佩奇排名(PageRank),又称网页排名、谷歌左侧排名,是一种由搜索引擎根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry Page)之姓来命名。Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。
概念
Spark 中有一个很重要的特性是对数据集在节点间的分区进行控制,因为在分布式系统中,通信的代价是很大的,因此控制数据分布以获得最少的网络传输可以极大地提升整体性能,Spark 程序可以通过控制 RDD 分区方式来减少通信开销。分区适用于那种基于类似 join 操作基于键的操作,并且一方的 RDD 数据是比较少变动且需要多次扫描的情况,这个时候可以对这个 RDD 做一个分区,最常用的是用 Hash 来进行分区,比如可以对 RDD 分 100 个区,此时 spark 会用每个键的 hash 值对 100 取模,然后把相同结果的放到同一个节点上。
Spark 分区的讲解
现在用一个例子(来自《Learning Spark: Lightning-Fast Big Data Analysis》一书)来说明一下:
// Initialization code; we load the user info from a Hadoop SequenceFile on HDFS.
// This distributes elements of userData by the HDFS block where they are found,
// and doesn't provide Spark with any way of knowing in which partition a
// particular UserID is located.
val sc = new SparkContext(...)
val userData = sc.sequenceFile[UserID, UserInfo]("hdfs://...").persist()
// Function called periodically to process a logfile of events in the past 5 minutes;
// we assume that this is a SequenceFile containing (UserID, LinkInfo) pairs.
def processNewLogs(logFileName: String) {
val events = sc.sequenceFile[UserID, LinkInfo](logFileName)
val joined = userData.join(events)// RDD of (UserID, (UserInfo, LinkInfo)) pairs
val offTopicVisits = joined.filter {
case (userId, (userInfo, linkInfo)) => // Expand the tuple into its components
!userInfo.topics.contains(linkInfo.topic)
}.count()
println("Number of visits to non-subscribed topics: " + offTopicVisits)
}
上面的例子中,有两个 RDD,userData 的键值对是(UserID, UserInfo),UserInfo 包含了一个该用户订阅的主题的列表,该程序会周期性地将这张表与一个小文件进行组合,这个小文件中存着过去五分钟内某个网站各用户的访问情况,由(UserID, LinkInfo)。现在,我们需要对用户访问其未订阅主题的页面进行统计。可以通过 Spark 的 join()操作来完成这个功能,其中需要把 UserInfo 和 LinkInfo 的有序对根据 UserID 进行分组,如上代码。
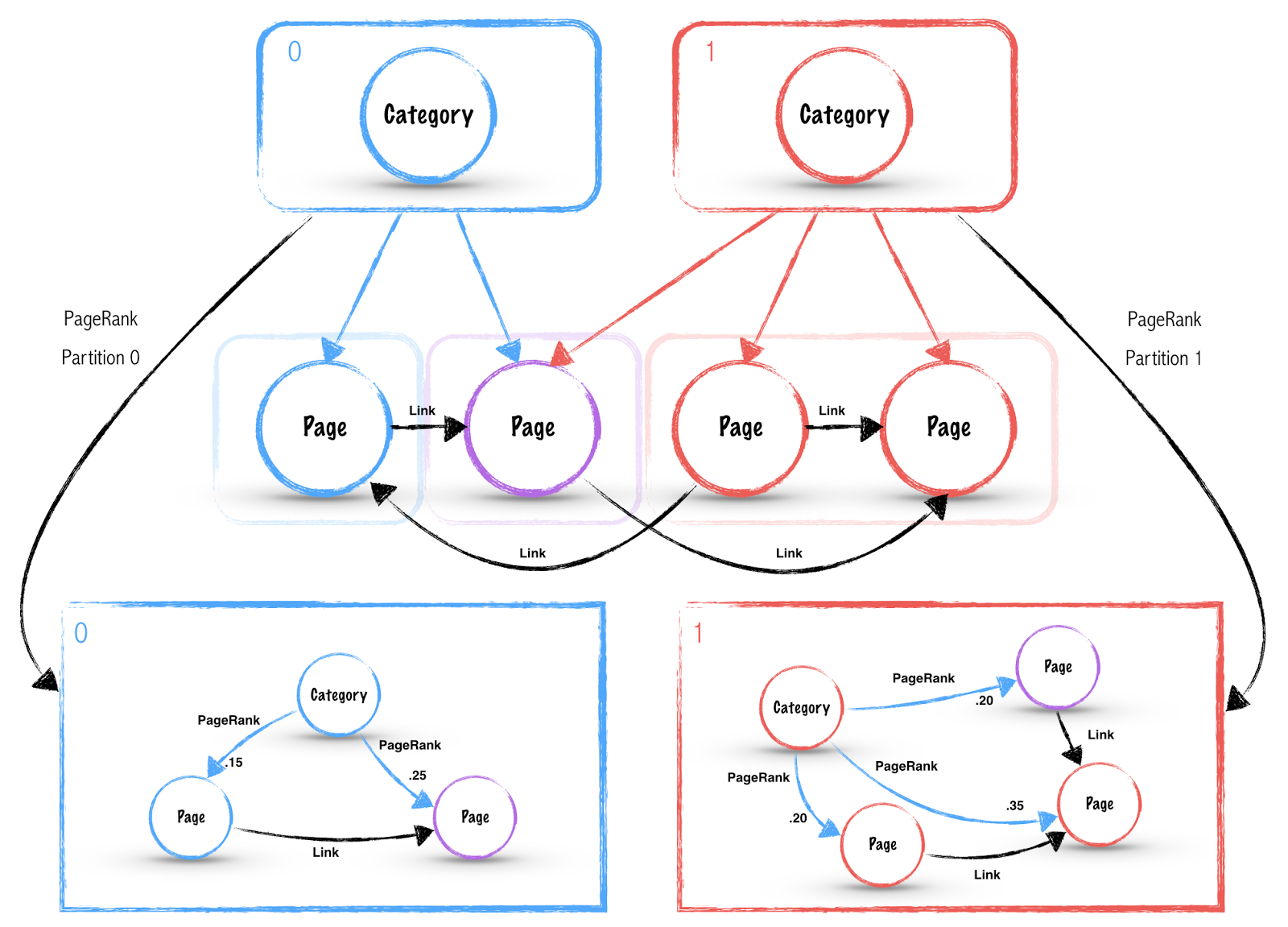
可以看出,因为每次调用 processNewLogs()时都需要执行一次 join()操作,但是数据具体的 shuffle 对我们来说却是不可控的,也就是我们不知道 spark 是如何进行分区的。spark 默认在执行 join()的时候会将两个 RDD 的键的 hash 值都算出来,然后将该 hash 值通过网络传输到同一个节点上进行相同键值的记录的连接操作,如下图所示:

因为 userData 这个 RDD 里面的数据是几乎不会变动的,或者说是极少会变动的,且它的内容也比 events 大很多,所以每次都要对它进行 shuffle 的话,是没有必要且浪费时间的,实际上只需要进行一次 shuffle 就可以了。
所以,可以通过预先分区来解决这个问题:在进行 join()之前,对 userData 使用 partitionBy()转化操作,把它变成一个哈希分区的 RDD:
val sc = new SparkContext(...)
val userData = sc.sequenceFile[UserID, UserInfo]("hdfs://...")
.partitionBy(new HashPartitioner(100)) // Create 100 partitions
.persist()
调用 partitionBy()之后,spark 就可以预先知道这个 RDD 是已经进行过哈希分区的了,等到执行 join()之时,它就会利用这一点:只对 events 进行 shuffle,将 events 中特定 UserID 的记录发送到 userData 对应分区的机器节点上去。这样的话,就减少了大量的重复的网络通信,程序性能也会大大提高。改进后的程序的执行过程如下:

还有一点,你们可能注意到了新代码里最后还调用了一个 persist()方法,这是另一个小优化点:对于那些数据不常变动且数据量较大的 RDD,在进行诸如 join()这种连接操作的时候尽量用 persist()来做缓存,以提高性能。另外,分区数目的设置也有讲究,分区数目决定了这个任务在执行连接操作时的并行度,所以一般来说这个数目应该和集群中的总核心数保持一致。
最后,可能有人会问,能不能对 events 也进行分区进一步提高程序性能?这是没有必要的,因为 events RDD 是本地变量,每次执行都会更新,所以对它进行分区没有意义,即便对这种一次性变量进行分区,spark 依然需要进行一次 shuffle,所以,这是没有必要的。
使用分区来加快 PageRank 算法
PageRank 算法是一种从 RDD 分区获益的更复杂的算法,下面我们用它为例来进一步讲解 Spark 分区的使用。
如果有不清楚的 PageRank 算法的具体实现的可以参考我以前的一篇文章:hadoop下基于mapreduce实现pagerank算法
PageRank 是一个迭代算法,因此它是一个能从 RDD 分区中获得性能加速的很好的例子,先上代码:
// Assume that our neighbor list was saved as a Spark objectFile
val links = sc.objectFile[(String, Seq[String])]("links")
.partitionBy(new HashPartitioner(100))
.persist()
// Initialize each page's rank to 1.0; since we use mapValues, the resulting RDD
// will have the same partitioner as links
var ranks = links.mapValues(v => 1.0)
// Run 10 iterations of PageRank
for (i <- 0 until 10) {
val contributions = links.join(ranks).flatMap {
case (pageId, (links, rank)) =>
links.map(dest => (dest, rank / links.size))
}
ranks = contributions.reduceByKey((x, y) => x + y).mapValues(v => 0.15 + 0.85*v)
}
// Write out the final ranks
ranks.saveAsTextFile("ranks")
这个算法维护两个 RDD,一个的键值对是(pageID, linkList),包含了每个页面的出链指向的相邻页面列表(由 pageID 组成);另一个的键值对是(pageID, rank),包含了每个页面的当前权重值。算法流程如下:
- 将每个页面的权重值初始化为 1.0;
- 在每次迭代中,对页面 p,向其每个出链指向的页面加上一个 rank(p)/neighborsSize(p)的贡献值 contributionReceived;
- 将每个页面的权重值设置为:0.15 + 0.85 *contributionReceived。
不断迭代步骤 2 和 3,过程中算法会逐渐收敛于每个页面的实际 PageRank 值,实际运行之时大概迭代 10+ 次以上即可。
算法将 ranksRDD 的每个元素的值设置为 1.0,然后在每次迭代中不断更新 ranks 变量:首先对 ranksRDD 和静态的 linksRDD 进行一次 join()操作,来获取每个页面 ID 对应的相邻页面列表和当前的权重值,然后使用 flatMap 创建出『contributions』来记录每个页面对各相邻页面的贡献值。然后再把这些贡献值按照 pageID 分别累加起来,把该页面的权重值设为 0.15 + 0.85 * contributionsReceived。
接下来分析下上述代码做的的一些优化点:
- linksRDD 在每次迭代中都会和 ranks 发生连接操作,由于 links 是一个静态 RDD(数据几乎不会变动),所以在一开始可以对它进行分区以减少网络 shuffle,降低网络通信的开销。而且,linksRDD 的字节数一般来说也会比 ranks 大很多,因为这个 RDD 包含了每个页面的出链指向的页面列表,类似于一个笛卡尔积的数量级。所以通过预先分区可以获得比原算法的普通 MapReduce 实现更好的性能;
- 用 persist()方法缓存 RDD,使得在每次迭代里都可以复用,进一步提高性能;
- 第一次创建 ranks 时,使用 mapValues()而不是 map(),保留了父 RDD(links)的分区方式(因为 map 操作理论上可能会修改键值导致父 RDD 的分区不可用,所以 map 操作不保留父 RDD 的分区),这样第一次的 join()操作的开销也会更小;
- 在循环体中,调用 reduceByKey()后使用 mapValues();因为 reduceByKey()的结果已经是哈希分区的了,这样一来,下一次循环中将映射操作的结果再次与 links 进行连接时就会更加高效。
英文原文
https://www.safaribooksonline.com/library/view/learning-spark/9781449359034/ch04.html


