysctl_sched_min_granularity;
slice = max_t(u64, slice, min_gran);
}
return slice;
}
runqueue
CFS 调度器使用一个名为 runqueue (运行队列) 的数据结构来维护所有可运行的任务。每个 CPU 都有一个独立的 runqueue,runqueue 中包含了所有在该 CPU 上可运行的任务。CFS 调度器使用每个任务的 vruntime 作为 key 构建和维护一棵基于时序 (time-ordered) 的红黑树 (red-black tree),红黑树的每个节点都是一个调度实体 (sched_entity),表示一个可运行的任务。为什么选择红黑树呢?因为内核需要一个高效的数据结构来保存并操作所有的可运行任务,CFS 不仅要快速地从 runqueue 中找到下一个可调度的任务,还需要频繁地插入、更新和删除 runqueue 中的任务,因此红黑树是一个理想的选择,它是一种自平衡的二叉搜索树,其性质保证了调度器可以在 O(\log_2 n) 的时间复杂度内查找、插入和删除任务。而 Linux 更进一步对 CFS 所使用的红黑树进行了优化,缓存了最小的 vruntime 节点,使得调度器取回最小 vruntime 的任务的时间复杂度降为 O(1)。
红黑树在很多编程语言中有着广泛的应用:
- 在 C++ STL 中,红黑树被用作
std::map和std::set的底层实现。 - 在 Java 中,
TreeMap和TreeSet都是基于红黑树实现的。 - 在 Python 中,
SortedDict和SortedSet也使用了红黑树。
在 Linux 内核中,红黑树也有着非常广泛的应用,除了 CFS 调度器的 runqueue 之外,I/O 调度器中的 Deadline Scheduler 和 CFQ Scheduler 也使用了红黑树来维护 I/O 请求的优先级和顺序。还有虚拟内存中的 VMAs (Virtual Memory Areas) 也使用了红黑树来维护内存映射的区域。I/O 多路复用技术 epoll 使用了红黑树来管理所有的文件描述符和监听的事件。还有内核中的高精度定时器 (timer) 也使用了红黑树来组织和管理所有的定时器请求9。
关于红黑树的具体原理和实现这里不再赘述,读者可以参考这份资料和相关资料进行更深入的学习。
CFS 调度器的 runqueue 中的红黑树的每个节点都包含了一个调度实体 (sched_entity),表示一个可运行的任务,其中包含了该任务的 vruntime、权重等信息。CFS 通过以 vruntime 为 key 将这些调度实体组织起来,形成一颗基于时序的红黑树:

runqueue 是一个 rq 的数据结构,rq 里会有对应不同的调度算法的具体 runqueue 实现,CFS 调度器的话就是一个 cfs_rq 结构体,这个结构体比较大,精简之后留下一些和本文相关的字段如下10:
struct rq {
/* ... */
struct cfs_rq cfs; /* CFS 调度器的运行队列 */
struct rt_rq rt; /* Real time 调度器的运行队列 */
struct dl_rq dl; /* Deadline 调度器的运行队列 */
/* ... */
}
/* CFS-related fields in a runqueue */
struct cfs_rq {
struct load_weight load; /* 整个 runqueue 中所有可运行任务的权重之和 */
unsigned int nr_running; /* 当前可运行任务的数量 */
u64 exec_clock; /* 当前运行队列的时钟,记录 runqueue 到目前为止的总运行时间 */
u64 min_vruntime; /* 当前运行队列中最小的 vruntime */
// 这是一个缓存数据,其中保存了进程红黑树的根节点和最左子节点
struct rb_root_cached tasks_timeline;
/*
* 'curr' points to currently running entity on this cfs_rq.
* It is set to NULL otherwise (i.e when none are currently running).
*/
struct sched_entity *curr; /* 当前正在运行的调度实体 */
struct sched_entity *next; /* 下一个应该运行的调度实体 */
struct sched_entity *last; /* 刚被调度过的调度实体 */
struct sched_entity *skip; /* 已跳过的调度实体 */
};
首先我们看一下 min_vruntime 字段,这是一个单调递增的变量,记录了当前 runqueue 中所有进程的最小 vruntime,所有新创建的、长时间休眠的的进程被添加到这个 runqueue 时,进程的 sched_entity.vruntime 字段都会基于 min_vruntime 来初始化。这么做的目的是为了防止新进程长时间霸占 CPU 的问题,因为新创建的进程的 vruntime 理论上来说应该是 0,而长时间休眠的进程的 vruntime 也会落后当前的 runqueue 很多,这样就会导致新进程和长时间休眠的进程的 vruntime 都很小,调度器会优先选择它们来运行,从而导致其他进程被饿死。调度器会结合当前正在运行的进程 vruntime 和 min_vruntime 初始化新进程的 vruntime,手动拨动它们的时钟,使得它们的 vruntime 跟上当前 runqueue 的进度,有效缓解了这个问题。
接下来我们看一下 tasks_timeline 字段,这就是保存了所有进程的时序红黑树,这个结构体很简单11:
/*
* Leftmost-cached rbtrees.
*
* We do not cache the rightmost node based on footprint
* size vs number of potential users that could benefit
* from O(1) rb_last(). Just not worth it, users that want
* this feature can always implement the logic explicitly.
* Furthermore, users that want to cache both pointers may
* find it a bit asymmetric, but that's ok.
*/
struct rb_root_cached {
struct rb_root rb_root;
struct rb_node *rb_leftmost;
};
rb_root 是红黑树的根节点,rb_leftmost 是红黑树的最左子节点,这是一个缓存数据,用来加速查找最小 vruntime 的任务,使得 CFS 查找最小 vruntime 的任务的时间复杂度从 O(\log_2 n) 下降到 O(1)。CFS 调度器会在每次调度时都调整这棵红黑树,插入、删除和更新调度实体 (sched_entity) 的 vruntime,然后更新 rb_leftmost 指针。
调度原理
宏观层面来说,CFS 调度器的工作流程可以简单地概括为:
- CFS 从 runqueue 中取出 vruntime 最小的进程放到 CPU 上运行,期间会一直加权增长进程的 vruntime;
- 不断更新 runqueue 中各个进程的 vruntime 并根据 vruntime 的值不断调整红黑树以保持其有序性;
- 当正在运行的进程的 vruntime 不断增长,最终超过了其他进程的 vruntime,于是红黑树的最左子节点就会易主,换成另一个 vruntime 更小的进程 (同时也是 runqueue 中的最小 vruntime);
- 此时 CFS 不会立刻抢占当前正在运行的进程,而是会允许进程进行一小段惯性滑行,也就是让进程继续使用一点 CPU 时间 (当前进程在红黑树的位置也会不断右移),直到它的 vruntime 超过新的最左子节点的 vruntime 一定的数值;
- 然后 CFS 就会抢占正在运行的进程,将目前红黑树的最左子节点上的进程调度到 CPU 上去运行;
- 重复上述步骤,直到所有进程都被调度完毕。
调度节拍
时钟中断 (timer interrupt) 是一种由硬件提供的、周期性触发的硬中断,操作系统可以利用时钟中断来做很多事情,比如更新系统时间、刷新屏幕、数据落盘等。操作系统都有一个系统定时器,由硬件 (可编程定时芯片) 提供支持,系统定时器以某种频率周期性发出电子脉冲,触发硬件中断,这就是时钟中断。系统定时器的频率是可编程的,称之为节拍率 (tick rate),两次时钟中断的时间间隔则被称之为节拍 (tick), tick=\frac{1}{tick\_rate}秒。
系统定时器的节拍率的单位是 HZ,表示每秒钟触发的时钟中断次数。节拍率是通过静态预处理定义的,内核启动的时候会按照 HZ 值对硬件进行设置,HZ 默认值在不同的 CPU 架构和内核版本中也是不一样的。以 x86(_64) 架构为例,内核版本 2.4.x 的默认值是 100,tick 就是 10ms,2.6.0 之后提高到 1000,tick 变成了 1ms,2.6.13 之后默认值又降为 250,tick 就是 4ms,同时也支持了手动配置这个参数12。内核有一个全局的 jiffies 计数器,用记录自系统启动以来的总节拍数,初始值是 0,此后每次发生时钟中断时就会加 1。因为一秒钟内时钟中断的次数等于 HZ,因此 jiffies 每秒钟的增值就是 HZ。
我们前文介绍的 vruntime 是一种虚拟时间,如果不借助任何外力的话它是不会自动增长的。vruntime 的基础是物理时间 (wall time),系统时间对于内核空间和用户空间来都是至关重要的,而内核计算物理时间就是通过时钟中断来实现的,所以,CFS 调度器需要依赖时钟中断来不断地更新 vruntime。此外,调度器也需要利用时钟中断来完成任务调度的其他工作,比如更新任务的状态、重新计算任务的优先级等。CFS 的本质其实就是尽全力维持系统中所有可运行进程的 vruntime 趋于相等,所以每次调度的时候都要选择 vruntime 最小的进程来运行,由于 vruntime 的计算已经进行了加权,将权重因子纳入了计算,所以我们可以说 CFS 是一种公平性调度。
时钟中断,顾名思义是一种中断机制,而计算机一旦触发硬件中断,则会发送中断信号到内核,内核就必然要运行相应的中断处理程序来处理这个中断信号,中断处理程序会调用内核的 tick_handle_periodic() 函数,其中又会调用 tick_periodic() 函数13:
static void tick_periodic(int cpu)
{
if (tick_do_timer_cpu == cpu) {
raw_spin_lock(&jiffies_lock);
write_seqcount_begin(&jiffies_seq);
// 记录下一个节拍事件
tick_next_period = ktime_add_ns(tick_next_period, TICK_NSEC);
// 更新系统的 jiffies 计算系统的平均负载的统计值
do_timer(1);
write_seqcount_end(&jiffies_seq);
raw_spin_unlock(&jiffies_lock);
// 更新系统物理时间 wall time
update_wall_time();
}
// 更新当前进程已使用的 CPU 时间,也就是加上一个 tick,
// 此外,还会更新调度实体的 vruntime,以及其他调度信息
update_process_times(user_mode(get_irq_regs()));
profile_tick(CPU_PROFILING);
}
这里我们重点关注 update_process_times() 函数14:
void update_process_times(int user_tick)
{
struct task_struct *p = current;
// 实质性地更新当前进程已消耗的 CPU 时间
account_process_tick(p, user_tick);
run_local_timers();
rcu_sched_clock_irq(user_tick);
#ifdef CONFIG_IRQ_WORK
if (in_irq())
irq_work_tick();
#endif
// 周期性调度的入口函数,更新调度实体的 vruntime 和其他调度信息
scheduler_tick();
if (IS_ENABLED(CONFIG_POSIX_TIMERS))
run_posix_cpu_timers();
}
account_process_tick() 函数会把整个节拍时间都算给当前进程,然而事实上进程在上一个节拍周期内不一定占用了全部的时间,比如进程曾经多次在内核态和用户态切换,而且当时也未必只有一个进程在运行。可惜的是,在 Linux 和其他类 UNIX 系统中这已经是最精确的时间统计粒度了,目前还没有更精密的统计算法的支持,所以只能做到这个程度。所以内核也开放了 HZ 的配置,让有需求的用户可以使用更高的 HZ 值,也就是使用更低的节拍时间,尽量弥补当前统计算法的精度丢失。
scheduler_tick() 是 CFS 调度器进行周期性调度的入口函数,主要工作就是更新调度实体的 vruntime 和其他调度信息。它会遍历当前 CPU 上正在运行的任务,更新任务的 vruntime,然后内核会根据 vruntime 的最新值重新调整红黑树,以保持其有序性15。
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu); // 获取当前 CPU 的运行队列
struct task_struct *curr = rq->curr; // 获取当前正在运行的任务
struct rq_flags rf;
unsigned long thermal_pressure;
u64 resched_latency;
if (housekeeping_cpu(cpu, HK_TYPE_TICK))
arch_scale_freq_tick();
sched_clock_tick();
rq_lock(rq, &rf);
update_rq_clock(rq); // 更新 runqueue 的时钟等调度信息
thermal_pressure = arch_scale_thermal_pressure(cpu_of(rq));
update_thermal_load_avg(rq_clock_thermal(rq), rq, thermal_pressure);
// 更新当前正在运行的任务的 vruntime 和其他调度信息
curr->sched_class->task_tick(rq, curr, 0);
/* ... */
}
这里的 curr->sched_class 就是一个调度类,我们讨论的是 CFS 调度器,所以调度类的实例就是 fair_sched_class,它的成员函数 task_tick() 就是 task_tick_fair()16 17 18:
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se; // 获取当前进程的调度实体
// 不考虑组调度的话,这个循环只会执行一次,只处理当前进程
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se); // 获取当前调度实体所在的 CFS runqueue
entity_tick(cfs_rq, se, queued); // 更新调度实体的 vruntime 和其他调度信息,执行抢占逻辑
}
/* ... */
}
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq);
/* ... */
if (cfs_rq->nr_running > 1)
check_preempt_tick(cfs_rq, curr); // 检查是否需要抢占当前任务
}
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr; // 获取当前的调度实体
u64 now = rq_clock_task(rq_of(cfs_rq)); // 获取当前时间戳
u64 delta_exec;
if (unlikely(!curr))
return;
// 计算当前任务自上次调度以来的(物理)时间差
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
curr->exec_start = now; // 更新本次调度的起始时间戳
/* ... */
// 更新当前任务的总执行时间和调度时钟
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq->exec_clock, delta_exec);
// 更新当前任务的 vruntime,calc_delta_fair 函数通过加权运算将物理时间差转化为虚拟时间差,
// 具体是调用 __calc_delta() 函数来计算,方程是 delta_exec * NICE_0_LOAD / weight
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq); // 更新当前 runqueue 的最小 vruntime
/* ... */
}
调度抢占
抢占是指调度器强行中断当前正在运行的任务,切换上下文,换上另一个任务到 CPU 上执行。抢占是调度器实现多任务调度的核心手段,也是实现公平性调度的关键。抢占的时机通常是在以下几种情况下:
- 当前任务的 CPU 时间片用完了
- 有更高优先级的进程需要运行
- 任务阻塞,比如等待 I/O 事件、加锁或者等待系统信号等
- 从系统调用或者中断返回到用户态时
- ...
具体实现在 check_preempt_tick() 函数中19:
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
// 计算出当前任务在一次调度延迟内理论上的时间片,当系统的可运行任务数量太多时,
// 可能会导致算出来的时间片超过调度延迟,这里就强制将时间片限制在调度延迟内。
ideal_runtime = min_t(u64, sched_slice(cfs_rq, curr), sysctl_sched_latency);
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
// 如果当前任务实际消耗的 CPU 时间已经超过了它应得的时间片,则抢占当前任务
if (delta_exec > ideal_runtime) {
resched_curr(rq_of(cfs_rq));
/*
* The current task ran long enough, ensure it doesn't get
* re-elected due to buddy favours.
*/
clear_buddies(cfs_rq, curr);
return;
}
// 如果当前任务实际消耗的 CPU 时间小于最小时间片,则不抢占,避免过于频繁的上下文切换
if (delta_exec < sysctl_sched_min_granularity)
return;
// 取出 runqueue 的红黑树的最左子节点,即 vruntime 最小的调度实体,
// 然后和当前任务的 vruntime 进行比较,计算差值。
se = __pick_first_entity(cfs_rq);
delta = curr->vruntime - se->vruntime;
// 如果当前任务的 vruntime 依旧是最小的,则不需要抢占
if (delta < 0)
return;
// 如果当前任务的 vruntime 超过了红黑树最左子节点的 vruntime 一个时间片,则抢占当前任务
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));
}
调度入口
需要注意的是,resched_curr() 函数只是给当前任务打上一个 TIF_NEED_RESCHED 标记,并不会立即抢占当前任务,而是在进程从中断或者系统调用返回到用户态空间时,检查当前进程的调度标志,如果标记被设置了,则会调用 schedule() 函数进行抢占,重新选择 vruntime 最小的任务来运行。schedule() 是内核调度器的入口,内核中很多地方都会有这个函数的埋点,所以在内核运行期间,调度器代码一直在执行。这个函数的代码精简后如下20 21:
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
preempt_disable(); // 关闭内核抢占
__schedule(SM_NONE); // 执行具体的调度工作
sched_preempt_enable_no_resched(); // 重新开启内核抢占
} while (need_resched()); // 检查是否有 TIF_NEED_RESCHED 标志
sched_update_worker(tsk);
}
static void __sched notrace __schedule(unsigned int sched_mode)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
unsigned long prev_state;
struct rq_flags rf;
struct rq *rq;
int cpu;
cpu = smp_processor_id(); // 获取当前 CPU 的 ID
rq = cpu_rq(cpu); // 获取当前 CPU 的运行队列
prev = rq->curr; // 获取当前正在运行的任务
rq_lock(rq, &rf); // 调度前先锁 runqueue,防止可能发生的任务迁移
smp_mb__after_spinlock();
/* Promote REQ to ACT */
rq->clock_update_flags <<= 1;
update_rq_clock(rq); // 更新 runqueue 的时钟
switch_count = &prev->nivcsw;
prev_state = READ_ONCE(prev->__state);
if (!(sched_mode & SM_MASK_PREEMPT) && prev_state) {
if (signal_pending_state(prev_state, prev)) {
WRITE_ONCE(prev->__state, TASK_RUNNING);
} else {
/* ... */
// sched_mode & SM_MASK_PREEMPT 是 false 说明这次调度不是由于任务被调度器抢占,
// 而是因为任务主动让出 CPU,通常是因为 I/O 操作,所以先将这类任务从 runqueue 中暂时移除,
// 这个函数最终会使用具体调度类的 `dequeue_task()` 方法完成工作
deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK);
// 任务正等待 I/O 事件,将 runqueue 的 I/O 等待计数器加一
if (prev->in_iowait) {
atomic_inc(&rq->nr_iowait);
delayacct_blkio_start();
}
}
switch_count = &prev->nvcsw;
}
// 从 runqueue 中挑选出下一个最有资格被调度运行的任务,最终会调用具体调度类的 `pick_next_task()` 方法,
// 对于 CFS 调度类来说,就是从 cfs_rq 的红黑树中找出 vruntime 最小的调度实体。
next = pick_next_task(rq, prev, &rf);
clear_tsk_need_resched(prev); // 当前任务已被抢占,清除当前任务的 TIF_NEED_RESCHED 标记
clear_preempt_need_resched();
if (likely(prev != next)) { // 确保当前任务和下一个有资格运行的任务不是同一个
rq->nr_switches++; // 更新 runqueue 的上下文切换计数器
++*switch_count;
/* ... */
// 执行上下文切换,从 prev 进程切换到 next 进程,同时解锁 runqueue
rq = context_switch(rq, prev, next, &rf);
} else {
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
// 如果 prev == next,说明当前 cfs_rq 中的 vruntime 最小的调度实体还是当前进程,
// 则不切换上下文并解锁 runqueue
rq_unpin_lock(rq, &rf);
__balance_callbacks(rq);
raw_spin_rq_unlock_irq(rq);
}
}
schedule() 结构比较简单,主要就是一个循环,循环条件是 need_resched(),检查当前任务是否需要被抢占,也就是检查进程上是否有 TIF_NEED_RESCHED 标记,如果有的话就进行调度抢占,从 runqueue 中选择下一个最有资格运行的任务抢占当前任务,执行上下切换,也就是切换进程的地址空间和 CPU 寄存器等信息。need_resched() 每次都会检查 __schedule() 选出来的最新进程是否有 TIF_NEED_RESCHED 标记,如果有的话循环体就会一直循环重复执行调度逻辑,直至没有需要抢占的任务为止。
pick_next_task() 最终会走到 __pick_next_task() 函数,我们前面介绍过它,现在来看看这个函数的完整代码22:
static inline struct task_struct *
__pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in the fair class we can
* call that function directly, but only if the @prev task wasn't of a
* higher scheduling class, because otherwise those lose the
* opportunity to pull in more work from other CPUs.
*/
if (likely(!sched_class_above(prev->sched_class, &fair_sched_class) &&
rq->nr_running == rq->cfs.h_nr_running)) {
p = pick_next_task_fair(rq, prev, rf);
if (unlikely(p == RETRY_TASK))
goto restart;
/* Assume the next prioritized class is idle_sched_class */
if (!p) {
put_prev_task(rq, prev);
p = pick_next_task_idle(rq);
}
return p;
}
restart:
put_prev_task_balance(rq, prev, rf);
for_each_class(class) {
p = class->pick_next_task(rq);
if (p)
return p;
}
BUG(); /* The idle class should always have a runnable task. */
}
这个函数我们前面已经介绍过了,这里我们重点看一下代码里遍历所有调度类之前的那部分吧。那部分是一个优化路径,可以看到那里有一大片注释,意思是说如果当前 CPU 的 runqueue 中所有任务都是 CFS 调度类的任务,并且当前要被抢占的任务所属的调度类的优先级不比 CFS 更高的话,就可以直接调用 CFS 的 pick_next_task_fair() 函数来选择下一个任务,而不需要遍历所有调度类并执行它们的 pick_next_task() 方法了。
为什么内核要求当前要被抢占的任务所属的调度类的优先级不比 CFS 更高时才考虑进入优化路径呢?注释里说如果不是这样的话就会失去从其他 CPU 上拉取更多任务的机会。我的理解是,如果当前在运行的任务是一个实时任务而剩下的可运行任务都是 CFS 调度类的任务,那么这个实时任务就是当前 CPU 的 runqueue 中唯一一个实时任务,如果直接进入优化路径从 CFS 调度类的红黑树中选择下一个任务抢占掉这个实时任务之后,下一次的调度选择下一个任务时又会直接进入优化路径,也就是后面会一直选择 CFS 调度类的任务来运行,调度器可能就没有机会执行后面的代码对当前系统中的任务进行负载均衡:将任务在 CPU 之间进行迁移并遍历所有调度类执行 pick_next_task() 方法挑选合适的任务来运行,对于当前 CPU 来说就是没机会从其他 CPU 取任务过来运行了。
这个优化路径是基于这样一个事实:大部分人都是使用 Linux 作为一个分时系统而非实时系统,这种情况下系统中绝大部分任务都是 CFS 调度器管理的,也就是说系统中优先级最高的调度类就是 CFS 调度类,所以可以使用 likely 编译器指令来优化 CPU 流水线的分支预测功能,提高调度器的性能。
调度初始化
前面是直接从已存在的进程开始分析调度器的工作流程,而进程的创建和休眠唤醒也是调度器工作中重要的组成部分。我们都知道类 UNIX 系统中的进程创建是通过 fork() 来完成的,Linux 内核中的 fork(2) 系统调用的主要代码逻辑在 kernel_clone() 函数中,它又会调用 copy_process() 来创建一个新的进程副本,内核使用 CoW (Copy on Write 写时复制) 技术:子进程不再复制数据其父进程的数据,而只是复制它的页表,那么 fork() 之后父子进程的虚拟地址空间就会指向相同的物理地址,因为进程彼此的虚拟地址空间和页表是私有的,因此这种操作是允许的,于是子进程的所有读操作访问的数据在内存中就只有一份,父子进程共享,只有当子进程进行写操作的时候才会分配新的内存页。紧接着,再调用 wake_up_new_task() 函数唤醒这个新创建的进程,做一些调度器所需的初始化工作,最后把进程插入到 CPU 的 runqueue 中然后唤醒它来运行23:
pid_t kernel_clone(struct kernel_clone_args *args)
{
u64 clone_flags = args->flags;
struct completion vfork;
struct pid *pid;
struct task_struct *p;
int trace = 0;
pid_t nr;
/* ... */
p = copy_process(NULL, trace, NUMA_NO_NODE, args);
/* ... */
wake_up_new_task(p);
/* ... */
return nr;
}
copy_process() 里和调度器相关的函数主要是 sched_fork() 和 sched_cgroup_fork(),前者的功能主要是初始化新进程的一些基础的调度信息 (虚拟时间、权重等) 和调度类,CFS 调度器的话调度类就是 fair_sched_class,后者会调用调度类的 task_fork() 方法,主要是为进程的调度实体计算 vruntime 和绑定到当前 CPU 的 runqueue。
static void __sched_fork(unsigned long clone_flags, struct task_struct *p)
{
p->on_rq = 0;
p->se.on_rq = 0;
p->se.exec_start = 0;
p->se.sum_exec_runtime = 0;
p->se.prev_sum_exec_runtime = 0;
p->se.nr_migrations = 0;
p->se.vruntime = 0;
/* ... */
}
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
__sched_fork(clone_flags, p);
/*
* We mark the process as NEW here. This guarantees that
* nobody will actually run it, and a signal or other external
* event cannot wake it up and insert it on the runqueue either.
*/
p->__state = TASK_NEW;
/*
* Make sure we do not leak PI boosting priority to the child.
*/
p->prio = current->normal_prio;
uclamp_fork(p);
/*
* Revert to default priority/policy on fork if requested.
*/
if (unlikely(p->sched_reset_on_fork)) {
if (task_has_dl_policy(p) || task_has_rt_policy(p)) {
// 设置调度策略等信息
p->policy = SCHED_NORMAL;
p->static_prio = NICE_TO_PRIO(0);
p->rt_priority = 0;
} else if (PRIO_TO_NICE(p->static_prio) < 0)
p->static_prio = NICE_TO_PRIO(0);
p->prio = p->normal_prio = p->static_prio;
set_load_weight(p, false); // 设置进程的权重值
/*
* We don't need the reset flag anymore after the fork. It has
* fulfilled its duty:
*/
p->sched_reset_on_fork = 0;
}
if (dl_prio(p->prio))
return -EAGAIN;
else if (rt_prio(p->prio))
p->sched_class = &rt_sched_class;
else
p->sched_class = &fair_sched_class; // 设置 CFS 调度类
/* ... */
}
接下来是 sched_cgroup_fork(),cgroup 是内核的资源限制技术,主要用于对进程进行资源管理和限制,是当下容器技术的基础,这里我们不涉及这方面的内容,所以 cgroup 可以忽略,只看核心代码逻辑,如下26:
void sched_cgroup_fork(struct task_struct *p, struct kernel_clone_args *kargs)
{
unsigned long flags;
/* ... */
rseq_migrate(p);
/*
* We're setting the CPU for the first time, we don't migrate,
* so use __set_task_cpu().
*/
__set_task_cpu(p, smp_processor_id());
// 这里是 CFS 调度器,所以 task_fork() 就是 task_fork_fair(),
// 该方法会完成新进程所需的调度信息的初始化工作,包括设置 vruntime 和
// runqueue 绑定。
if (p->sched_class->task_fork)
p->sched_class->task_fork(p);
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
}
task_fork() 是调度类定义的标准方法,不同的调度类会有不同的实现,CFS 调度类的实现就是 task_fork_fair(),它的主要工作是:
- 调用
update_curr()更新当前运行队列的调度实体的 vruntime。这个函数前面已经介绍过,是调度器的核心函数之一,内核会在很多地方调用它来更新任务的 vruntime:新进程入队、休眠进程出队、还有调度器处理系统中断时等场景;紧接着初始化新进程的调度实体sched_entity的 vruntime:新进程的 vruntime 会被初始化为当前运行队列中正在运行的任务的 vruntime,这样可以保证新进程在调度时不会因为其 vruntime 太小而占用过多的 CPU 时间。 - 调用
place_entity()调整新进程或者被唤醒进程的 vruntime,主要是执行奖惩机制:对于新进程要进行惩罚,将其 vruntime 加上一个加权计算得出的时间片,否则的话新进程的 vruntime 过小会导致长时间占用 CPU,对于其他进程来说不公平;对于被唤醒进程则要进行奖励,因为之前该进程已经休眠过一段时间了 (主动休眠或者等待 I/O 事件被阻塞了),那就相当于被惩罚了,将它从休眠中唤醒说明他已经准备好恢复运行了,比如等待的 I/O 事件来了,或者主动唤醒了,那么就要将它的 vruntime 减小一些,使得进程可以更早地被调度到 CPU 上去运行。 - 最后将进程的 vruntime 减去
cfs_rq->min_vruntime,也就是当前 CFS runqueue 的最小 vruntime。 此举是因为当前这个新进程或者被唤醒进程还没有被调度器真正地插入到某个 CPU 的 runqueue 中,未来调度器会决定将这个任务调度到某个 CPU 上去运行,最终的选择不一定是当前 CPU,彼时这个新进程的 vruntime 可能会加上其所在 CPU 的cfs_rq->min_vruntime,所以这里先减 vruntime 的值,相当于提前做一下对冲。
源码实现如下27:
static void task_fork_fair(struct task_struct *p)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se, *curr;
struct rq *rq = this_rq();
struct rq_flags rf;
rq_lock(rq, &rf);
update_rq_clock(rq);
cfs_rq = task_cfs_rq(current); // 获取当前任务所在的 CFS runqueue
curr = cfs_rq->curr; // 获取当前调度实体
if (curr) {
update_curr(cfs_rq); // 更新当前调度实体的 vruntime
se->vruntime = curr->vruntime; // 然后将新进程的 vruntime 初始化为当前调度实体的 vruntime
}
// 对新进程进行惩罚,也就是增加其 vruntime
place_entity(cfs_rq, se, 1);
if (sysctl_sched_child_runs_first && curr && entity_before(curr, se)) {
/*
* Upon rescheduling, sched_class::put_prev_task() will place
* 'current' within the tree based on its new key value.
*/
swap(curr->vruntime, se->vruntime);
resched_curr(rq);
}
se->vruntime -= cfs_rq->min_vruntime;
rq_unlock(rq, &rf);
}
接下来我们来看看 place_entity() 函数28:
static u64 sched_vslice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
return calc_delta_fair(sched_slice(cfs_rq, se), se);
}
static inline u64 max_vruntime(u64 max_vruntime, u64 vruntime)
{
s64 delta = (s64)(vruntime - max_vruntime);
if (delta > 0)
max_vruntime = vruntime;
return max_vruntime;
}
static void
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
// 获取当前 CFS runqueue 的最小 vruntime,下面以此为基础进行增减
u64 vruntime = cfs_rq->min_vruntime;
// initial == 1 表示是新创建的进程,进行惩罚,增加 vruntime,
// sched_vslice() 函数会调用 sched_slice() 先加权计算出
// 该调度实体应得的现实时间片,然后转化为虚拟时间片
if (initial && sched_feat(START_DEBIT))
vruntime += sched_vslice(cfs_rq, se);
// initial == 0 表示是被唤醒的进程,则进行奖励,减小其 vruntime
if (!initial) {
unsigned long thresh; // vruntime 将要减去的值
if (se_is_idle(se))
// 如果是空闲进程,则使用最小时间片 0.75ms
thresh = sysctl_sched_min_granularity;
else
// 不是空闲进程,则使用一整个调度延迟的时间
thresh = sysctl_sched_latency;
/*
* Halve their sleep time's effect, to allow
* for a gentler effect of sleepers:
*/
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
// vruntime 减去 thresh 值,奖励被唤醒的进程
vruntime -= thresh;
}
// 原先这里是直接执行 max_vruntime() 函数,使用调度实体的 vruntime 减去
// min_vruntime 判断大小,取其中更大的那个值作为调度实体的最终 vruntime。
// 之所以要这么做,是因为每次进程被唤醒时都会调用 place_entity() 函数,
// 然后执行 vruntime -= thresh,也就是调度实体的 vruntime 一直减少最终发生倒退,
// 而 vruntime 是必须要递增的,所以用 max_vruntime() 函数来保证 vruntime 不会倒退。
if (entity_is_long_sleeper(se))
// 如果进程从一个长时间休中被唤醒,其 vruntime 可能会非常小,导致 vruntime - min_vruntime
// 的结果会溢出 int64,所以这里就不执行 max_vruntime() 了,直接将已经减少过的 min_vruntime
// 作为该调度实的 vruntime
se->vruntime = vruntime;
else
se->vruntime = max_vruntime(se->vruntime, vruntime);
}
copy_process() 函数执行完之后,新进程的初始化工作就完成了,接下来就是调用 wake_up_new_task() 函数将新创建的进程插入到某个 CPU 的 runqueue 中,然后唤醒它来运行。这个函数的主要代码逻辑如下29 30:
static inline
int select_task_rq(struct task_struct *p, int cpu, int wake_flags)
{
lockdep_assert_held(&p->pi_lock);
if (p->nr_cpus_allowed > 1 && !is_migration_disabled(p))
cpu = p->sched_class->select_task_rq(p, cpu, wake_flags);
else
cpu = cpumask_any(p->cpus_ptr);
/* ... */
return cpu;
}
void wake_up_new_task(struct task_struct *p)
{
struct rq_flags rf;
struct rq *rq;
raw_spin_lock_irqsave(&p->pi_lock, rf.flags);
WRITE_ONCE(p->__state, TASK_RUNNING);
#ifdef CONFIG_SMP
p->recent_used_cpu = task_cpu(p);
rseq_migrate(p);
// __set_task_cpu() 会将进程 p 绑定到 select_task_rq() 选择的 CPU 上,
// select_task_rq() 函数会使用调度类的 `select_task_rq()` 成员方法来
// 选出一个合适的 CPU。
__set_task_cpu(p, select_task_rq(p, task_cpu(p), WF_FORK));
#endif
rq = __task_rq_lock(p, &rf);
update_rq_clock(rq);
post_init_entity_util_avg(p);
// 激活新进程,调用 enqueue_entity() 函数将进程插入到选定的 CPU 的 runqueue 中
activate_task(rq, p, ENQUEUE_NOCLOCK);
trace_sched_wakeup_new(p);
// 检查 p 所在的 runqueue 上那个当前正在的任务是否可以被 p 抢占,
// 如果可以的话就在那个调度实体上打上 TIF_NEED_RESCHED 标记
check_preempt_curr(rq, p, WF_FORK);
/* ... */
}
CFS 调度类的 select_task_rq() 函数实现是 select_task_rq_fair(),它的核心策略是负载均衡,所以通常会选择一个当前负载最小的 CPU,或者说最空闲的 CPU。
activate_task() 函数里会调用调度类的成员方法 enqueue_task(),CFS 调度类的实现是 enqueue_task_fair()31:
static void
enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
int idle_h_nr_running = task_has_idle_policy(p);
int task_new = !(flags & ENQUEUE_WAKEUP);
/* ... */
// 组调度循环执行多个调度实体,现在不考虑这种情况,只有一个调度实体
for_each_sched_entity(se) {
if (se->on_rq) // 如果调度实体已经在 runqueue 中了,则不需要再次入队
break;
cfs_rq = cfs_rq_of(se); // 获取当前调度实体所在的 CFS runqueue
enqueue_entity(cfs_rq, se, flags); // 将调度实体插入到 CFS runqueue 中
cfs_rq->h_nr_running++;
cfs_rq->idle_h_nr_running += idle_h_nr_running;
if (cfs_rq_is_idle(cfs_rq))
idle_h_nr_running = 1;
/* end evaluation on encountering a throttled cfs_rq */
if (cfs_rq_throttled(cfs_rq))
goto enqueue_throttle;
flags = ENQUEUE_WAKEUP;
}
/* ... */
}
核心是 enqueue_entity() 函数,它会将新进程对应的调度实体插入到 CPU 的 runqueue 中的红黑树上32:
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
bool renorm = !(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_MIGRATED); // true
// 要入队的调度实体是否就是当前 runqueue 上正在运行的调度实体, false
bool curr = cfs_rq->curr == se;
if (renorm && curr)
se->vruntime += cfs_rq->min_vruntime;
update_curr(cfs_rq); // 更新当前运行队列的调度实体的 vruntime
if (renorm && !curr)
// task_fork_fair() 中减去的 min_vruntime 在这里就加回来了
se->vruntime += cfs_rq->min_vruntime;
// 入队一个新进程的时候需要更新 CFS runqueue 的权重数据
update_load_avg(cfs_rq, se, UPDATE_TG | DO_ATTACH);
se_update_runnable(se);
update_cfs_group(se);
account_entity_enqueue(cfs_rq, se);
if (flags & ENQUEUE_WAKEUP)
// 这里的 se 是新进程,所以不会进到这里,因为进入这个函数之前已经调用过 place_entity()
// 对 vruntime 进行过惩罚了;如果是被唤醒的进程则调用 place_entity() 函数对进程进行奖励,
// 也就是减少其 vruntime
place_entity(cfs_rq, se, 0);
/* Entity has migrated, no longer consider this task hot */
if (flags & ENQUEUE_MIGRATED)
se->exec_start = 0;
check_schedstat_required();
update_stats_enqueue_fair(cfs_rq, se, flags);
check_spread(cfs_rq, se);
if (!curr)
// 核心步骤:如果要入队的调度实体不是当前 cfs_rq 上正在运行的调度实体,
// 则将其插入到 CFS runqueue 的红黑树中
__enqueue_entity(cfs_rq, se);
se->on_rq = 1; // 到这里调度实体肯定已经入队了,所以将 on_rq 标记设置为 1
if (cfs_rq->nr_running == 1) {
check_enqueue_throttle(cfs_rq);
if (!throttled_hierarchy(cfs_rq))
list_add_leaf_cfs_rq(cfs_rq);
}
}
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
// 将给定的调度实体插入红黑树并返回最左子节点
rb_add_cached(&se->run_node, &cfs_rq->tasks_timeline, __entity_less);
}
至此,新进程的调度工作就完成了,接下来就是等待调度器的调度了。这就是我们通过系统调用 fork(2) 创建一个新进程的总体流程。enqueue_task_fair() 不仅负责新进程的入队工作,也负责休眠进程被唤醒之后的入队工作,被唤醒进程的入队工作和新进程的入队工作是类似的,具体的执行逻辑上面也一起分析了。
EEVDF 调度器
Linux 在 2023 年的 6.6 版本引入了一个新的调度器 EEVDF (Earliest Eligible Virtual Deadline First)33,替换掉 CFS 作为 Linux 新一代的默认进程调度器。自此,从 2007 年的 2.6.23 内核版本就开始服役的 CFS 算是正式结束了长达 16 年的使命,正式(在 6.6 及以后的内核版本中)退役了。
EEVDF 虽说是替代了 CFS,但实际上它并不是一个全新的调度器,而是针对 CFS 的一个改进版本。EEVDF 继承了 CFS 的大部分设计理念和实现细节,比如 vruntime、权重值、调度公平性等,只在核心调度算法上做了一些重要的改进,从 EEVDF 的 patch 能看到虽然号称是引入新的调度器,但实际上并没有引入新的调度类,而是在 fair_sched_class 上做了改进,因此我们前面介绍的大部分 CFS 的设计在 EEVDF 中也是适用的。推出 EEVDF 新调度器最大的目的是为了更好地调度延迟敏感型的任务。这一类的任务的调度在 CFS 中并不理想,因为 CFS 追求的是调度的公平性,对于任务的实时性和延迟并没有给予特别的关注和优化。
正如前文所述,CFS 一个比较明显的不足之处就在于在处理延迟敏感型的任务时的表现不尽如人意,这个调度器并没有提供一个渠道给进程去表达它们对低延迟的需求,CFS 会尽量公平地调度每一个相同优先的任务。诚然,用户可以通过降低进程的 nice 值来提高进程的优先级,从而获得更多的 CPU 时间,但更多的 CPU 时间并不代表更低的延迟,延迟大小主要还是取决于进程的被调度的时机和频率,换句话说就是如果要实现低延迟,那么任务必须被更早、更多地调度才行。就算一个进程因为 nice 值很低从而分到了更多的 CPU 时间,但 nice 值对 CFS 的影响仅仅是时间片的长短和 vruntime 的增长速度,CFS 并不会因为一个进程的 nice 更低就更早、更多地调度它,一个获得 CPU 时间很多的进程有可能很晚才被调度运行,这时候 CPU 时间再多也无济于事。因此,在 CFS 调度器管理下的任务,每一个任务被调度的时机和频率是不确定的,因为 CFS 只保证公平性,它只承诺每个任务最终在 CPU 上运行的时间是相等的,正如前面提到过,CFS 的公平性甚至是"最终公平性",也就是说 CFS 只保证在长时间运行的情况下,所有任务的 vruntime 最终会趋于相等。
EEVDF 调度器的理论基础是一篇 1995 年发表的论文《Earliest Eligible Virtual Deadline First: A Flexible and Accurate Mechanism for Proportional Share Resource Allocation》34,其中有严格的数学公式和证明,有兴趣的读者可以自己去阅读原文。本文并不打算专门讲解这篇论文,因为学术论文比较理论化,我们工程师还是应该更关注理论的实际落地细节,所以我会基于论文的理论基础然后结合 Linux 的文档和具体的内核代码来讲解 EEVDF 的设计和实现。
正如我前面提到的那样,EEVDF 并不是一个全新的调度器,而是对 CFS 的一个改进版本,因此它复用了 CFS 的大部分原先的设计和代码实现。在此之外,EEVDF 引入了三个核心的新概念:lag、eligible time 和 virtual deadline。
理论基础
在深入内核关于 EEVDF 的代码实现之前,我们需要先了解论文中关于 EEVDF 的一些概念定义和设定。首先 EEVDF 是论文提出的一种按比例份额分配 CPU 时间资源的新算法,CPU 资源分配以时间量子 (time quantum) 为单位,大小设定为 q,所谓的 time quantum 其实也就是 time slice,时间片的意思。论文中规定了如果一个任务想要获取调度资源,则需发出调度请求并指定其所需的运行时间。调度请求由任务自己发出,或者由调度器代表任务发出,内核会按顺序处理所有的调度请求。
时间份额
我们首先定义任务 i 在时间点 t 的 CPU 时间份额是 f_i(t),w_i 代表任务 i 的权重,A(t) 代表在时间点 t 可运行的任务集合,可得到如下方程:
理想状态下,如果任务的时间份额在 [t, t + \Delta t] 时间段内维持不变,那么任务 i 在此期间应得的 CPU 时间就是 f_i(t) \Delta t。而在现实世界中,f_i(t) 肯定会随着时间的推移而变化,那么我们定义任务 i 在时间段 [t_0, t_1] 内应得的 CPU 时间为 S_i(t_0, t_1),则有积分方程如下:
系统的理想调度调度状态是时间量子 q 无限趋近于 0。然而,我们知道现实世界中并没有无限小的时间量子,我们的世界是量子化的,任何物理量都必定有一个最小值。此外,前面介绍 CFS 的时候也提到过,时间片和调度开销是成反比的,时间片越小,调度 (上下文切换) 的开销就越大。因此无限小的时间片也意味着大部分的 CPU 时间都会花在上下文切换上,进程本身的运行时间就会趋近于 0,这显然不是一个可用的调度方案。时间片过小还有另一个问题是可能会导致一个任务被频繁地抢占 (打断),而某些任务是不允许被打断的,比如一些要求严格时序的网络包发送任务,网络包必须严格按照顺序发送,所以第一个包发送完毕之前绝对不能先发送第二个包,这个时候频繁抢占第一个包的发送任务是没有意义的,因为第一个包没发送出去之前所有其他的包都不能发送出去。
Lag
正因为我们的现实世界是量子化的,或者说离散化的,计算机系统的 CPU 时间资源的分配也必然是以一个个时间量子 (时间片) 为单位,再加上我们讲解 CFS 调度器的时候也说过系统中的任务数量和状态都是不可预测的,以及实际的调度开销,因此调度器给每一个任务分配的理想时间份额和任务实际能获得的时间份额之间必然会有偏差。为了更好地描述这种偏差,论文中引入了一个新的概念:lag,lag 代表的是任务应得的 CPU 时间和实际已得的 CPU 时间之间的差值。论文定义了如下方程:
其中 lag_i(t) 代表 任务 i 在时间点 t 的 lag 值,t_0^i 是任务就绪 (状态变成可运行) 的时间点,s_i(t_0^i, t) 代表任务 i 在时间段 [t_0^i, t] 内实际已得的 CPU 时间,S_i(t_0^i, t) 代表任务 i 在时间段 [t_0^i, t] 内应得的 CPU 时间。
EEVDF 本质还是一个公平性调度器,追求公平地为每个进程分配 CPU 时间,实现手段无非也还是对多用了 CPU 时间的进程进程惩罚,对少用了 CPU 时间的进程进行补偿。内核就是通过 lag 来实现这种奖惩机制,lag 代表的是理论上进程应得的 CPU 时间和实际已消耗的 CPU 时间之间的差值,也就是系统"亏欠"一个进程的 CPU 时间。
截止时间
熟悉实时操作系统的的读者应该对截止时间 (deadline) 这个概念比较熟悉,截止时间是指一个任务获得其请求的所有资源的最晚时间点。以周期性调度为例,调度周期假设为 T,任务在每个调度周期 (调度延迟) 里请求的 CPU 时间是 r,在实时操作系统中,实时调度器要求任务在 T 周期内必须获得不少于 r 的 CPU 时间,所以该任务在调度周期内的时间份额就是 f = \frac{r}{T}。那么反过来说,如果我们先设定一个任务的时间份额是 f,任务在时间点 t 发出调度请求,对于实时操作系统来说,任务在下一个 T 到来之前必须要完成本次运行,所以任务的截止时间就是 t + T,而我们又已知 f = \frac{r}{T},所以可得截止时间为 t + \frac{r}{f}。
虚拟时间
结合前面的方程 (1) 和 (2) 我们可以推导出如下方程:
其中令系统的虚拟时间为 V(t),其定义为:
也就是说系统的虚拟时间是通过所有可运行任务的权重之和的倒数来定义的,比如一个 runqueue 里现在有两个任务,其权重分别为 w_1 和 w_2,那么系统的虚拟时间流速就是 \frac{1}{w_1 + w_2},也就是每一个物理时间单位对应的虚拟时间单位是 w_1 + w_2。比如 w_i = 2 和 w_j = 3,那么系统的虚拟时间流速就是 \frac{1}{2 + 3} = \frac{1}{5} = 0.2,也就是说每经过 5 个物理时间单位,系统的虚拟时间才会增加 1 个单位。
再结合方程 (4) 和 (5),根据微积分第二基本定理35:
我们可以变换得到如下方程:
这个方程表示权重为 w_i 的任务 i 在时间段 [t_1, t_2] 内应得的 CPU 虚拟时间。在 EEVDF 中,基本上所有的关于时间的调度决策都是基于虚拟时间,物理时间的概念被淡化了。
Eligible Time
这是这篇论文独创的一个新概念,表示任务"有资格"运行的时间点。论文里给 eligible time 的定义是:任务 i 从变成就绪 (可运行) 状态的时间点 t_0^i 开始算起,在发起新的调度请求之前,其理论应得的 CPU 时间长度正好等于实际已得的 CPU 时间长度的时间点就是 eligible time。通过数学方程来描述就是 S_i(t_0^i, e) = s_i(t_0^i, t),其中 e 表示 eligible time,t 表示发起新调度请求的时间点。前面介绍的 lag 值和 eligible time 这两个概念是密切相关的,lag 值用来判定一个任务是否 eligible,也就是是否有资格运行,如果一个任务的 lag 值为正,那么它就是 eligible 的,反之则不 eligible。当 lag 值为正,说明系统"亏欠"了这个任务一定的 CPU 时间,那么该任务立刻就可以发起调度请求要求调度器执行它,而当 lag 值为负,说明该任务已经"超额"使用了 CPU 时间,那么该任务就必须至少等到下一次 eligible time 时间点才能发起新的调度请求。通过这种方式,EEVDF 调度器就可以给"亏欠的"任务提速而给"超额的"任务降速,从而实现对任务的奖惩,保证公平性调度。
通过对 S_i(t_0^i, e) = s_i(t_0^i, t) 应用方程 (6) 我们可以推导出 eligible time 的计算公式:
其中 V(t_0^i) 表示任务 i 就绪时的虚拟时间,s_i(t_0^i, t) 表示任务 i 在时间段 [t_0^i, t] 内实际已得的 CPU 时间,w_i 是任务 i 的权重。这里的 \frac{s_i(t_0^i, t)}{w_i} 之所以要除以权重值,就是为了将物理时间转换为虚拟时间,这是公平调度的核心思想之一。因为不同任务的权重不同,所以它们的虚拟时间流速也不同,权重越大,虚拟时间流速就越快,反之则越慢。通过除以权重值,我们就可以将物理时间转换为虚拟时间。
Virtual Deadline
这是另一个 EEVDF 核心的概念,virtual deadline 表示虚拟截止时间,我们将其定义为 V_d,eligible time 为 V(e),V(d) 必须满足以下约束条件:任务 i 发起调度请求时期望得到的 CPU 时间 r 等于 [V(e), V(d)] 期间累加的 CPU 时间,也即是 S_i(e, d) = r,其中 r 是任务发起调度请求时期望的 CPU 时间长度。通过对这个公式应用方程 (6) 可得:
其中 V(d) 就是所谓的 virtual deadline,它的值就是任务的 eligible time 再加上任务的加权 CPU 时间片,这是一个类似于实时操作系统 deadline 概念的东西,读者可能会想起前文介绍的 dl_sched_class 调度类,但是 EEVDF 并不是一个实时调度器,所以并不追求任务的实时性,而且 Linux 也不是一个实时操作系统而是一个分时操作系统,所以 EEVDF 调度器不会真的强制要求任务一定要在 virtual deadline 之前完成,而只是借用了实时调度器的 deadline 概念。
此外,实时调度并不等同于性能高,实时系统最大的优势是调度的确定性:调度器能在极其确定的时间内处理一次中断,这是非实时系统做不到的,但是实时系统的性能和吞吐量却未必比非实时系统高。另一方面,实时系统调度器的劣势是适用性较差,对于实时任务 (比如音视频编解码) 之外的任务类型的支持比较差,比如交互型任务和批处理任务,因为这类任务的耗时很难预测,因此无法在的时间内给出确定性的响应,灵活性不够。EEVDF 的设计目标是成为一个通用的公平性调度器,同时提供较强的时效性保证。
内核实现
Lag
内核中 lag 的计算公式是 lag_i = S - s_i,其中 S 是理论上每一个进程应得的(物理) CPU 时间,s_i 是进程实际已消耗的(物理) CPU 时间。通过前面的内容我们知道 v_i = \frac{NICE\_0\_LOAD}{w_i} \times s_i 和 V = \frac{NICE\_0\_LOAD}{w_i} \times S,其中 w_i 是进程的权重,V 是 S 对应的虚拟时间,v_i 是进程的虚拟时间。因此 lag 的计算公式可以进一步推演为 lag_i = S - s_i = w_i \times (V - v_i)。NICE\_0\_LOAD 是一个常数 1024,可以在公式中隐去。
任意一个进程的 lag 可正可负,正值表示进程被"亏欠"的 CPU 时间,负值表示进程"超额"使用的 CPU 时间。而要保证公平性调度,所有进程的 lag 之和必定是 0,也就是 \sum_{i=0}^{n-1} lag_i = 0,其中 n 是系统中所有进程的数量。所以可以进一步推导:
其中 W = \sum_{i=0}^{n-1} w_i,最后算出了 V 是所有进程的虚拟时间的加权平均值。因此,lag_i = S - s_i = w_i \times (V - v_i) 的实际含义是:进程 i 的 lag_i 等于当前系统中所有可运行进程理论应得的加权平均 CPU 时间减去进程 i 实际已得的 CPU 时间的差值。
由于 v_i 是一个单调递增的虚拟时间,即便它的类型是 u64 (无符号 64 位整数),代码中的 v_i \times w_i 也可能会溢出,为了避免这个问题,内核在计算 v_i \times w_i 时会先将 v_i 减去一定的值,也就是 v_i = (v_i - v0) + v0,那么 V 的计算公式就变成了这样:
其中 v0 的取值是 cfs_rq->min_vruntime,也就是当前 CFS runqueue 中的最小 vruntime。
内核中计算 lag 的核心函数是 avg_vruntime(),它负责计算上面方程中的 V,cfs_rq->avg_vruntime 就是方程中的 \sum_{i-0}^{n-1} (v_i - v0) \times w_i,cfs_rq->avg_load 则是当前 CFS runqueue 中所有可运行任务的权重之和:W = \sum_{i=0}^{n-1} w_i,源码如下36:
u64 avg_vruntime(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr; // 获取当前的调度实体
s64 avg = cfs_rq->avg_vruntime;
long load = cfs_rq->avg_load;
if (curr && curr->on_rq) {
unsigned long weight = scale_load_down(curr->load.weight);
avg += entity_key(cfs_rq, curr) * weight;
load += weight;
}
if (load) {
/* sign flips effective floor / ceiling */
if (avg < 0)
avg -= (load - 1);
// \Sum (v_i - v0) * w_i / W
avg = div_s64(avg, load);
}
return cfs_rq->min_vruntime + avg;
}
Eligible Time
在 EEVDF 原论文中,eligible time 是一个相对复杂的概念。而在内核的代码实现中,eligible time 等同于任务的 vruntime,也就是 se->vruntime。
Virtual Deadline
内核中的 virtual deadline 计算遵循 EEVDF 论文中的方程,也就是上面的方程 (8),内核在调度实体 sched_entity 中新增了一个 deadline 字段来存储 virtual deadline 的值,删减过后的内核源码如下37:
static void
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
u64 vslice, vruntime = avg_vruntime(cfs_rq);
s64 lag = 0;
if (!se->custom_slice) // 用户没有设置自定义的任务时间片长度
se->slice = sysctl_sched_base_slice; // 所以使用内核的时间片默认值 0.7ms
// 这里就是方程 (8) 中的 r_i/w_i,这个函数前面在介绍 CFS 的时候讲解过,
// 实际是调用 __calc_delta() 函数,计算公式是 se->slice * NICE_0_LOAD / weight,
// 其中 se->slice 是任务的时间片长度,NICE_0_LOAD 是一个常量 1024,weight 是任务的权重。
vslice = calc_delta_fair(se->slice, se);
/* ... */
/*
* EEVDF: vd_i = ve_i + r_i/w_i
*/
se->deadline = se->vruntime + vslice;
}
论文中的 virtual deadline 是任务的 eligible time 加上任务请求的 CPU 时间片长度除以任务权重。而内核的实现时,将任务的 vruntime 作为 eligible time,然后加上任务请求的 CPU 时间片长度除以任务权重,再乘上一个常数系数 1024。
本章节开头就陈述过,引入 EEVDF 调度器的最大目的是为了弥补 CFS 调度器在调度延迟敏感型任务时的不足,通过更早、更频繁地调度这一类任务来实现。而 virtual deadline 正是达成这个目标的核心,EEVDF 调度器复用了 CFS 调度器的红黑树数据结构来存储所有的调度实体,并对其进行了改进,称之为增强红黑树。相较于 CFS,EEVDF 的红黑树中不再是以 vruntime 为 key 来排序,而是换成了 virtual deadline,也就是从 se->vruntime 改成了 se->deadline。CFS 调度器支持通过 nice(2) 系统调用为进程设置 nice 值从而调整任务权重,EEVDF 调度器继承了这个权重值,同时移除了 CFS 的其他启发式的配置项38。除此之外,EEVDF 还引了一个新的配置值 —— sched_runtime,允许用户通过 sched_setattr(2) 配置进程的请求 CPU 时间片长度,也就是方程 (8) 里的 r,其实这个字段之前就有,但是在此之前这个字段只用于内核中的实时 (RT) 调度类的,后来将其推广到 EEVDF 调度器。
通过调整 nice 和 sched_runtime 这两个参数,可以分别增加任务的权重和减少任务的时间片长度,如此一来 virtual deadline 也会随之变小,而 EEVDF 调度任务的时候会优先从红黑树中挑选出 virtual deadline 最小的调度实体来运行,这样就可以保证延迟敏感型任务会被更早地调度运行。此外,EEVDF 还会用 virtual deadline 更小的任务来抢占正在运行中的 virtual deadline 更大的任务,从而进一步降低延迟敏感型任务的延迟时间。有人可能要问了,虽然这种调度算法可以使得延迟敏感型的任务更早地被执行,但是每次的 CPU 时间片也变少了,也就是任务被打断(抢占)的频率也更高了,这样似乎反而会导致任务的延迟更大?内核团队给出的答案是:延迟敏感型的任务通常来讲并不需要太多的 CPU 时间,所以单次时间片变小对这类任务的影响并不算大,调度时机才是最重要的,也就是说这类任务最迫切需要的是尽早被放到 CPU 上去运行。举个例子,假设有一个性能敏感的任务被创建了,整个任务只需要 1ms 就可以执行完,但是由于 CFS 调度器的公平性调度特性,这个任务可能需要等到 10ms 之后才能被调度运行,那么延迟至少就要 10ms。而如果使用 EEVDF 调度器,用户则可以设置 sched_runtime 为 1ms,那么该任务的 virtual deadline 值就会非常小,EEVDF 调度器会优先调度这个任务,即便给它分配的 CPU 时间片只有 1ms,但由于该任务的总耗时也就 1ms,所以第一次调度就可以完成任务的执行,延迟也就只有 1ms。
调度原理
EEVDF 调度器的核心策略就是挑选出 virtual deadline 最小的调度实体来运行。宏观层面来看,这个过程和 CFS 调度器的挑选 vruntime 最小的调度实体来运行是类似的,但是多了一步 lag 计算。先来回顾一下 lag 的计算公式:lag_i = S - s_i = w_i \times (V - v_i),又因为 eligible 进程 i 必须满足条件:lag_i \geq 0,可得 V \geq v_i,而 V = \frac{\sum_{i=0}^{n-1} (v_i - v0) \times w_i}{W} + v0,所以可以推导出 \sum_{i=0}^{n-1} (v_i - v0) \times w_i \geq (v_i -v0) \times \sum_{i=0}^{n-1} w_i,根据上文可知是 cfs_rq->avg_vruntime >= (se->vruntime - cfs_rq->min_vruntime) * cfs_rq->avg_load,对应的内核源码是 vruntime_eligible() 函数,源码如下39:
static int vruntime_eligible(struct cfs_rq *cfs_rq, u64 vruntime)
{
struct sched_entity *curr = cfs_rq->curr; // 获取当前的调度实体
s64 avg = cfs_rq->avg_vruntime;
long load = cfs_rq->avg_load;
if (curr && curr->on_rq) {
unsigned long weight = scale_load_down(curr->load.weight);
avg += entity_key(cfs_rq, curr) * weight;
load += weight;
}
return avg >= (s64)(vruntime - cfs_rq->min_vruntime) * load;
}
int entity_eligible(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
return vruntime_eligible(cfs_rq, se->vruntime);
}
内核中 EEVDF 调度器挑选下一个调度实体的代码逻辑在 pick_eevdf() 函数中实现,其调用路径是:
pick_next_task_fair() -> pick_task_fair() -> pick_next_entity() -> pick_eevdf()
前面已经说过,EEVDF 在内核中并没有引入新的调度类,而是在 CFS 调度类之上做了改进。所以 EEVDF 调度器复用了大部分 CFS 的代码逻辑,因此调度逻辑基本沿用了 CFS 调度器。EEVDF 的增强红黑树使用 virtual deadline 作为 key 排序,同时引入 min_vruntime 来记录子树中的最小 vruntime。这里我们重点摘取 EEVDF 调度器挑选下一个任务的源码来解析40:
static struct sched_entity *pick_eevdf(struct cfs_rq *cfs_rq)
{
struct rb_node *node = cfs_rq->tasks_timeline.rb_root.rb_node;
// 和 CFS 一样,EEVDF 会缓存红黑树缓存的最左子节点,这里直接取缓存的节点
struct sched_entity *se = __pick_first_entity(cfs_rq);
struct sched_entity *curr = cfs_rq->curr; // 获取当前的调度实体
struct sched_entity *best = NULL;
/* ... */
// 如果最左子节点 eligible,则直接返回,时间复杂度 O(1),
// entity_eligible() 会调用 vruntime_eligible() 来判断
// 任务的 lag 是否大于 0
if (se && entity_eligible(cfs_rq, se)) {
best = se;
goto found;
}
// 缓存的最左子节点不 eligible,lag < 0,说明没资格运行,
// 那就只能在红黑树中进行堆搜索,到找到最小的 virtual deadline,
// 时间复杂度 O(log N)
while (node) {
struct rb_node *left = node->rb_left;
// 已知 lag = w_i * (V - v_i),而 eligible 的条件是 lag >= 0,
// 也就是 V >= v_i,V 是所有就绪任务的加权平均虚拟时间,在这个时间点
// 可以认为是固定不变的,所以如果左子树的最小 vruntime 小于等于
// min_vruntime 的话,说明左子树中肯定至少包含一个 eligible 的任务,
// 又因为红黑树是按 virtual deadline 排序的,所以左子树中的最小
// virtual deadline 一定要小于右子树中的最小 virtual deadline,
// 因此可以跳过右子树,直接在左子树中继续搜索。
if (left && vruntime_eligible(cfs_rq,
__node_2_se(left)->min_vruntime)) {
node = left;
continue;
}
se = __node_2_se(node);
// 到这一步说明已经触及红黑树的最左侧了,此时左子树要么为空要么不包含
// 任何 eligible 的任务,所以可以直接判断当前节点是否 eligible,
// 如果 eligible 则直接返回当前节点,否则就调转方向去搜索右子树。
if (entity_eligible(cfs_rq, se)) {
// 该任务被判定为 eligible,说明其 virtual deadline
// 是红黑树中所有就绪任务的最小值,直接选中返回。
best = se;
break;
}
// 调转方向,往右子树那边进行堆搜索。
node = node->rb_right;
}
found:
// 如果在红黑树中没有搜索到 eligible 的任务可以调度运行,
// 或者当前在运行中的任务比最 eligible 的任务的 virtual deadline
// 更小,那么直接选择当前任务。
if (!best || (curr && entity_before(curr, best)))
best = curr;
return best;
}
调度起点
内核从启动之初就会调度任务,所以调度器的代码可以说是贯穿了整个内核的生命周期。接下来我们来看看内核是如何启动并开始执行调度器代码的。
内核启动时的入口是 start_kernel() 函数,其中会完成各式各样的初始化工作,比如 CPU 的初始化、内存管理的初始化等,当然也包括调度器的初始化,通过 sched_init() 函数来完成,因为系统启动之后可能很快就有系统中断发生,我们前面已经说过,触发调度的一个重要的时机之一就是当从中断返回的时候,所以如果调度器在此之前没有准备好,则中断处理就会有问题。start_kernel() 最后调用 rest_init() 完成最后一点工作,系统开始运转41:
asmlinkage __visible __init __no_sanitize_address __noreturn __no_stack_protector
void start_kernel(void)
{
char *command_line;
char *after_dashes;
set_task_stack_end_magic(&init_task);
smp_setup_processor_id();
debug_objects_early_init();
init_vmlinux_build_id();
cgroup_init_early();
local_irq_disable();
early_boot_irqs_disabled = true;
/*
* Interrupts are still disabled. Do necessary setups, then
* enable them.
*/
boot_cpu_init();
page_address_init();
pr_notice("%s", linux_banner);
setup_arch(&command_line);
/* Static keys and static calls are needed by LSMs */
jump_label_init();
static_call_init();
early_security_init();
setup_boot_config();
setup_command_line(command_line);
setup_nr_cpu_ids();
setup_per_cpu_areas();
smp_prepare_boot_cpu(); /* arch-specific boot-cpu hooks */
early_numa_node_init();
boot_cpu_hotplug_init();
/* ... */
/*
* Set up the scheduler prior starting any interrupts (such as the
* timer interrupt). Full topology setup happens at smp_init()
* time - but meanwhile we still have a functioning scheduler.
*/
sched_init();
/* ... */
thread_stack_cache_init();
cred_init();
fork_init();
proc_caches_init();
uts_ns_init();
key_init();
security_init();
dbg_late_init();
net_ns_init();
vfs_caches_init();
pagecache_init();
signals_init();
seq_file_init();
proc_root_init();
nsfs_init();
pidfs_init();
cpuset_init();
mem_cgroup_init();
cgroup_init();
taskstats_init_early();
delayacct_init();
acpi_subsystem_init();
arch_post_acpi_subsys_init();
kcsan_init();
// 系统主要的初始化工作都已完成,内核已激活。现在调用最后一个 init 函数,
// 完成剩下的一点点工作,系统开始运转。
rest_init();
/*
* Avoid stack canaries in callers of boot_init_stack_canary for gcc-10
* and older.
*/
#if !__has_attribute(__no_stack_protector__)
prevent_tail_call_optimization();
#endif
}
内核会启动第一个进程,称之为 Process 0 或者 Swapper 进程,我们都知道 Linux 有一个 init 进程,它是 Linux 的根进程,PID 是 1,所以也叫 1 号进程,这个进程是内核创建的第一个用户空间的进程,它是未来所有用户进程的祖先,以后产生的新进程都衍生自这个 init 进程。init 进程是由 swapper 进程创建的,其核心代码逻辑在 kernel_init() 函数中,主要作用是完成设备驱动的初始化,以及内核中的部分其他初始化工作,随后执行 execve 操作,运行可执行程序 init,正式转变成用户态进程。rest_init 精简后的代码如下42 43:
static noinline void __ref __noreturn rest_init(void)
{
struct task_struct *tsk;
int pid;
rcu_scheduler_starting();
// 创建用户态线程,执行 kernel_init() 函数初始化设备驱动,
// 运行 1 号进程,也就是 init 进程。
pid = user_mode_thread(kernel_init, NULL, CLONE_FS);
numa_default_policy();
// 创建内核线程,也就是 2 号进程 kthreadd
pid = kernel_thread(kthreadd, NULL, NULL, CLONE_FS | CLONE_FILES);
/* ... */
// 在关闭抢占的情况下,执行一次调度工作,
// 这里主要是为了内核启动时能正常运行起来
schedule_preempt_disabled();
// 系统刚启动,还没有任何任务,所以尝试使 CPU 保持空闲状态
cpu_startup_entry(CPUHP_ONLINE);
}
void __sched schedule_preempt_disabled(void)
{
sched_preempt_enable_no_resched();
schedule(); // 调度器入口
preempt_disable();
}
cpu_startup_entry() 函数是一个无限循环,循环体中的逻辑也非常简单,就只是调用 do_idle(),尝试使 CPU 保持空闲状态44:
void cpu_startup_entry(enum cpuhp_state state)
{
current->flags |= PF_IDLE;
arch_cpu_idle_prepare();
cpuhp_online_idle(state);
while (1)
do_idle();
}
do_idle() 函数是内核中使 CPU 保持空闲状态的核心函数,其主要逻辑是循环检查当前进程是否有 TIF_NEED_RESCHED 标志,如果没有则说明没有其他进程准备抢占它的 CPU 去运行,也就是说系统中暂时没有其他可运行的进程,因为这是系统刚启动的时候,所以可能还没有启动任何用户进程。此时则让 CPU 进入空闲状态,不做任何事,节省算力。函数的源码如下45:
static void do_idle(void)
{
int cpu = smp_processor_id();
/*
* Check if we need to update blocked load
*/
nohz_run_idle_balance(cpu);
/*
* If the arch has a polling bit, we maintain an invariant:
*
* Our polling bit is clear if we're not scheduled (i.e. if rq->curr !=
* rq->idle). This means that, if rq->idle has the polling bit set,
* then setting need_resched is guaranteed to cause the CPU to
* reschedule.
*/
__current_set_polling();
tick_nohz_idle_enter();
while (!need_resched()) {
/* ... */
arch_cpu_idle_enter();
rcu_nocb_flush_deferred_wakeup();
if (cpu_idle_force_poll || tick_check_broadcast_expired()) {
tick_nohz_idle_restart_tick();
// 内核启动时设置了轮询模式 idle=poll,那么就会调用 cpu_idle_poll(),
// 这个函数的主体逻辑实际上就是不断地轮询检查当前进程的 TIF_NEED_RESCHED 标志
cpu_idle_poll();
} else {
// 如果没有设置轮询模式,则走 cpuidle_idle_call() 函数,
// 主动让 CPU 进入 idle 状态
cpuidle_idle_call();
}
arch_cpu_idle_exit();
}
/* ... */
// 如果系统中有了其他的进程,这个 0 号进程就可以被抢占,
// 被打上 TIF_NEED_RESCHED 标志,所以调用 schedule_idle(),
// 该函数和 schedule_preempt_disabled() 类似,也是执行任务调度
schedule_idle();
if (unlikely(klp_patch_pending(current)))
klp_update_patch_state(current);
}
void __sched schedule_idle(void)
{
WARN_ON_ONCE(current->__state);
do {
__schedule(SM_IDLE);
} while (need_resched());
}
static __always_inline bool need_resched(void)
{
return unlikely(tif_need_resched());
}
这里重点要关注的是 cpuidle_idle_call() 函数,它会先检查当前系统中是否有高级电源管理模块,如果有的话则使用这个模块来指示 CPU 进入休眠状态,不同架构的芯片通常有不同的实现,比如 x86,则通常是通过高级的低功耗指令 MWAIT 来指示 CPU 进入休眠;如果没有高级电源管理模块的话,cpuidle_idle_call() 则会调用 default_idle_call() 走比较通用的、低级的低功耗指令,同样也是不同架构的芯片有不同实现:比如 x86 架构的 CPU 是执行 HLT 指令,arm 架构的话则是执行 WFI 指令。
到这里 0 号进程就完成了第一颗 CPU 的休眠指示,也就是令其进入 idle 状态。而在 0 号进程执行的 kernel_init() 函数中,还会通过函数调用链 smp_init() --> idle_threads_init() 为剩余的每一个 CPU 都复制出一个这样的 idle 进程46 47:
void __init smp_init(void)
{
int num_nodes, num_cpus;
// 从 0 号进程复制出一堆 idle 进程,每个 CPU 绑定一个
idle_threads_init();
cpuhp_threads_init();
pr_info("Bringing up secondary CPUs ...\n");
bringup_nonboot_cpus(setup_max_cpus);
num_nodes = num_online_nodes();
num_cpus = num_online_cpus();
pr_info("Brought up %d node%s, %d CPU%s\n",
num_nodes, str_plural(num_nodes), num_cpus, str_plural(num_cpus));
/* Any cleanup work */
smp_cpus_done(setup_max_cpus);
}
/**
* idle_threads_init - Initialize idle threads for all cpus
*/
void __init idle_threads_init(void)
{
unsigned int cpu, boot_cpu;
boot_cpu = smp_processor_id();
// 遍历所有可用的 CPU,调用 idle_init()
// 每一个 CPU 都初始化一个 idle 进程
for_each_possible_cpu(cpu) {
if (cpu != boot_cpu) // 除去当前启动的 CPU
idle_init(cpu);
}
}
static __always_inline void idle_init(unsigned int cpu)
{
// 检查这个 CPU 是否有绑定一个 idle 进程,per_cpu 返回空则表示否
struct task_struct *tsk = per_cpu(idle_threads, cpu);
if (!tsk) {
// 如果这个 CPU 上没有绑定一个 idle 进程,则从当前的 0 号进程
// fork 一个 idle 进程出来,然后绑定到这个 CPU 上运行
tsk = fork_idle(cpu);
if (IS_ERR(tsk))
pr_err("SMP: fork_idle() failed for CPU %u\n", cpu);
else
// 调用 per_cpu() 将 idle 进程绑定到 CPU 上
per_cpu(idle_threads, cpu) = tsk;
}
}
经过上面的剖析,内核启动时的简化模型如下:
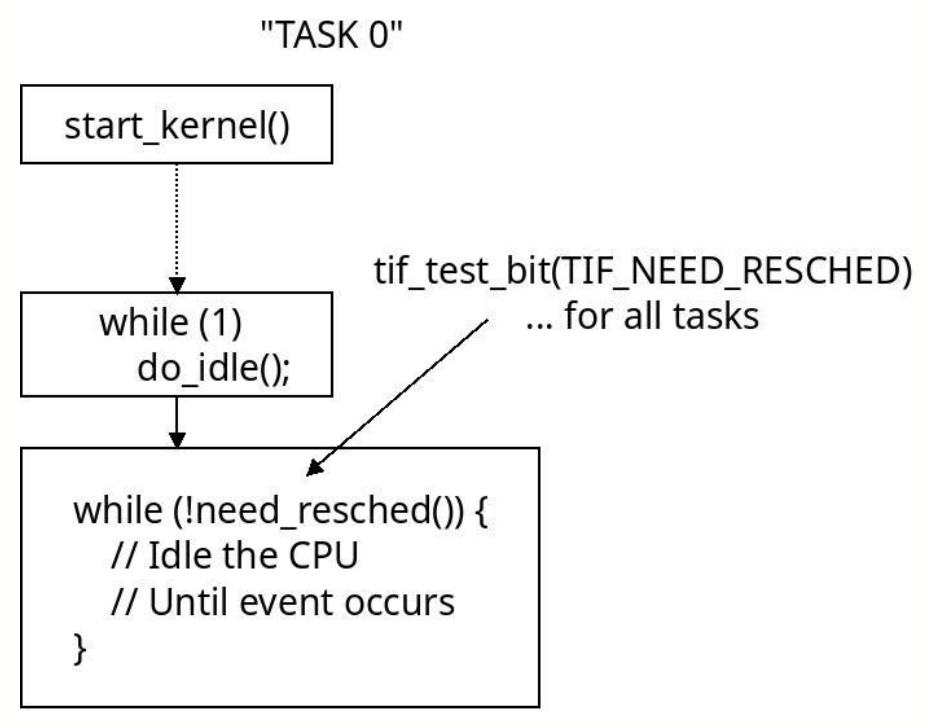
内核启动时使用的第一个 CPU 会启动并运行 0 号进程,随后 0 号进程会为剩下的 CPU 也都分配一个从 0 号进程 fork 出来的 idle 进程去运行。它们是系统中优先级最低的进程,当系统中没有可运行任务时,调度器就调度这些进程到 CPU 上,指示 CPU 进入低功耗模式。一旦有任何可运行的任务出现,调度器就会马上抢占这些 idle 进程,切换上下文,执行其他进程。
总结
本文深入浅出地对 Linux 调度器的设计与实现进行了全面解读,介绍了 Linux 从早期的 O(1) 调度器到服役时间最长、应用最广泛的 CFS 调度器,最后到最新一代的 EEVDF 调度器的演变过程。通过对调度器的设计理念、核心算法、数据结构以及代码实现细节的解析,全面而深入地帮助读者深刻地理解 Linux 内核如何高效地管理 CPU 资源,调度任务执行。
本文的核心是对 CFS 调度器的剖析,以及 CFS 进化到最新一代 EEVDF 调度器的过程。CFS 调度器通过引入虚拟时间 vruntime 和权重的概念,实现了公平性调度,而 EEVDF 则在此基础上进一步优化了延迟敏感型任务的调度性能。EEVDF 在 CFS 的公平性调度基础上,又引入 lag、eligible time 和 virtual deadline 等新概念,实现了对延迟敏感型任务调度的更好支持,使得 Linux 内核能够更好地适应现代多样化的应用场景。特别是随着 AI 浪潮的到来,在模型训练、模型推理等场景中,我们对低延迟的需求会越来越大,相信新一代的 EEVDF 调度器会在这样的浪潮中发挥越来越大的作用。
参考&延伸
- sched(7) — Linux manual page
- Linux Kernel Development, Third Edition
- Understanding the Linux Kernel, 3rd Edition
- CFS Scheduler
- EEVDF Scheduler
- An EEVDF CPU scheduler for Linux
- Completing the EEVDF scheduler
- Linux kernel schedulers
- LLC 2025 - Linux scheduler overview and update, by Linus Walleij
- Linux 6.12: Scheduler now expandable and EEVDF conversion complete
- Modern Operating Systems
- Digging into the Linux scheduler
- CFS: Completely fair process scheduling in Linux
- CFS Scheduler in the Linux Kernel
- Tuning the Linux Kernel Scheduler
- The Linux Kernel Scheduler
- Earliest Eligible Virtual Deadline First : A Flexible and Accurate Mechanism for Proportional Share Resource Allocation
- EEVDF is the new (sched_)normal

