导言
I/O,一直以来都是操作系统中核心中的核心,从我们进入互联网时代以后,全世界的互联网用户爆发式地增长,一批又一批的提供互联网服务的大型跨国公司不断地崛起,它们承载了全世界百亿、千亿量级的网络流量,I/O 密集型的系统如网络服务器、数据库等逐渐占据了服务端领域,在海量的互联网用户面前,服务端的技术挑战不断涌现,网络服务器和数据库等系统的性能瓶颈愈发明显,而且大多数瓶颈都落在了 I/O 头上。Linux 作为有史以来应用最广泛的服务端操作系统,而且相较于 Windows、Solaris 等闭源操作系统,Linux 开放了其内核的全部源代码,这三十余年以来,全世界有无数的开发者参与其中,对 Linux 内核进行优化和修复,因此 Linux 的底层 I/O 技术发展史基本就等同于人类与计算机 I/O 的抗争史。
本文将分为两大部分,第一部分会深入浅出地剖析整个 Linux I/O 栈,带领读者从用户空间出发,进入内核空间,直达底层物理硬件,让读者能深刻地理解整个 Linux I/O 栈的层次结构、底层实现以及历史发展;第二部分则是基于第一部分的知识,揭示了 Linux 是如何在传统 I/O 模式中走出来并且万丈高楼平地起,直至手摘星辰,对 I/O 进行深度的改造从而实现 Zero-copy I/O,这部分内容会全方位地揭秘 Zero-copy (零拷贝) 这项技术,以及它是如何在 Linux I/O 栈上大放异彩,并成为绝大部分服务端高性能 I/O 的基石。
计算机存储设备
既然要分析 Linux I/O,就不能不了解计算机的各类存储设备。
存储设备是计算机的核心部件之一,在完全理想的状态下,存储设备应该要同时具备以下三种特性:
- 速度足够快:存储设备的存取速度应当快于 CPU 执行一条指令,这样 CPU 的效率才不会受限于存储设备。
- 容量足够大:容量能够存储计算机所需的全部数据。
- 价格足够便宜:价格低廉,所有类型的计算机都能配备。
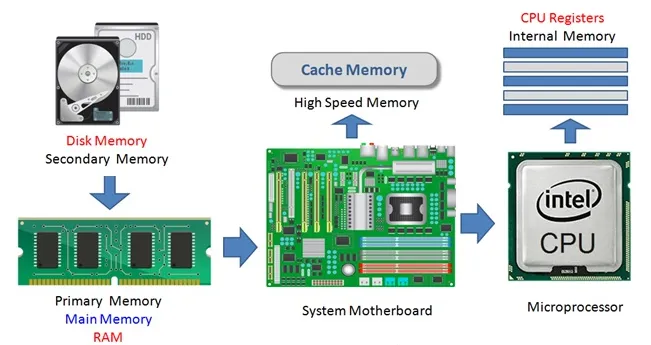
但是现实往往是残酷的,我们目前的计算机技术无法同时满足上述的三个条件 (这也算是一个不可能三角问题),于是现代计算机的存储设备设计采用了一种分层次的结构:
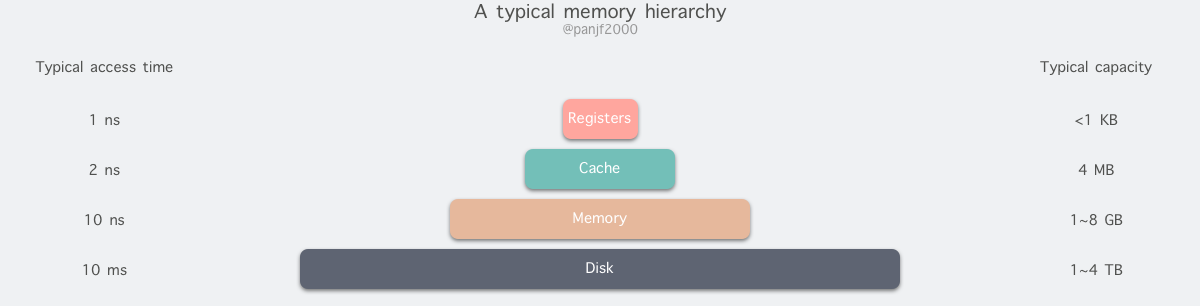
从顶至底,现代计算机里的存储设备类型分别有:寄存器、高速缓存、主存和磁盘,这些存储设备的速度逐级递减而容量逐级递增。存取速度最快的是寄存器,因为寄存器的制作材料和 CPU 是相同的,所以速度和 CPU 一样快,CPU 访问寄存器是没有时延的,然而因为价格昂贵,因此容量也极小,一般 32 位的 CPU 配备的寄存器容量是 32✖️32 Bit,64 位的 CPU 则是 64✖️64 Bit,不管是 32 位还是 64 位,寄存器容量都小于 1 KB,且寄存器也必须通过软件自行管理。
第二层是高速缓存,也即我们平时了解的 CPU 高速缓存 L1、L2、L3,一般 L1 是每个 CPU 独享,L3 是全部 CPU 共享,而 L2 则根据不同的架构设计会被设计成独享或者共享两种模式之一,比如 Intel 的多核芯片采用的是共享 L2 模式而 AMD 的多核芯片则采用的是独享 L2 模式。
第三层则是主存,也即主内存,通常称作随机访问存储设备 (Random Access Memory, RAM) 。是与 CPU 直接交换数据的内部存储设备。它可以随时读写 (刷新时除外) ,而且速度很快,通常作为操作系统或其他正在运行中的程序的临时资料存储介质。
最后则是磁盘,磁盘和主存相比,每个二进制位的成本低了两个数量级,因此容量比之会大得多,动辄上 GB、TB,而问题是访问速度则比主存慢了大概三个数量级。机械硬盘速度慢主要是因为机械臂需要不断在金属盘片之间移动,等待磁盘扇区旋转至磁头之下,然后才能进行读写操作,因此效率很低。
主内存是操作系统进行 I/O 操作的重中之重,绝大部分的工作都是在用户进程和内核的内存缓冲区里完成的,因此我们接下来需要提前学习一些主存的相关原理。
物理内存
我们平时一直提及的物理内存就是上文中对应的第三种计算机存储设备,RAM 主存,它在计算机中以内存条的形式存在,嵌在主板的内存槽上,用来加载各式各样的程序与数据以供 CPU 直接运行和使用。
虚拟内存
在计算机领域有一句如同摩西十诫般神圣的哲言:"计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决",从内存管理、网络模型、并发调度甚至是硬件架构,都能看到这句哲言在闪烁着光芒,而虚拟内存则是这一哲言的完美实践之一。
虚拟内存是现代计算机中的一个非常重要的存储设备抽象,主要是用来解决应用程序日益增长的内存使用需求:现代物理内存的容量增长已经非常快速了,然而还是跟不上应用程序对主存需求的增长速度,对于应用程序来说内存还是不够用,因此便需要一种方法来解决这两者之间的容量差矛盾。
计算机对多程序内存访问的管理经历了 静态重定位 --> 动态重定位 --> 交换(swapping)技术 --> 虚拟内存,最原始的多程序内存访问是直接访问绝对内存地址,这种方式几乎是完全不可用的方案,因为如果每一个程序都直接访问物理内存地址的话,比如两个程序并发执行以下指令的时候:
mov cx, 2
mov bx, 1000H
mov ds, bx
mov [0], cx
...
mov ax, [0]
add ax, ax
这一段汇编表示在地址 1000:0 处存入数值 2,然后在后面的逻辑中把该地址的值取出来乘以 2,最终存入 ax 寄存器的值就是 4,如果第二个程序存入 cx 寄存器里的值是 3,那么并发执行的时候,第一个程序最终从 ax 寄存器里得到的值就可能是 6,这就完全错误了,得到脏数据还顶多算程序结果错误,要是其他程序往特定的地址里写入一些危险的指令而被另一个程序取出来执行,还可能会导致整个系统的崩溃。所以,为了确保进程间互不干扰,每一个用户进程都需要实时知晓当前其他进程在使用哪些内存地址,这对于写程序的人来说无疑是一场噩梦。
因此,操作绝对内存地址是完全不可行的方案,那就只能用操作相对内存地址,我们知道每个进程都会有自己的进程地址,从 0 开始,可以通过相对地址来访问内存,但是这同样有问题,还是前面类似的问题,比如有两个大小为 16KB 的程序 A 和 B,现在它们都被加载进了内存,内存地址段分别是 0 ~ 16384,16384 ~ 32768。A 的第一条指令是 jmp 1024,而在地址 1024 处是一条 mov 指令,下一条指令是 add,基于前面的 mov 指令做加法运算,与此同时,B 的第一条指令是 jmp 1028,本来在 B 的相对地址 1028 处应该也是一条 mov 去操作自己的内存地址上的值,但是由于这两个程序共享了段寄存器,因此虽然他们使用了各自的相对地址,但是依然操作的还是绝对内存地址,于是 B 就会跳去执行 add 指令,这时候就会因为非法的内存操作而 crash。
有一种静态重定位的技术可以解决这个问题,它的工作原理非常简单粗暴:当 B 程序被加载到地址 16384 处之后,把 B 的所有相对内存地址都加上 16384,这样的话当 B 执行 jmp 1028 之时,其实执行的是 jmp 1028+16384,就可以跳转到正确的内存地址处去执行正确的指令了,但是这种技术并不通用,而且还会对程序装载进内存的性能有影响。
再往后,就发展出来了存储设备抽象:地址空间,就好像进程是 CPU 的抽象,地址空间则是存储设备的抽象,每个进程都会分配独享的地址空间,但是独享的地址空间又带来了新的问题:如何实现不同进程的相同相对地址指向不同的物理地址?最开始是使用动态重定位技术来实现,这是用一种相对简单的地址空间到物理内存的映射方法。基本原理就是为每一个 CPU 配备两个特殊的硬件寄存器:基址寄存器和界限寄存器,用来动态保存每一个程序的起始物理内存地址和长度,比如前文中的 A,B 两个程序,当 A 运行时基址寄存器和界限寄存器就会分别存入 0 和 16384,而当 B 运行时则两个寄存器又会分别存入 16384 和 32768。然后每次访问指定的内存地址时,CPU 会在把地址发往内存总线之前自动把基址寄存器里的值加到该内存地址上,得到一个真正的物理内存地址,同时还会根据界限寄存器里的值检查该地址是否溢出,若是,则产生错误中止程序,动态重定位技术解决了静态重定位技术造成的程序装载速度慢的问题,但是也有新问题:每次访问内存都需要进行加法和比较运算,比较运算本身可以很快,但是加法运算由于进位传递时间的问题,除非使用特殊的电路,否则会比较慢。
然后就是 交换 (swapping) 技术,这种技术简单来说就是动态地把程序在内存和磁盘之间进行交换保存,要运行一个进程的时候就把程序的代码段和数据段调入内存,然后再把程序封存,存入磁盘,如此反复。为什么要这么麻烦?因为前面那两种重定位技术的前提条件是计算机内存足够大,能够把所有要运行的进程地址空间都加载进主存,才能够并发运行这些进程,但是现实往往不是如此,内存的大小总是有限的,所有就需要另一类方法来处理内存超载的情况,第一种便是简单的交换技术:
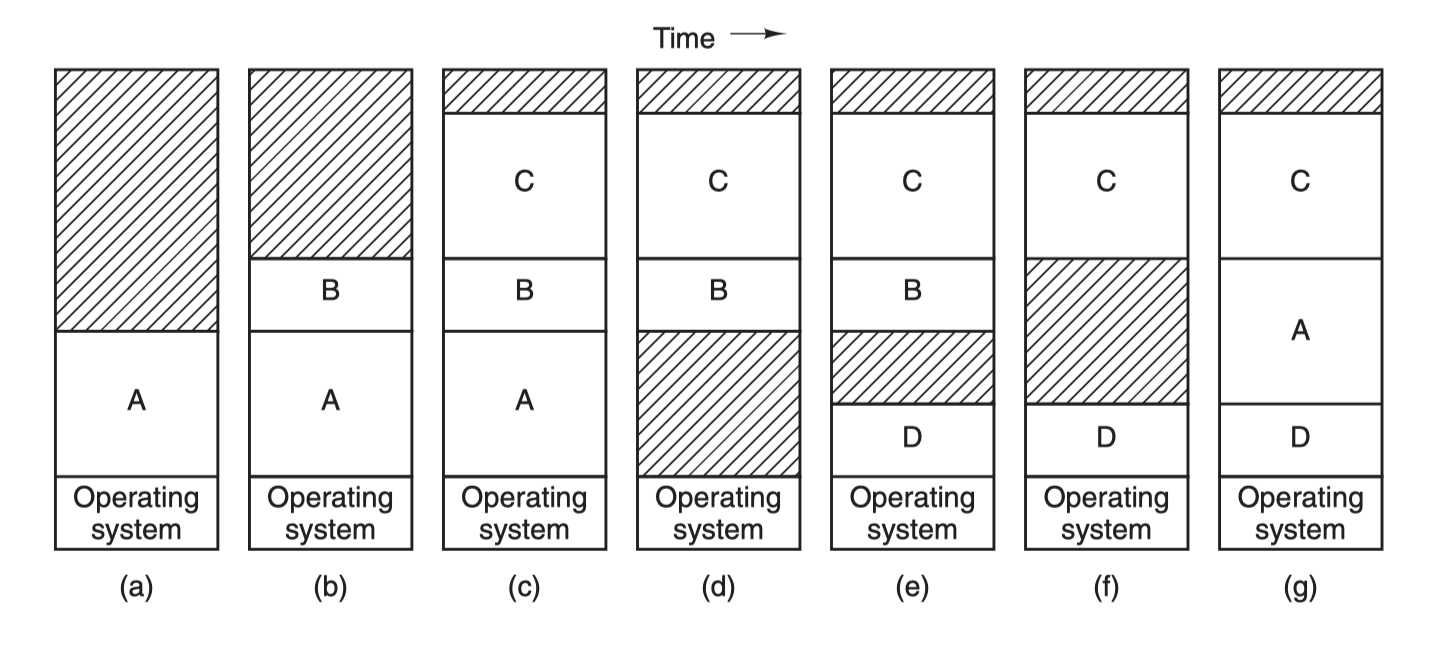
先把进程 A 换入内存,然后启动进程 B 和 C,也换入内存,接着 A 被从内存交换到磁盘,然后又有新的进程 D 调入内存,用了 A 退出之后空出来的内存空间,最后 A 又被重新换入内存,由于内存布局已经发生了变化,所以 A 在换入内存之时会通过软件或者在运行期间通过硬件 (基址寄存器和界限寄存器) 对其内存地址进行重定位,多数情况下都是通过硬件。
另一种处理内存超载的技术就是虚拟内存技术了,它比交换 (swapping) 技术更复杂而又更高效,是目前最新应用最广泛的存储设备抽象技术。虚拟内存的核心原理是:为每个程序设置一段"连续"的虚拟地址空间,把这个地址空间分割成多个具有连续地址范围的页 (page),并把这些页和物理内存做映射,在程序运行期间动态映射到物理内存。当程序引用到一段在物理内存的地址空间时,由硬件立刻执行必要的映射;而当程序引用到一段不在物理内存中的地址空间时,由操作系统负责将缺失的部分装入物理内存并重新执行失败的指令:
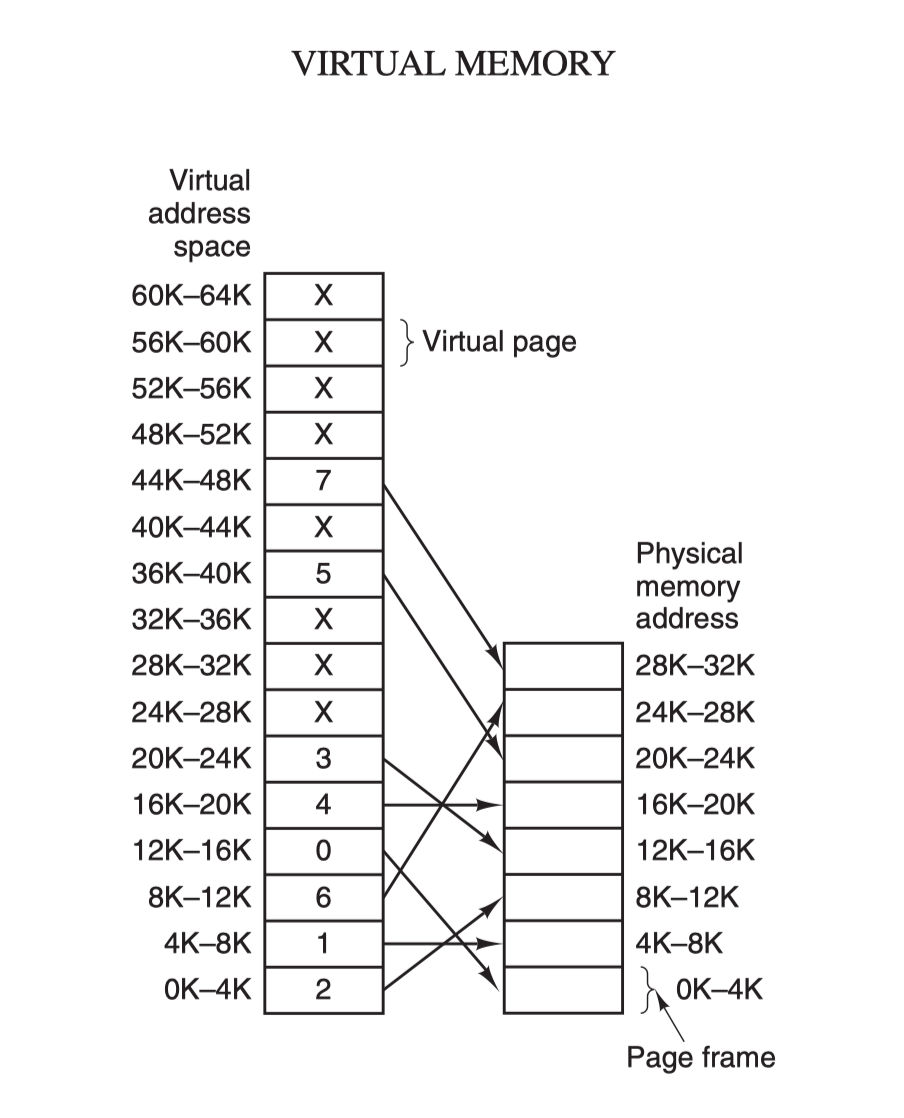
虚拟地址空间按照固定大小划分成被称为页 (page) 的若干单元,物理内存中对应的则是页框 (page frame) 。这两者一般来说是一样的大小,如上图中的是 4KB,不过实际上计算机系统中一般是 512 字节到 1 GB,这就是虚拟内存的分页技术。因为是虚拟内存空间,每个进程分配的大小是 4 GB (32 位架构),而实际上当然不可能给所有在运行中的进程都分配 4 GB 的物理内存,所以虚拟内存技术还需要利用到前面介绍的交换 (swapping) 技术,在进程运行期间只分配映射当前使用到的内存,暂时不使用的数据则写回磁盘作为副本保存,需要用的时候再读入内存,动态地在磁盘和内存之间交换数据。
其实虚拟内存技术从某种角度来看的话,很像是糅合了基址寄存器和界限寄存器之后的新技术。它使得整个进程的地址空间可以通过较小的单元映射到物理内存,而不需要为程序的代码和数据地址进行重定位。
进程在运行期间产生的内存地址都是虚拟地址,如果计算机没有引入虚拟内存这种存储设备抽象技术的话,则 CPU 会把这些地址直接发送到内存地址总线上,直接访问和虚拟地址相同值的物理地址;如果使用虚拟内存技术的话,CPU 则是把这些虚拟地址通过地址总线送到内存管理单元 (Memory Management Unit,MMU) ,MMU 将虚拟地址映射为物理地址之后再通过内存总线去访问物理内存:
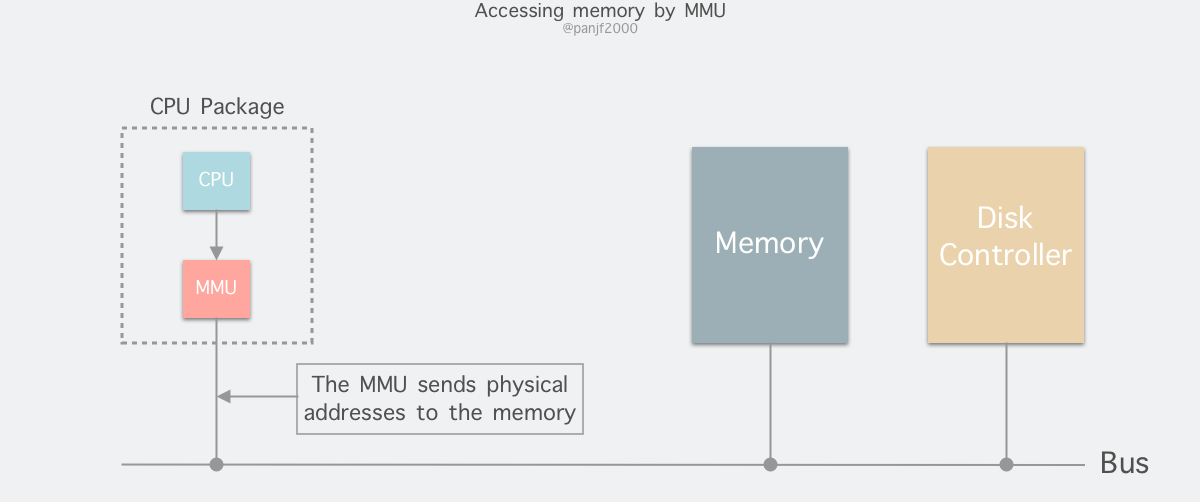
虚拟地址 (比如 16 位地址 8196=0010 000000000100) 分为两部分:虚拟页号 (高位部分) 和偏移量 (低位部分) ,虚拟地址转换成物理地址是通过页表 (page table) 来实现的,每个用户进程都有自己的虚拟地址空间以及独立的页表。页表由页表项构成,页表项中保存了页框号、修改位、访问位、保护位和 "在/不在" 位等信息,从数学角度来说页表就是一个函数,入参是虚拟页号,输出是物理页框号,得到物理页框号之后复制到寄存器的高三位中,最后直接把 12 位的偏移量复制到寄存器的末 12 位构成 15 位的物理地址,即可以把该寄存器的存储的物理内存地址发送到内存总线:
![]()
在 MMU 进行地址转换时,如果页表项的 "在/不在" 位是 0,则表示该页面并没有映射到真实的物理页框,则会引发一个缺页中断,CPU 陷入操作系统内核,接着操作系统就会通过页面置换算法选择一个页面将其换出 (swap),以便为即将调入的新页面腾出位置,如果要换出的页面的页表项里的修改位已经被设置过,也就是被更新过,则这是一个脏页 (dirty page),需要写回磁盘更新改页面在磁盘上的副本,如果该页面是"干净"的,也就是没有被修改过,则直接用调入的新页面覆盖掉被换出的旧页面即可。
最后,还需要了解的一个概念是转换检测缓冲器 (Translation Lookaside Buffer,TLB) ,也叫快表,是用来加速虚拟地址映射的,因为虚拟内存的分页机制,页表一般是保存内存中的一块固定的存储区,导致进程通过 MMU 访问内存比直接访问内存多了一次内存访问,性能至少下降一半,因此需要引入加速机制,即 TLB 快表,TLB 可以简单地理解成页表的高速缓存,保存了最高频被访问的页表项,由于一般是硬件实现的,因此速度极快,MMU收到虚拟地址时一般会先通过硬件 TLB 查询对应的页表号,若命中且该页表项的访问操作合法,则直接从 TLB 取出对应的物理页框号返回,若不命中则穿透到内存页表里查询,并且会用这个从内存页表里查询到最新页表项替换到现有 TLB 里的其中一个,以备下次缓存命中。
至此,我们介绍完了包含虚拟内存在内的多项计算机存储设备抽象技术,虚拟内存的其他内容比如针对大内存的多级页表、倒排页表,以及处理缺页中断的页面置换算法等等,这里就不再深入了,我后来写过一篇更加深入的文章,有兴趣的读者可以前往阅读。
用户态与内核态
一般来说,我们在编写程序操作 Linux I/O 之时十有八九是在用户空间和内核空间之间传输数据,因此有必要先了解一下 Linux 的用户态和内核态的概念。
内核空间
首先是用户态和内核态1:
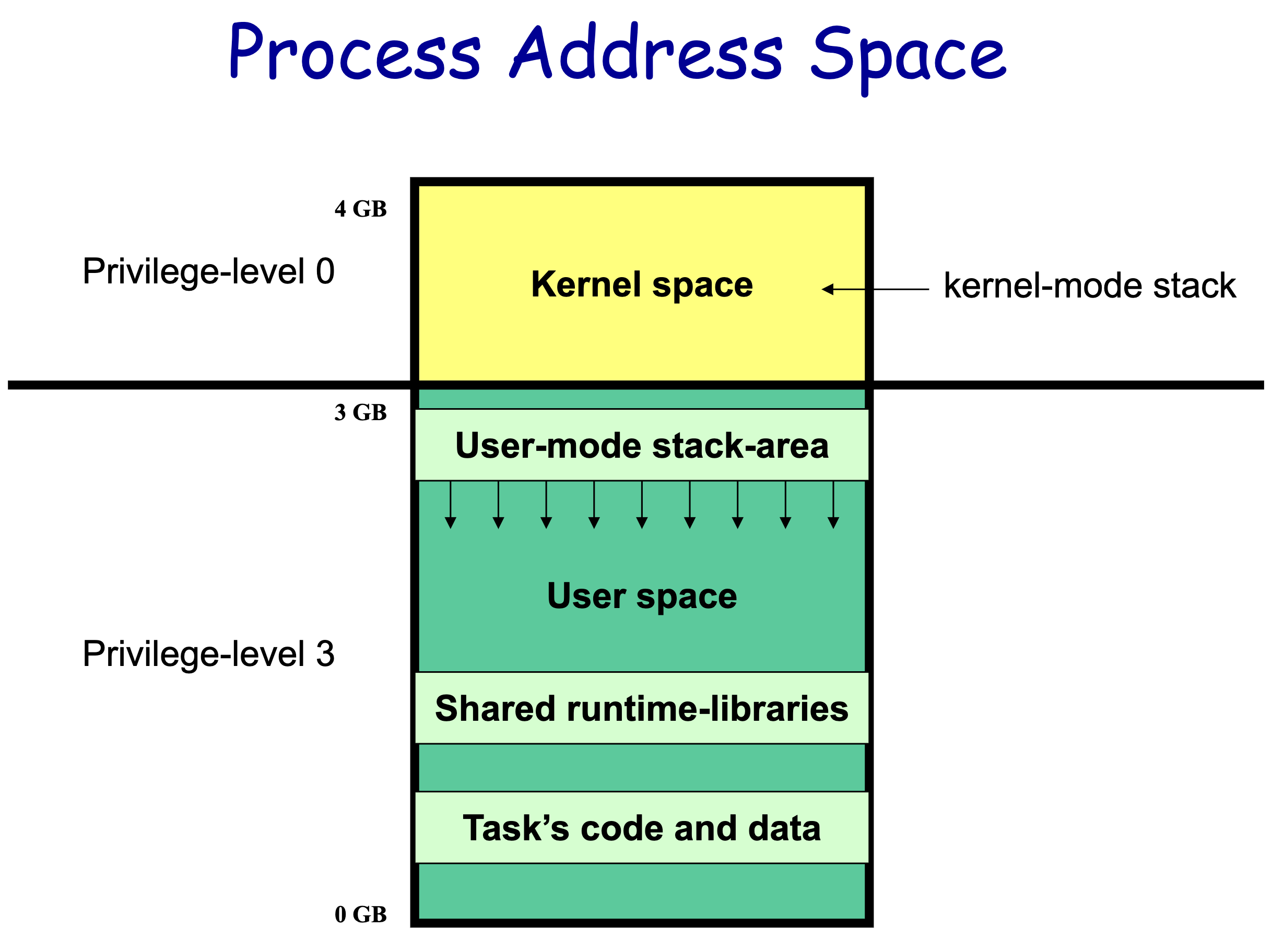
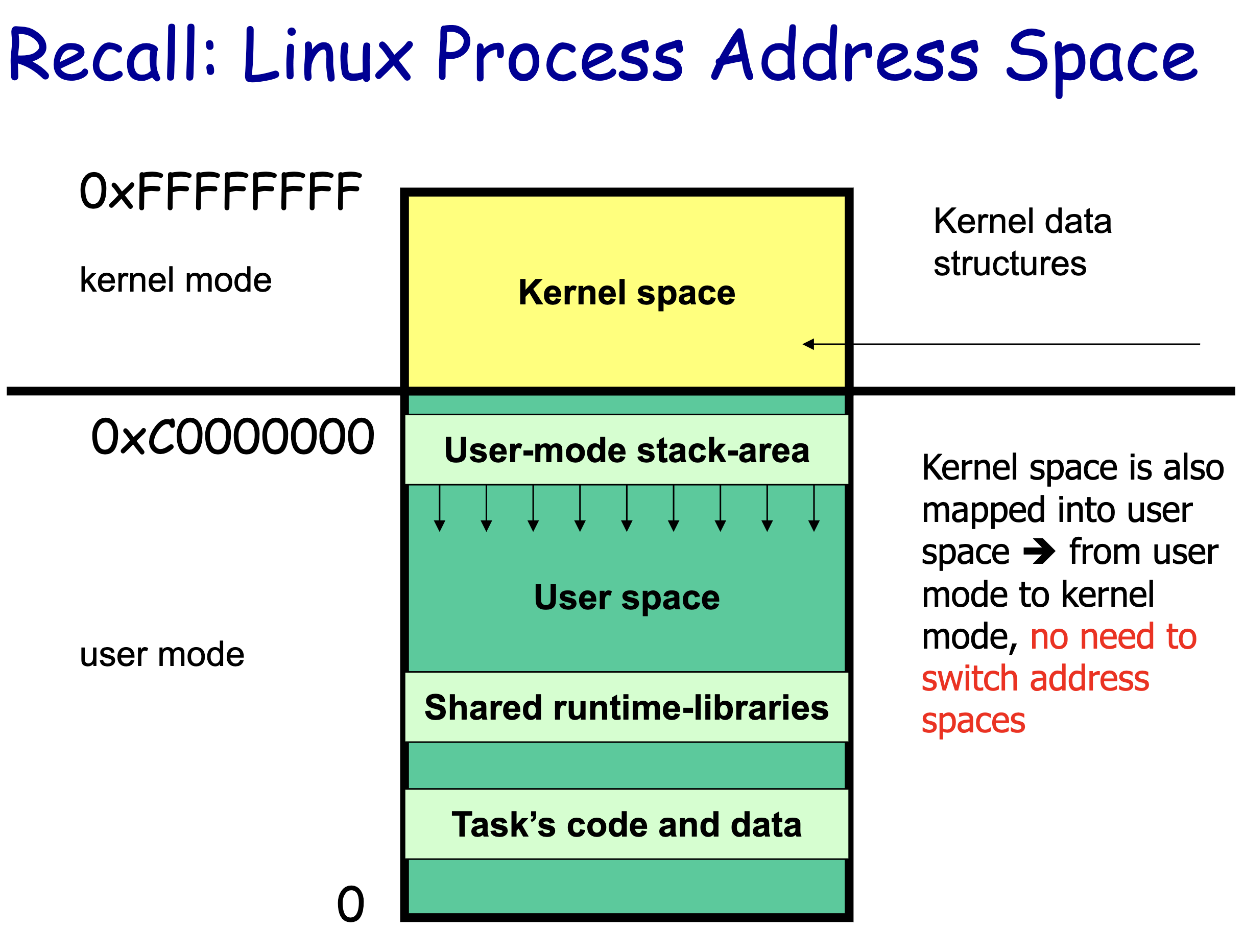
从宏观上来看,Linux 操作系统的体系架构分为用户态和内核态 (或者用户空间和内核) 。内核从本质上看是一种软件 —— 控制计算机的硬件资源,并提供上层应用程序 (进程) 运行的环境。用户态即上层应用程序 (进程) 的运行空间,应用程序 (进程) 的执行必须依托于内核提供的资源,这其中包括但不限于 CPU 资源、存储资源、I/O 资源等等。
现代操作系统都是采用虚拟地址空间,那么对 32 位操作系统而言,它的寻址空间 (虚拟存储空间) 为 232 B = 4 GB。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核 (kernel) ,保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对 Linux 操作系统而言,将最高的 1G 字节 (从虚拟地址 0xC0000000 到 0xFFFFFFFF) ,供内核使用,称为内核空间,而将较低的 3G 字节 (从虚拟地址 0x00000000 到 0xBFFFFFFF) ,供各个进程使用,称为用户空间。
因为操作系统的资源是有限的,如果访问资源的操作过多,必然会消耗过多的系统资源,而且如果不对这些操作加以区分,很可能造成资源访问的冲突。所以,为了减少有限资源的访问和使用冲突,Unix/Linux 的设计哲学之一就是:对不同的操作赋予不同的执行等级,就是所谓特权的概念。简单说就是有多大能力做多大的事,与系统相关的一些特别关键的操作必须由最高特权的程序来完成。Intel 的 x86 架构的 CPU 提供了 0 到 3 四个特权级,数字越小,特权越高,Linux 操作系统中主要采用了 0 和 3 两个特权级,分别对应的就是内核态和用户态。运行于用户态的进程可以执行的操作和访问的资源都会受到极大的限制,而运行在内核态的进程则可以执行任何操作并且在资源的使用上没有限制。很多程序开始时运行于用户态,但在执行的过程中,一些操作需要在内核权限下才能执行,这就涉及到一个从用户态切换到内核态的过程。比如 C 函数库中的内存分配函数 malloc(3),它具体是使用 sbrk(2) 系统调用来分配内存,当 malloc(3) 调用 sbrk() 的时候就涉及一次从用户态到内核态的切换,类似的函数还有 printf(3),调用的是 wirte(2) 系统调用来输出字符串,等等。
用户进程在系统中运行时,大部分时间是处在用户态空间里的,在其需要操作系统帮助完成一些用户态没有特权和能力完成的操作时就需要切换到内核态。那么用户进程如何切换到内核态去使用那些内核资源呢?答案是:1) 系统调用 (trap) ,2) 异常 (exception) 和 3) 中断 (interrupt) 。
- 系统调用:用户进程主动发起的操作。用户态进程发起系统调用主动要求切换到内核态,陷入内核之后,由操作系统来操作系统资源,完成之后再返回到进程。
- 异常:被动的操作,且用户进程无法预测其发生的时机。当用户进程在运行期间发生了异常 (比如某条指令出了问题) ,这时会触发由当前运行进程切换到处理此异常的内核相关进程中,也即是切换到了内核态。异常包括程序运算引起的各种错误如除 0、缓冲区溢出、缺页等。
- 中断:当外围设备完成用户请求的操作后,会向 CPU 发出相应的中断信号,这时 CPU 会暂停执行下一条即将要执行的指令而转到与中断信号对应的处理程序去执行,如果前面执行的指令是用户态下的程序,那么转换的过程自然就会是从用户态到内核态的切换。中断包括 I/O 中断、外部信号中断、各种定时器引起的时钟中断等。中断和异常类似,都是通过中断向量表来找到相应的处理程序进行处理。区别在于,中断来自处理器外部,不是由任何一条专门的指令造成,而异常是执行当前指令的结果。
内存分区
前面已经说过了内核空间和用户空间的分区情况,内核虽然只分配到了整块物理内存中的一部分,但是它却可以访问所有物理内存,然而因为硬件的限制,内核通常无法对系统中的所有内存页都进行无差别的管理。有些页位于内存中特定的物理地址上,所以不能将其用于某些特定的任务。由于存在这些限制,内核把其所有的内存页划分为不同的区 (zone)。内核使用 zone 将那些具有相似特性的内存页进行分组。Linux 必须处理如下两种由于硬件缺陷而导致的内存寻址问题:
- 一些硬件只能用某些特定的内存地址来执行 DMA (Direct Memory Access,直接内存访问)。
- 一些体系结构上的内存的物理寻址范围要比虚拟寻址范围更加大,这就导致溢出的那部分物理内存无法永久性地直接映射到内核空间上。
基于以上的限制,Linux 在管理整个物理内存时将其划分成六个区2:
- ZONE_DMA —— 这个区的内存页是用来执行外围设备的 DMA 操作的,目前已经有很多其他比 ZONE_DMA 更好的方式可以执行 DMA了,所以这个区已经是历史遗留的技术了,可以通过
CONFIG_ZONE_DMA配置项在编译内核的时候关闭这个区。 - ZONE_DMA32 —— 这个区和 ZONE_DMA 类似,它的内存页可用来执行 DMA;但是这个区只能被 32 位的设备访问,在某些体系结构中这个区可能比 ZONE_DMA 更大。同样的,可以通过
CONFIG_ZONE_DMA32配置项在编译内核的时候关闭这个区。 - ZONE_NORMAL —— 这个区的内存页都是可以进行永久性直接映射的,也可以用来执行某些特定的 DMA。
- ZONE_HIGHMEM —— 这个区的内存页被称之为"高端内存",这些内存页只能进行临时映射而不能像 ZONE_NORMAL 那样进行永久性直接映射。这个区只用于一些特定的 32 位的系统,如 i386。
- ZONE_MOVABLE —— 和 ZONE_NORMAL 类似,但是其中的内存页是可移动的,也就是说其内存页的虚拟内存地址是不变的,但是物理内存地址可能会被移动。
- ZONE_DEVICE —— 这个区的内存页主要为某些特定的设备服务,比如 GPU。
内存区的实际使用和布局是与体系架构紧密相关的。比如,在某些体系架构中,内存的任何地址都可以执行 DMA,此时 ZONE_DMA 是空的,ZONE_NORMAL 负责内核中所有的内存分配。又比如,在 i386 架构上,ISA 设备被禁止在整个 32 位的地址空间中执行 DMA,因为 ISA 设备只能访问物理内存前 16MB 的地址。所以,ZONE_DMA 在 i386 架构上就位于 0~16MB 的内存范围中。
ZONE_HIGHMEM 的工作原理也差不多,临时映射还是直接映射完全取决于体系架构:在 i386 架构上,ZONE_HIGHMEM 的分布范围是高于 896MB 的全部内存区域。下图是 Linux 内核团队给出的 x86 架构下 2 GB 物理内存的布局2:
0 2G
+-------------------------------------------------------------+
| node 0 |
+-------------------------------------------------------------+
0 16M 896M 2G
+----------+-----------------------+--------------------------+
| ZONE_DMA | ZONE_NORMAL | ZONE_HIGHMEM |
+----------+-----------------------+--------------------------+
而在其他的体系架构上,基本上可以说所有 64 位的架构,还有一些 32 位的架构,所有物理内存都可以被直接映射到虚拟内存上,这是因为 64 位架构的地址空间范围足够大,理论上不会出现虚拟地址范围不足以完全映射所有物理地址的情况,因此在这些架构上 ZONE_HIGHMEM 这个区是空的。ZONE_HIGHMEM 所在的内存区域就是所谓的高端内存 (high memory),剩下的内存即是低端内存 (low memory)。需要注意的是,高端内存是内核空间的概念,用户空间没有这个说法。
系统布局
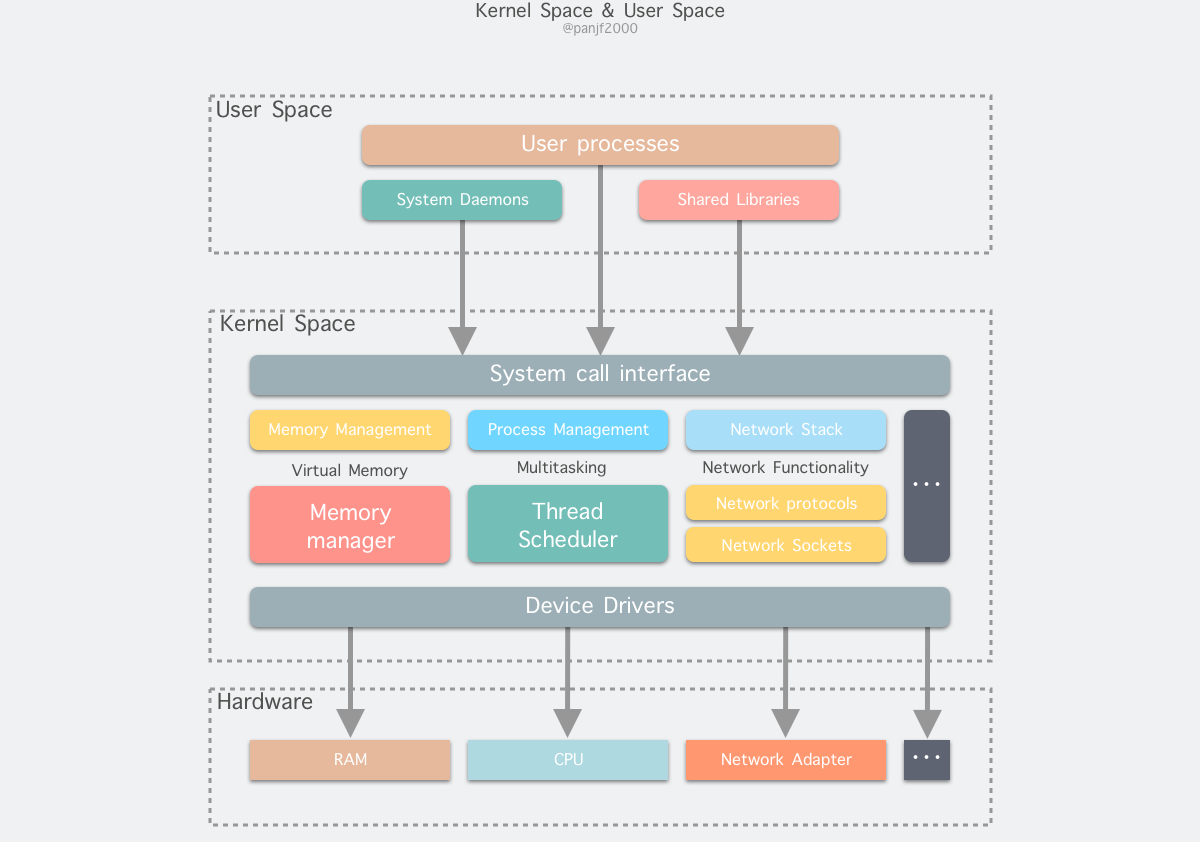
通过上面的分析,我们可以得出 Linux 系统的总体布局可分为三大部分:
- 用户空间;
- 内核空间;
- 硬件层。
Linux I/O Stack

研究过 Linux I/O 底层的同学们应该对上面这张图不陌生,这张图就是大名鼎鼎的 "Linux Storage Stack Diagram",由 Werner Fischer 制作3。这张图清晰明了地展示了 Linux 整个底层存储栈的布局。
这张图使用了不同的颜色来区分组件 (从下往上) :
- 浅蓝色:硬件存储设备
- 橙色:数据传输协议 (SCSI)
- 蓝色:Linux 系统的设备文件
- 黄色:I/O 调度队列
- 橙黄色:I/O 调度算法
- 蓝绿色:Linux I/O 操作的基本数据结构 bio
- 绿色:Linux 挂载的文件系统
上图是最经典的版本,基于内核 v4.10 的,下面的图片是最新的版本,基于内核 v6.9 。

上面的图对 Linux I/O 栈的概括是比较全面和详细的,但是乍一看可能会让人眼花缭乱,我们可以对其进行进一步的概括和简略,下面是简化版的 Linux I/O Stack 全景图4:
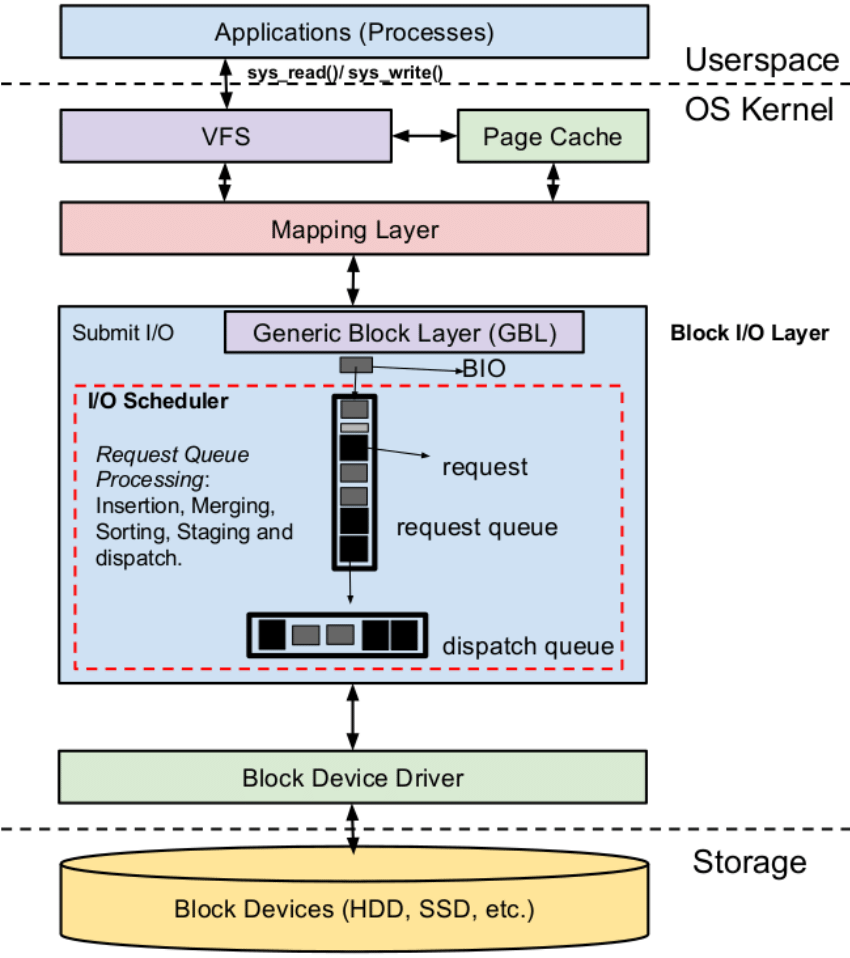
Linux I/O 栈可以说是一个庞然大物,想要在一篇文章中全面而又深入地讲解完是不可能的任务。因此,本文决定按照上面这张简化版的架构图进行讲解,我尽量兼顾广度和深度进行分析,希望能给读者们一个归纳总结出一个关于 Linux I/O 的轮廓,为以后继续深入研究这方面的知识打下一个基础。
虚拟文件系统 (VFS)
Virtual File System 虚拟文件系统是一个位于 Linux 内核的软件层,它为用户空间的程序提供标准的文件系统接口,它同时也是内核的一个抽象层,屏蔽了不同的实际文件系统的实现细节,让这些文件系统可以接入内核并在其中共存5。
一个操作系统至少需要有一个标准的文件系统,用来处理系统上的各种文件,比如 Linux 上自带的 Ext2/3/4 等文件系统。操作系统的标准文件系统对于大部分用户程序和使用场景来说是通常是足够的,然而也会有满足不了用户需求的时候。或因为性能、或因为可靠性等等,这个时候就需要操作系统提供一种能够让用户替换掉标准文件系统的机制。为了支持当前操作系统的多种文件系统,而且同时还能支持访问其他操作系统的文件系统,Linux 内核在用户进程 (或者说 C 标准库) 和文件系统之间引入了一个抽象层 —— 虚拟文件系统 (Virtual File System, VFS) 。虚拟文件系统是一个内核子系统,其主要的作用是为用户空间的程序提供文件和文件系统相关的接口。系统中的所有文件不但依赖于 VFS 共存,而且也需要依靠 VFS 来协同工作。通过 VFS,用户空间的程序可以利用标准的 Unix 系统调用对不同的文件系统,甚至是不同存储介质上的文件系统进行 I/O 操作。
VFS 深度集成在 Linux I/O 栈中,它之所以能支持各种不同的文件系统,是因为它定义了一系列标准的接口和数据结构,任何想接入 VFS 的实际文件系统都需要实现这些接口和数据结构,然后将所有来自用户态的 I/O 操作都重定向到当前 VFS 接入的实际文件系统的对应实现,借助 VFS 的各种数据结构,最后与块设备 (Block Device) 进行交互从而读写数据。
Unix 使用了四种和文件系统相关的传统抽象概念:文件 (file)、目录项 (dentry)、索引节点 (inode) 和挂载点 (mount point)。本质上讲文件系统是特殊的数据分层存储结构,其中包含了文件、目录和相关的控制信息。文件系统的通用操作包括创建、删除和挂载等。在 Unix 中,文件系统被挂载在全局分层结构中一个特定的 mount point 上,这个 mount point 被称为命名空间 (namespace),所有已挂载的文件系统都作为根文件系统树的树枝 (入口) 而存在。
文件系统类型 (Filesystem Types)
正如 "The Linux Storage Stack Diagram" 图中所示,VFS 支持的文件系统大致可以归纳为以下几种6:
- 基于块设备的文件系统 (Block-based FS):ext2/3/4, btrfs, xfs, ifs, iso9660, gfs, ocfs, etc.
- 基于物理硬件存储设备的文件系统,通常用于以连续的块为存储单位的块设备,支持随机 I/O。
- 网络文件系统 (Network FS):NFS, coda, smbfs, ceph, etc.
- 也叫分布式文件系统 (Distributed FS),其中的文件(设备)分布在不同位置,通过网络进行通信,但是就像访问本地磁盘文件一样,一般会用 ACL 鉴权。
- 伪文件系统 (Pseudo FS):proc, sysfs, pipefs, futexfs, usbfs, etc.
- 这是一种基于"虚拟文件"的文件系统,在这种文件系统中的"虚拟文件"的树状结构会和那些基于磁盘的文件系统中的文件一样,也可以通过系统调用或者其他能够操作磁盘文件的工具对这些"虚拟文件"进行操作,所以被称为伪文件系统。它们以文件系统的方式为使用者提供了访问操作系统和硬件的层次化接口。
- 堆栈式文件系统 (Stackable FS):ecryptfs, overlayfs, unionfs, wrapfs, etc.
- 这是一种本身并不存储数据,而叠加在其他文件系统之上的一种文件系统,这一类文件系统通常会利用下层的文件系统来实现数据存储。
- 文件系统接口 (File system interfaces):FUSE, LUFS, PUFFS, etc.
- 严格来说这不是真正的文件系统,而是一种接口,它提供了一种可以不用修改内核的方式实现文件系统:通过在用户空间运行文件系统的代码。用户空间文件系统相比内核文件系统更加灵活,但性能通常更低。
- 特殊用途文件系统 (Special Purpose FS):tmpfs, ramfs, devtmpfs, etc.
- 上述的 pseudo FS、stackable FS 和 file system interfaces 其实都归属在这一类文件系统中。或者说基本上所有的不是基于磁盘和网络的文件系统都属于特殊用途文件系统。这种文件系统的主要用于计算机进程之间的通信或者用作临时文件空间。所以这一类的文件系统通常使用内存而不是磁盘作为它的后端存储设备,但是操作起来就像是在操作磁盘。
底层实现
VFS 实际上是使用面向对象 (OOP) 思想来实现的,使用一组数据结构来代表通用文件对象,这些数据结构类似于对象。因为 Linux 内核是使用纯 C 实现的,所以内核中的数据结构都是用 C 语言的结构体来定义和实现,而这些结构体包含数据的同时也包含操作这些数据的函数指针,其中的操作函数有具体的文件系统实现。
VFS 中的主要的对象和数据结构定义在这里:<include/linux/fs.h>
- superblock: 超级块对象,代表一个已挂载的具体文件系统,存储文件系统的元信息。
- inode: 索引节点对象,代表一个文件,存储文件的元信息。
- dentry: 目录项对象,代表一个目录项,是文件路径的其中一个组成部分。
- file: 文件对象,代表由进程打开的一个文件。
需要注意的是,因为在 Unix 的万物皆文件的设计理念,所以 VFS 中并没有目录的概念,而是将目录也作为一个文件来处理,所以只有文件对象,而没有目录对象。目录项对象代表的是文件路径中的一个组成部分,它可能包含一个普通文件,所以目录项不是目录,目录只是一种特殊的文件。
VFS 的每一个主要对象都会包含一个操作对象,这些操作对象描述了内核针对 VFS 的主要对象可以使用的方法:
- super_operations 对象,其中包含内核针对特定文件系统所能调用的方法,比如
write_inode()和sync_fs()等。 - inode_operations 对象,其中包含内核针对特定文件所能调用的方法,比如
create()和link()等。 - dentry_operations 对象,其中包含内核针对特定目录项所能调用的方法,比如
d_compare()和d_delete()等。 - file_operations 对象,其中包含进程针对已打开文件所能调用的方法,比如
read()和write()等。
操作对象是基于结构体指针来实现的,该结构体中包含指向操作其父对象的函数指针。对于其中的很多方法来说,可以集成使用 VFS 提供的通用函数,如果通用函数提供的基本功能无法满足需求,那么就必须使用实际的文件系统的它自己的特定实现来装填这些指针。
超级块 (SUPERBLOCK)
超级块是一个结构,它代表一个文件系统实例,也就是一个挂载的文件系统。超级块定义在 <include/linux/fs.h> 中。这个结构体非常大,下面挑出一些比较重要字段来展示:
struct super_block {
struct list_head s_list; // 指向所有其他相同文件系统类型的超级块的链表。
dev_t s_dev; // 设备标识符
unsigned long s_blocksize; // 块大小,以 byte 为单位
loff_t s_maxbytes; // 块大小,以 bit 为单位
struct file_system_type *s_type; // 文件系统类型,包括名字、属性和其他信息
const struct super_operations *s_op; // 内核可以调用的超级块方法
uuid_t s_uuid; // 这个文件系统的唯一标识 UUID
struct list_head s_inodes; // 这个文件系统中的所有 inodes 列表
unsigned long s_magic; // 文件系统的魔数
struct dentry *s_root; // 目录挂载点
int s_count; // 超级块的引用计数
void *s_fs_info; // 文件系统的一些特殊信息
const struct dentry_operations *s_d_op; // 目录项的默认操作对象
...
};
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
void (*destroy_inode)(struct inode *);
void (*free_inode)(struct inode *);
void (*dirty_inode) (struct inode *, int flags);
int (*write_inode) (struct inode *, struct writeback_control *wbc);
int (*drop_inode) (struct inode *);
void (*evict_inode) (struct inode *);
void (*put_super) (struct super_block *);
int (*sync_fs)(struct super_block *sb, int wait);
int (*freeze_super) (struct super_block *, enum freeze_holder who);
int (*freeze_fs) (struct super_block *);
int (*thaw_super) (struct super_block *, enum freeze_holder who);
int (*unfreeze_fs) (struct super_block *);
int (*statfs) (struct dentry *, struct kstatfs *);
int (*remount_fs) (struct super_block *, int *, char *);
void (*umount_begin) (struct super_block *);
...
};
不同类型的文件系统想要挂载到 Linux 中都必须实现超级块对象,该对象用于存储特定文件系统的信息以及描述该文件系统,它通常对应于存放在磁盘特定扇区中的文件系统超级块或文件系统控制块 (这也是"超级块"的名字由来) 。对于那些不是基于磁盘的文件系统 (比如基于虚拟内存的文件系统,比如 sysfs) ,它们会实时生成超级块对象并存储在内存中。
超级块通常存储在存储设备本身,并在挂载时加载到内存中。创建、管理和撤销超级块对象的代码位于 fs/super.c 里。超级块对象通过 alloc_super() 函数创建并初始化。文件系统会在装载的时候调用这个函数从磁盘读取其对应的超级块并加载进内存中的超级块对象中。
接下来我讲解一下 super_block 结构体中几个比较重要的字段:首先是 s_list,它是一个指向系统中所有其他相同类型的文件系统的超级块的链表;然后是 s_inodes 是一个包含了本文件系统中所有 inodes 的列表;最后 super_block 中最重要的一个成员:s_op,它是一个 super_operations 类型的指针,其所指向的结构体包含了一组能操作超级块的函数,也可以理解成是超级块的函数操作表。这个 super_operations 结构体是最能体现 VFS 的抽象化设计的例子:通过定义一系列可以操作超级块的函数指针并要求不同的文件系统实现这些函数 (可以理解成是编程接口),从而屏蔽了不同文件系统的底层实现细节,使得 VFS 能作为一个通用的抽象层对接各式各样的文件系统。后面会介绍的 inode、dentry 和 file 对象所对应的 inode_operations、dentry_operations 和 file_operations 也是一样的原理。这些函数操作表中的回调函数就是每一个具体的文件系统的提供给 VFS 的功能,比如读、写、删除文件等等。
现在我们来看一下 super_operations 中几个比较有代表性的函数,以求管中窥豹,从而对超级块的操作有一个初步的了解,未来才可以更加深入地学习这一部分的知识。结构体中的每一项都是一个指向超级块操作函数的指针,超级块操作函数可以执行文件系统和它的 inode 索引节点的底层操作。每当文件系统需要对其超级块进行操作时,首先要在超级块对象中查询对应的操作函数。比如,如果文件系统要写自己的超级块,则调用 sb->s_op->write_super(sb),这个函数是用来将内存中的最新的超级块更新到磁盘中持久化,VFS 通过这个函数对内存和磁盘中的超级块进行同步。sb 是 super_block 结构体指针,通过它的 s_op 指针调用 super_operations 中的函数完成所需的操作。需要注意的是,因为 Linux 内核是纯 C 实现的,缺乏面向对象的原生支持,被调用的函数无法直接访问到调用方 super_block,因此 super_operations 中的每一个需要用到 super_block 的函数指针的签名都必须加上这个结构体的入参。
还有一点,关于 write_super() 这个函数,已经在内核 3.6 中被移除了7 (但是原理是一样,所以不影响我们分析这些函数回调的原理)。这个函数一开始只是提供给内核的 sync_supers 线程使用的,这个线程的职责是定期唤醒自己 (每 5 秒) 然后遍历系统中的所有超级块,找出那些"脏"超级块 (也就是那些内存中已更新但是还没有同步到磁盘的超级块) ,调用具体文件系统实现的 write_super() 将内存中的更新同步到磁盘。这个机制的问题是大多数时候系统中的超级块是没有更新的,所以这个线程多数时候是在空转,导致 CPU 占用率飙升,浪费系统资源。而且大多数现代的文件系统比如 btrfs 和 ext4 甚至都没有实现和注册这个函数到内核中,导致 write_super() 这个函数基本没什么用,只是为了兼容一些比较旧的文件系统才一直保留,后来内核团队在确保已经没有新的文件系统会使用这个函数之后就移除了这个机制。在此之前,当文件系统的超级块在内存中更新之后需要同步到磁盘,只需要将超级块标记成"脏" (通过设置 super_operations 中的 s_dirt 标识,这个字段也被一起移除了) ,然后 sync_supers 线程就会定期把这些超级块同步到磁盘,从 v3.6 之后所有文件系统都需要自己管理超级块的更新同步。
关于 super_operations 中每一个函数功能的详细介绍请参考官方文档8,文档里已经都有介绍了,这里便不再赘述。
索引节点对象 (INODE)
inode, 是 index node 的缩写,也就是索引节点。索引节点表示文件系统中的一个对象,每个对象都有一个唯一的 id。inode 对象包含了内核在操作文件或目录时需要的全部的信息,文件的 inode 包含指向文件内容的数据块的指针,目录索引节点包含指向存储名称 —— 索引节点关联的块的指针。索引节点上的操作允许修改其属性和读取/写入其数据。
文件系统中的对象类型通常有以下几种:
- socket
- symbolic link
- regular file
- block device
- directory
- character device
- FIFO
所有文件系统中管理的任何对象类型的每个对象都存在一个对应的 inode 实例。inode 被定义在 <include/linux/fs.h> 中。
struct inode {
umode_t i_mode; // 访问权限,比如可读或者可写
kuid_t i_uid; // 所有者的用户 ID
kgid_t i_gid; // 所有者所在的组 ID
unsigned int i_flags; // 文件系统标识
const struct inode_operations *i_op; // inode 操作函数
struct super_block *i_sb; // 所在的超级块
struct address_space *i_mapping; // 相关的地址映射
unsigned long i_ino; // 唯一标识这个 inode 的号码
const unsigned int i_nlink; // 硬链接数
dev_t i_rdev; // 设备标识符
loff_t i_size; // 文件大小,以 byte 为单位
struct timespec64 i_atime; // 最后访问时间
struct timespec64 i_mtime; // 最后修改时间
struct timespec64 i_ctime; // 创建时间
unsigned short i_bytes; // 已使用的字节数
const struct file_operations *i_fop; // 文件数据的函数操作,open、write、read 等
struct address_space i_data; // 设备的地址映射
...
};
struct inode_operations {
struct dentry * (*lookup) (struct inode *,struct dentry *, unsigned int);
const char * (*get_link) (struct dentry *, struct inode *, struct delayed_call *);
int (*permission) (struct mnt_idmap *, struct inode *, int);
struct posix_acl * (*get_inode_acl)(struct inode *, int, bool);
int (*readlink) (struct dentry *, char __user *,int);
int (*create) (struct mnt_idmap *, struct inode *,struct dentry *,
umode_t, bool);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*symlink) (struct mnt_idmap *, struct inode *,struct dentry *,
const char *);
int (*mkdir) (struct mnt_idmap *, struct inode *,struct dentry *,
umode_t);
int (*rmdir) (struct inode *,struct dentry *);
int (*mknod) (struct mnt_idmap *, struct inode *,struct dentry *,
umode_t,dev_t);
int (*rename) (struct mnt_idmap *, struct inode *, struct dentry *,
struct inode *, struct dentry *, unsigned int);
int (*setattr) (struct mnt_idmap *, struct dentry *, struct iattr *);
int (*getattr) (struct mnt_idmap *, const struct path *,
struct kstat *, u32, unsigned int);
...
} ____cacheline_aligned;
inode 结构体中的 i_op 和 i_fop 和前面的 super_block 结构体中的 s_op 类似,都定义了一系列的针对相应的文件系统对象的回调函数指针,用以操作该对象并隐藏底层的实现细节。
inode_operations 结构体定义了一组在 inode 上操作的回调函数: (简而言之,为打开文件的每个实例创建一个 struct 文件)
- 修改文件权限
- 创建文件
- 新建文件链接
- 新建目录
- 重命名文件
而 file_operations 则定义了一组针对 file 结构体的回调函数指针,关于这个结构体我们后面还会讨论。现在你只需要知道文件系统中每一个打开文件都必须创建一个相应的 file 结构体就行了。
关于 inode_operations 中每一个函数功能的详细介绍请参考官方文档9,文档里已经都有介绍了,这里便不再赘述。
目录项对象和目录项缓存 (DENTRY & DCACHE)
dentry 是 directory entry 的缩写,也就是目录项,它通过将 inode 索引节点编号与文件名关联,将 inode 和文件关联起来。inode 结构体作为文件系统中任何对象的代表,其内部虽然有一个字段作为该结构体的唯一 ID i_ino,但是这个字段是一个整型数,可读性较差,所以内核选择使用文件名(路径)作为用户层定位文件对象的标识。
正如前文所述,VFS 以路径名作为用户层的文件索引而实现了各式的 I/O 系统调用,比如常用的 open()、read()、write() 等系统调用,你可以发现都是基于文件路径进行操作的。还有一点,前面我们说过 inode 是唯一代表一个文件系统对象的存在,但其实文件对象也可能有不止一个唯一的标识,比如可以通过软链接和硬链接指向同一个文件对象,因此需要引入一个新概念 —— 文件(路径)名,用来将多个文件系统对象映射到同一个 inode,所以引入 dentry 从而把文件名和 inode 解绑也就变得顺理成章了。
VFS 把目录当做文件对待,所以在路径 /bin/vi 中,bin 和 vi 都属于文件 —— bin 是特殊的目录文件而 vi 是普通文件,路径中的每个组成部分都由一个 inode 表示,但似乎 VFS 经常需要执行目录相关的操作,比如路径名查找等。路径名查找需要解析路径中的每一个组成部分,不但要确保它有效,而且还需要再进一步寻找路径中的下一个部分。为了方便对文件路径进行查找操作,VFS 就引入了目录项的概念。每个 dentry 代表文件路径中的一个特定部分。对前面的那个例子来说,/、bin 和 vi 都是 dentry 对象。前两个是目录,最后一个是普通文件,也就是说在文件路径中,包括普通文件在内的每一个组成部分都是一个 dentry 对象。目录项也可包括挂载点。比如路径 /mnt/cdrom/foo 中,组成部分 /、mnt、cdrom 和 foo 都属于目录项对象。
dentry 结构定义在 <include/linux/dcache.h> 中:
struct dentry {
/* RCU lookup touched fields */
unsigned int d_flags; /* protected by d_lock */
seqcount_spinlock_t d_seq; /* per dentry seqlock */
struct hlist_bl_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */
/* Ref lookup also touches following */
struct lockref d_lockref; /* per-dentry lock and refcount */
const struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
unsigned long d_time; /* used by d_revalidate */
void *d_fsdata; /* fs-specific data */
union {
struct list_head d_lru; /* LRU list */
wait_queue_head_t *d_wait; /* in-lookup ones only */
};
struct hlist_node d_sib; /* child of parent list */
struct hlist_head d_children; /* our children */
/*
* d_alias and d_rcu can share memory
*/
union {
struct hlist_node d_alias; /* inode alias list */
struct hlist_bl_node d_in_lookup_hash; /* only for in-lookup ones */
struct rcu_head d_rcu;
} d_u;
};
struct dentry_operations {
int (*d_revalidate)(struct dentry *, unsigned int);
int (*d_weak_revalidate)(struct dentry *, unsigned int);
int (*d_hash)(const struct dentry *, struct qstr *);
int (*d_compare)(const struct dentry *,
unsigned int, const char *, const struct qstr *);
int (*d_delete)(const struct dentry *);
int (*d_init)(struct dentry *);
void (*d_release)(struct dentry *);
void (*d_prune)(struct dentry *);
void (*d_iput)(struct dentry *, struct inode *);
char *(*d_dname)(struct dentry *, char *, int);
struct vfsmount *(*d_automount)(struct path *);
int (*d_manage)(const struct path *, bool);
struct dentry *(*d_real)(struct dentry *, enum d_real_type type);
} ____cacheline_aligned;
其中,d_name 包含文件的名称,而 d_inode 指向其关联的 inode。
因为 dentry 不同于 super_block 和 inode,它在磁盘上没有对应的数据结构,所以使用文件路径名作为索引文件对象的时候,VFS 需要遍历整个文件路径中的所有部分并从块设备 (比如磁盘) 读取相关的数据实时解析成 dentry 对象,同时还要对路径中的每一部分进行验证和字符串比较。可想而知,这个过程是非常耗时和低效的,因此为了缓解这个过程的性能损耗,VFS 引入了目录项缓存,也就是 dcache。VFS 通过将文件路径中的每一个部分解析成的 dentry 对象缓存在内存中,下一次如果需要查找某一个路径,VFS 就会先到缓存中去找,如果命中了缓存则可以直接使用缓存,否则的话就必须要重新遍历路径并解析,再将解析完成的 dentry 对象放入 dcache 中,以便下次使用。
为了说明 dcache 的工作原理,我们先来介绍一下目录项对象由三种有效状态:正在使用、未被使用和负状态。
- "正在使用"的 dentry 对应一个有效的 inode (
d_inode是有效值) 而且 dentry 的引用计数为整数 (旧内核是d_count字段,新内核是d_lockref.count),表明该 dentry 存在至少一个使用者。这种 dentry 指向了 VFS 中的一个有效的数据,因此不能从 dcache 中清理掉。 - "未被使用"的 dentry 对应一个有效的 inode 但是 dentry 的引用计数为 0 ,表明该对象当前并没有任何使用者,这一类的 dentry 对象也会被保留在 dcache 中,虽然现在没有使用,但是未来可能会用到,但是如果因为内存紧张需要淘汰一些缓存的话会优先考虑清理掉这部分对象。
- 最后是"负状态"的 dentry,这一类的对象没有对应的 inode (
d_inode为 NULL),表明 inode 已经被删除了或者路径无效了,这一类的对象也会被暂时保留,因为某些操作可能需要确认某些路径是无效的,这时候缓存这一类的 dentry 就会很有价值。同样地,如果需要淘汰缓存的话这部分数据会被优先考虑清理掉。
dcache 主要由以下三个部分组成:
- "正在使用"的 dentry 链表。该链表通过 inode 中的
i_dentry字段把相关的 dentries 链接在一起,这是因为一个 inode 可能有多个指向它的链接 (比如有多个硬链接指向它) ,也就会对应多个 dentries,因此就用一个链表把这些对象串在一起。 - "最近被使用"的 双向链表。所有"未被使用"的和"负状态"的 dentries 都存放在这个链表中,该链表按照插入时间倒序排列,也就是说最新的数据总是从链表头部插入,所以越靠近链表尾部的对象越旧。当内核决定要回收内存的时候,会使用 LRU 算法优先对链表尾部进行清理,也就是最近最少使用的数据会被优先清理掉。
- Hash 表。通过 hash 函数可以快速地根据给定文件路径获取对应的 dentry 对象,如果不在缓存中则返回空值。
VFS 把所有的 dentry 对象都放在 dcache 最后的这个 hash 表中,底层是 dentry_hashtable 数组 + 双向链表,每一个数组中的元素都是一个指向具有相同键值的 dentry 链表的指针,数组的大小取决于系统中物理内存的大小,通过 LRU 算法来管理内存。
dcache 在一定程度上还实现了 inode 的高速缓存 (inode cache, icache)。因为在内核缓存中,那些"未被使用"的 dentries 对应的 inodes 也会被保存在缓存中,因为那些 dentries 还保留在 dcache 中,所以那些 inode 的引用计数就会变成正数,也就会一起留在缓存中。未来如果 VFS 需要查找那些 inodes 的时候,就能借助 dcache 快速找到它们。
关于 dentry_operations 中每一个函数功能的详细介绍请参考官方文档10,文档里已经都有介绍了,这里便不再赘述。
文件对象 (FILE)
VFS 的最后一个重要对象是 file 文件对象,它表示由用户空间进程打开的文件。这个对象将用户空间的文件和内核空间的 inode 对象关联起来,如果我们从用户空间的视角去看待 VFS,file 就是 VFS 提供的沟通用户空间和具体文件系统的标准接口,因为用户程序直接处理的就是文件而非超级块、索引节点和目录项。内核通常是通过分发一个文件描述符 (file descriptor) 给用户空间进程,用以对文件对象进行各种操作 (这是出于隔离性的考虑,内核不会把 file 的地址直接返回到用户空间,而是返回一个整型的 fd,这样更加安全,可以回到本文前面的"用户态与内核态"章节复习一遍) ,当执行文件系统调用时,内核将该描述符映射到实际的文件结构。
文件对象是已打开的文件在内存中的表示。该内存对象通常由 open() 系统调用创建,由 close() 系统调用销毁,所有这些与文件对象相关的系统调用实际上都是文件操作函数表中定义的方法。从用户进程的视角看文件对象代表一个已打开的文件,但实际上从内核视角看,file 对象其实是指向了 dentry 对象,当然,实际上 dentry 对象又指向 inode,这才是真正的尽头,但是前面我们已经讲解过,因为很多原因需要用路径名和 dentry 来表示一个文件,所以从逻辑层面上讲 dentry 对象才真正表示一个已打开的文件
file 对象的定义在 <include/linux/fs.h> 中可以找到:
struct file {
struct path f_path; // a dentry and a mount point which locate this file
struct inode *f_inode; // the inode underlying this file
const struct file_operations *f_op; // callbacks to function which can operate on this file
spinlock_t f_lock;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
struct mutex f_pos_lock;
loff_t f_pos // offset in the file from which the next read or write shall commence
struct fown_struct f_owner;
void *private_data
struct address_space *f_mapping; // callbacks for memory mapping operations
...
};
struct file_operations {
struct module *owner;
fop_flags_t fop_flags;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
ssize_t (*write_iter) (struct kiocb *, struct iov_iter *);
int (*iopoll)(struct kiocb *kiocb, struct io_comp_batch *,
unsigned int flags);
int (*iterate_shared) (struct file *, struct dir_context *);
__poll_t (*poll) (struct file *, struct poll_table_struct *);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, loff_t, loff_t, int datasync);
int (*fasync) (int, struct file *, int);
...
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
...
ssize_t (*copy_file_range)(struct file *, loff_t, struct file *,
loff_t, size_t, unsigned int);
loff_t (*remap_file_range)(struct file *file_in, loff_t pos_in,
struct file *file_out, loff_t pos_out,
loff_t len, unsigned int remap_flags);
...
} __randomize_layout;
这里要强调的是,file 对象表示一个打开的文件,并且包含了诸如打开文件时使用的标志和进程可从其中读取或写入的偏移量等数据。当文件关闭时,这个数据结构将从内存中删除,诸如写数据之类的操作将被委托给相应的 inode。file 对象是由内核直接管理的。每个进程都有当前打开的文件列表,放在 files 结构体中。
所有打开的 file 对象都存储在内核中的 fd_array 数组,用户空间持有的文件描述符 fd 本质上是这个数组的索引,fd 传递回内核进行相关的文件操作时,内核就是通过它从 fd_array 数组中取出真正的 file 对象进行相应的操作。
关于 file_operations 中每一个函数功能的详细介绍请参考官方文档11,文档里已经都有介绍了,这里便不再赘述。
页高速缓存 (Page Cache)
页高速缓存 (page cache) 是 Linux 内核实现的磁盘缓存机制。主要作用是减少对磁盘的访问。具体实现是通过把磁盘中的数据缓存到物理内存中,把对磁盘的访问改成对内存的访问。通常,缓存的数据源我们称之为后备存储,比如 Page Cache 的后备存储大多数时候是磁盘。之所以在大多数现代操作系统上都需要这个机制是基于以下两个因素:
- 从本文的"计算机存储设备"那一个章节可以知道,不同层级的存储介质的访问速度往往也相差了好几个数量级,比如内存和磁盘,是 ns 和 ms 的差距,因此引入内存 cache 对于磁盘 I/O 的性能来说会带来数量级的提升,如果使用 CPU 的 L1 和 L2 的高速缓存则会更快。
- 从概率上来讲,数据一旦被访问,就很可能在短期内需要再次访问,也就是热点数据。这种在短时间内多次访问同一片数据的原理被称作时间局部原理 (Temporal Locality)。这个原理描述了一种现象:如果数据在第一次被访问的时候就缓存起来,那么这个缓存就很可能会在极短的时间内被再次命中。由于内存访问要比磁盘访问快得多,同时又有 temporal locality 存在,所以内存缓存能给磁盘 I/O 带来质的飞跃。
学习本章之前最好要提前了解一下虚拟内存的原理,本文已经在"计算机存储设备"那一章简单地介绍过相关的知识,读者们如果仔细阅读过那一章,那理论上阅读这一章就不会遇到什么难以理解的地方,但是建议后面可以进一步地阅读《虚拟内存精粹》,加深这方面知识的理解。
页与复合页 (Page & Folio)
虽然计算机的最小可寻址单位通常是字 (word) 甚至可以字节,但是内核把物理页作为其内存管理的基本单位,MMU 也以页为单位对内存进行处理,因此从虚拟内存的角度来看,页 (page) 就是最小的操作单位。页的大小通常是 4KB 或者 8KB,也就是说 1 GB 的物理内存对应着 262144 个 4KB 的页。
内核使用 struct page 结构体来定义物理页,代码位于 <include/linux/mm_types.h> 中,当前内核 (v6.10) 中这个结构体中的字段数已经非常膨胀了,因此内核为了降低这个结构体的存储成本,将该结构体中的很多字段都用 C 语言的 Union 包起来来优化内存对齐,节省存储空间,由于其复杂性过于膨胀,不便于初学者入门学习,因此我这里用老版本的内核代码来展示:
struct page {
unsigned long flags;
atmoic_t _count;
atmoic_t _mapcount;
unsigned long private;
struct address_space *mapping;
pgoff_t index;
struct list_head lru;
void *virtual;
}
虽然上面是旧内核的代码,但是几个核心的字段都还在:
flags表示本页的状态,比如是否是脏页 ——PG_ditry,所有的标志定义在 <include/linux/page-flags.h>。_count代表本页的引用计数 (现在重命名为_refcount),其值减少为 -1 的时候就说明内核已经没有在使用该内存页了,可以回收。_mapcount表示当前有多少个页表 (page table) 映射到本页,每个用户进程都拥有自己的进程地址空间和页表,因此这个字段就代表当前有多少个进程映射到该页。-1 表示没有进程映射本页,0 表示只有父进程映射了本页,>0 则表示除了父进程还有其他用户进程也映射了本页。mapping指向其关联的 address_space 对象 (这个对象在后面会讲解),当该页被存入 page cache 的时候就会给mapping赋值。index:跟上面的mapping有关的字段。该字段是一个多用途的字段,用途不同的时候有不同的含义:当被用作文件内存页映射时,它代表本页在磁盘文件中以页大小为单位的偏移量,也就是在文件中的位置;当被用作匿名页映射时,它代表该匿名页在对应的用户进程的虚拟内存的 VMA (Virtual Memory Area,虚拟内存区) 中的地址偏移。lru:代表本页的 LRU 双向链表节点,内核会根据本页的状态将这个节点链接到内核中具有不同的用途的 LRU 链表中,以便内核后续通过 LRU (最近最少使用) 算法来管理这些内存页。
Linux 内核在 5.16 版本12 中对其内存管理系统进行了一次巨大的重构,引入了 folio —— 复合页的概念,folio 本质上就是一组 pages,之所以需要 folio 是因为随着计算机硬件的飞速发展,计算机处理数据的速度也越来越快,有很多压测数据都表明当内核使用更大的数据块的时候其 I/O 性能会更高,内核中有很多需要操作比 page 更大的数据块的场景,比如 HugeTLB Pages,TLB 我在前面的虚拟内存那一章节里简略介绍过了,想了解更多细节请阅读我的另一篇文章《虚拟内存精粹》。在 folio 之前,内核是通过将扩展 page 结构体来构造和管理比 page 更大的数据块,这就表示 page 结构体能表示单页、多页甚至是大页,导致了 struct page 的语义愈加模糊与混乱,最后积重难返,所以团队后来决定进行一次大的重构,引入 folio,将 struct page 返璞归真,删繁就简,去除了之前的那些扩展,回归单一的语义 —— 代表单个内存页,然后将 page 内嵌到 folio 结构体中,以 folio 表示一个复合页 (folio 也可以表示一个单页)。
目前内核中很多在 page cache 的方面的代码都已经使用 folio 替换了 page,而且这也是一个趋势,相信未来会在某一个内核新版本中完成全部的替换。虽然现在内核主要使用 folio 来操作 page cache,但是内核在代码层面上对 folio 做了很好的封装,在宏观层面完全可以将 folio 映射到 page,内心有一个 folio 概念即可,对于我们这些学习内核相关知识的人来说还是比较友好的,所以我们在本文后面分析内核的时候,还是尽量使用 page 这个词汇,保持兼容性。
Page cache 基本结构
在 Linux 还不支持虚拟内存技术之前,还没有页的概念,因此 Buffer Cache 是基于操作系统读写磁盘的最小单位 —— 块 (block) 来进行的,所有的磁盘块操作都是通过 Buffer Cache 来加速,Linux 引入虚拟内存的机制来管理内存后,页成为虚拟内存管理的最小单位,因此也引入了 Page Cache 来缓存 Linux 文件内容,主要用来作为文件系统上的文件数据的缓存,提升读写性能,常见的是针对文件的 read()/write() 操作,另外也包括了通过 mmap() 映射之后的块设备,也就是说,事实上 Page Cache 负责了大部分的块设备文件的缓存工作。而 Buffer Cache 用来在系统对块设备进行读写的时候,对块进行数据缓存的系统来使用,实际上负责所有对磁盘的 I/O 访问:
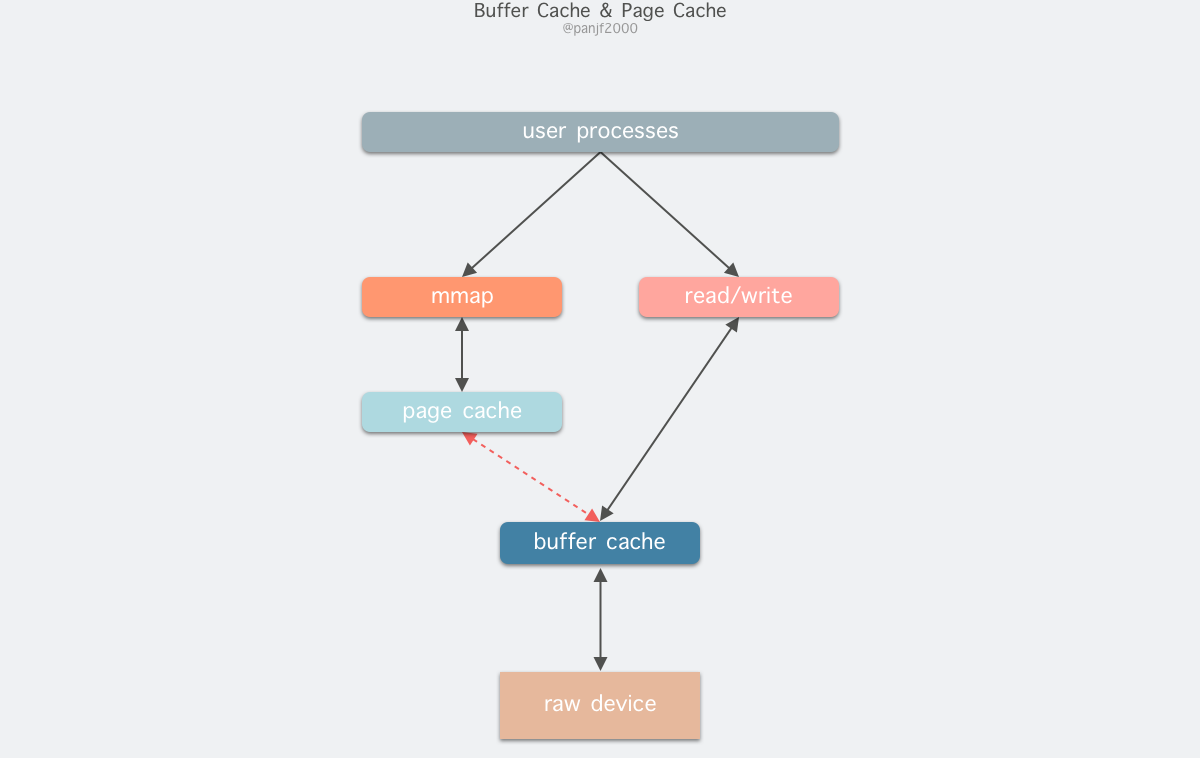
因为 Buffer Cache 是对粒度更细的设备块的缓存,而 Page Cache 是基于虚拟内存的页单元缓存,因此还是会基于 Buffer Cache,也就是说如果是缓存文件内容数据就会在内存里缓存两份相同的数据,这就会导致同一份文件保存了两份,冗余且低效。另外一个问题是,调用 write 后,有效数据是在 Buffer Cache 中,而非 Page Cache 中。这就导致 mmap 访问的文件数据可能存在不一致问题。为了规避这个问题,所有基于磁盘文件系统的 write,都需要调用 update_vm_cache() 函数,该操作会把调用 write 之后的 Buffer Cache 更新到 Page Cache 去。由于有这些设计上的弊端,因此在 Linux 2.4 版本之后,kernel 就将两者进行了统一,Buffer Cache 不再以独立的形式存在,而是以融合的方式存在于 Page Cache 中:
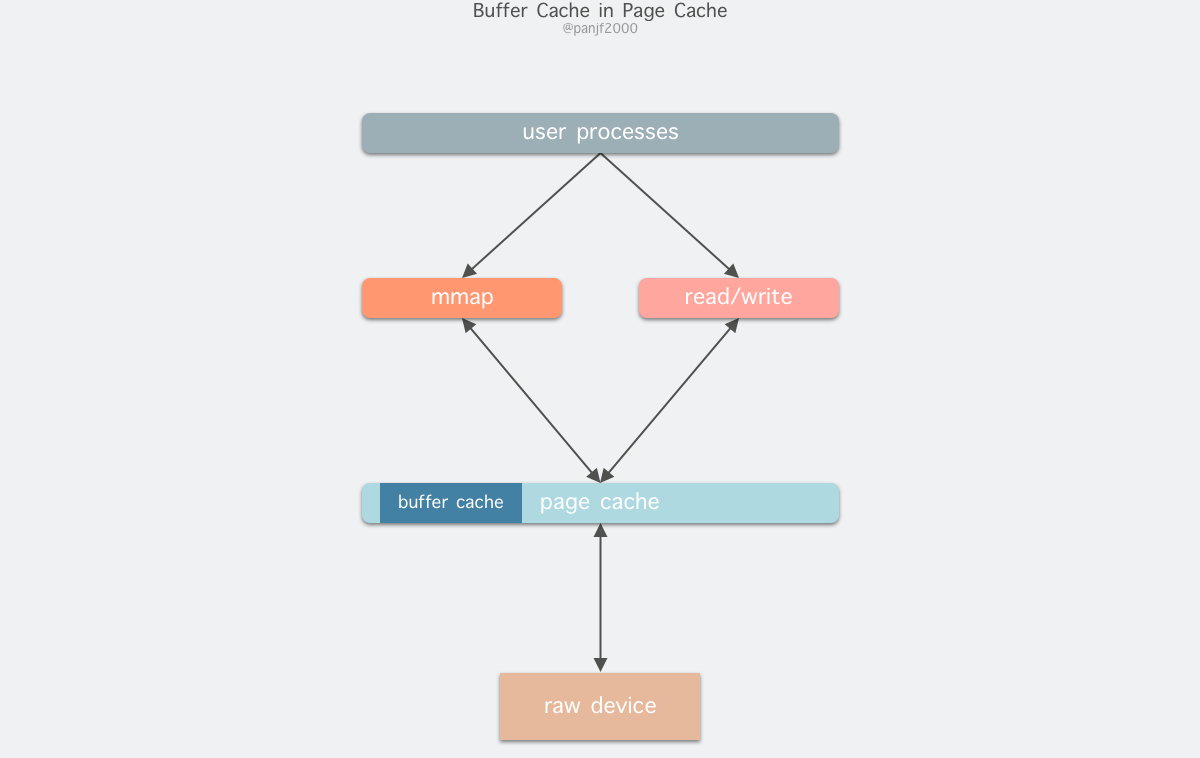
融合之后就可以统一操作 Page Cache 和 Buffer Cache:处理文件 I/O 缓存交给 Page Cache,而当底层 RAW device 刷新数据时以 Buffer Cache 的块单位来实际处理。
写缓存
Page Cache 中通常有三种写策略:
No Write,也就是不缓存。当内核对 Page Cache 中的某一个数据块进行写操作的时候,直接越过缓存落到磁盘,同时把这一块缓存释放掉使其失效,后续请求读取这部分数据的时候,直接从磁盘读,然后再放入缓存。这种策略很少用,虽然实现简单,但是效率低下,因为磁盘 I/O 的频次比较多。Write Through,也就是写穿缓存。内核的写操作对 Page Cache 进行更新之后,立刻穿透缓存将更新的数据落到磁盘。这种策略也被称为同步写策略,因为数据是同步更新到磁盘中,这种策略能很好地保持缓存一致性 —— 实时保持缓存和后备存储的同步。这种策略实现较为简单,但是性能较低,因为每个内存上的写操作都需要实时更新磁盘,而磁盘的速度比起内存要低了几个数量级,导致操作成本骤升。Write Back,也就是写回缓存。内核更新完 Page Cache 之后就直接返回,不会同步更新磁盘,而是把那些被更新的内存页标记成 dirty pages,也就是脏页,并且将其加入到脏页链表中,等待一个或多个专门的内核线程周期性地把脏页链表中的内存页取出并写回到磁盘,从而使得内存和磁盘中的数据能够达到最终一致,最后清理掉脏页的PG_dirty标识。这种策略又被称为异步写策略,其性能最高,因为同步操作仅限于内存,写磁盘的耗时操作被异步化了,同时还能进行批量写的优化,代价是代码实现的复杂度高了很多。Linux 默认采取的是 Write Back 策略。
脏页落盘
从上面的写策略的介绍中我们可以得知,VFS 中的写操作实际上是异步的,也就是说写操作会被延迟执行。当 Page Cache 中的某些缓存页被更新之后,这些内存页会被标记为 PG_dirty,也就是"脏"数据。内核需要某种机制来确保内存中的 dirty pages 能被写回到磁盘,否则的话如果发生宕机事件,Page Cache 中那些已更新的"脏"数据就会永久性丢失,这个过程称为回写 writeback。通常有两种途径可以将脏页写入磁盘:
- 用户进程手动调用
sync()/fsync()/fdatasync()等系统调用同步地将当前的脏页写入磁盘。 - 内核通过 flusher 线程定期自动将脏页写回到磁盘。
- 当 Page Cache 中的 dirty pages 比例超过一个特定的阀值时,会挤占其他用户进程的可用内存,这时就需要让 Page Cache 释放掉一部分内存来救急,但是脏页所占的内存是不能直接就回收的,否则会造成缓存和磁盘的数据不一致,这时内核就会将当前的脏页写回磁盘,然后清理掉这些内存页的
PG_dirty标志,使其变成"干净的"内存页,此时 Page Cache 就可以按照特定的策略 (比如 LRU 算法) 选出一部分页面来释放掉,收缩自身占用的内存。 - 当脏页在内存中的驻留时间超过一个特定的阀值时,内核会将这些"超时的"脏页写回磁盘,以确保这些脏页不会因为停留在内存中太久而发生某种意外丢失。
- 当 Page Cache 中的 dirty pages 比例超过一个特定的阀值时,会挤占其他用户进程的可用内存,这时就需要让 Page Cache 释放掉一部分内存来救急,但是脏页所占的内存是不能直接就回收的,否则会造成缓存和磁盘的数据不一致,这时内核就会将当前的脏页写回磁盘,然后清理掉这些内存页的
我们先来讲解一下内核中专门负责脏页落盘的 flusher 线程,sync()/fsync()/fdatasync() 等系统调用放到后面讲,因为这些系统调用本质上也是唤醒 flusher 线程去工作。
让我们先来了解几个关于这部分须知的内核参数13:
/proc/sys/vm/dirty_background_ratio,代表 Page Cache 中脏页占全部可用内存的百分比阀值。当内存中的脏页比例超过这个阀值,后台内核 flusher 线程就会启动开始将脏页写回磁盘。默认值是 10%/proc/sys/vm/dirty_background_bytes,代表 Page Cache 中脏页所占内存字节数的绝对值。当内存中的脏页字节数超过这个阀值,后台内核 flusher 线程就会启动开始将脏页写回磁盘。这个参数和dirty_background_ratio两者之间通常只需要设置一个即可,另一个就会被重置为 0。/proc/sys/vm/dirty_ratio,和/proc/sys/vm/dirty_background_ratio一样代表脏页比例的阀值。当超过这个阀值,当前所有正在对 Page Cache 进行写操作的用户进程将会被阻塞,直到 flusher 线程把 Page Cache 中的脏页比例给降到一定的水平。默认值是 20%/proc/sys/vm/dirty_bytes,代表 Page Cache 中脏页所占内存字节数的绝对值。当内存中的脏页字节数超过这个阀值,当前所有正在对 Page Cache 进行写操作的用户进程将会被阻塞,直到 flusher 线程把 Page Cache 中的脏页比例给降到一定的水平。这个参数和dirty_ratio两者之间通常只需要设置一个即可,另一个就会被重置为 0。/proc/sys/vm/dirty_expire_centisecs,定义了脏页在内存中驻留的超时时间。flusher 线程是周期性被唤醒的,每一次被唤醒之后会检查所有脏页从产生到现在的时长,在内存中停留超过这个时间的所有脏页将会 flusher 写回到磁盘。这个参数的单位是 1/100 秒也就是厘秒,或者说是 10 毫秒。默认值是 30 秒。/proc/sys/vm/dirty_writeback_centisecs,定义了 flusher 线程的唤醒周期,也就是每隔多长时间会被唤醒一次。这个参数的单位也是厘秒。默认值是 5 秒。
关于 Linux 的 Page Cache 的 writeback 机制,这里还有两个点需要再稍微深入讲解一下。
首先是 flusher 线程,它是在内核 v2.6.32 版本14中引入的,熟悉内核的读者应该知道内核 v2.6 以前的 writeback 机制是通过另外两个线程 bdflush 和 kupdated 实现的。bdflush 的工作原理和现在的 flusher 类似,都是基于某些阀值工作的,阀值被触发之后内核就会调用 wakeup_bdflush() 唤醒 bdflush 线程开始工作。以前的 bdflush 线程和现在的 flusher 线程主要有两个区别:第一,bdflush 是单线程而 flusher 是多线程 (基于磁盘数量) ;第二,bdflush 线程是基于 buffer cache 工作的,也就是它其实是把 dirty buffer 而非 dirty page 写回磁盘 (关于 buffer cache 和 page cache 的详细内容前文已经叙述过,不记得的话请返回再阅读一遍) ,而 flusher 则是基于 page cache 工作的,它是将整个脏页刷盘的,实际上 page 中可能包含 buffer,但是 flusher 的实际操作对象是 page 而不是 buffer 代表的 block,page 是内存的标准单位,block 则是磁盘的标准单位,虽然两者的 size 可能是一样的,但是本质上是两种东西。因为 writeback 管理的是内存数据,因此以 page 为单位来操作显然比 buffer 要更加简单。
bdflush 线程只有在 buffer cache 比例过高或者可用内存过低的条件下才会被触发,为了还能够周期性地将 cache 落盘,后来又引入了 kupdated 线程,它负责周期性将缓存写回磁盘的任务。后来内核 v2.6 发布,bdflush 和 kupdated 线程被 pdflush (page dirty flush) 线程取代,pdflush 线程的原理和现在的 flusher 非常相似,二者的主要区别是:pdflush 是基于系统 I/O 负载的多线程,每个线程都是全局线程,也就是说这些线程是面向系统中的所有磁盘工作的,任何线程可能在任意时刻在往任意磁盘回写缓存。这种方案的优势是实现起来简单,劣势是多个线程容易在某一个磁盘上拥塞导致其他磁盘的 writeback 饥饿,所以需要再引入多线程拥塞控制机制来缓解这种情况。后来的 flusher 线程则采用本地线程,也就是每一个磁盘独占一个线程,互不干扰,这样就避免了多线程拥塞的情况,确保了不会出现多数磁盘的 writeback 饿死的情况。
WriteBack 多线程拥塞控制
Linux 最初的 bdflush 是单线程架构,可想而知这种设计会很容易使得线程在处理某一个磁盘的时候过于繁忙而导致其他磁盘上的 writeback 没有机会执行,也就是处于饥饿状态。在机械硬盘 HDD 占主流的时代,磁盘 I/O 的性能瓶颈主要在磁盘寻址操作上,因此内核在块设备之上设计了一个 I/O 调度层 (这部分会在后面的章节详细介绍) ,所有的 I/O 请求都会先放到一个单一的请求队列中,然后由调度程序统一对这些 I/O 请求进行合并与排序,将访问相邻磁盘扇区的多个请求合并成一个,同时将所有请求按照扇区地址顺序排列,这样就可以减少磁盘寻址操作,同时能让磁盘的磁头可以在金属盘片上连续地读写数据而不需要让机械臂来回转动进行随机读写,这种机制能极大地提升磁盘 I/O 性能。而单线程的 bdflush 很容易会阻塞在某个磁盘的 I/O 队列上,导致没有时间去其他磁盘执行 writeback。
2.6 内核引入了 pdflush 线程,通过多线程来解决这个问题,每个线程会尽量到每一块磁盘上去执行 writeback,这种设计在正常情况下可以运行得很好,但是因为这些线程是全局线程,所以极端情况下会出现多个线程阻塞在一个磁盘的 I/O 队列上,导致其他磁盘被饿死,这种情况就相当于又退化成单线程架构了,甚至还不如单线程模式,因为多线程还更占用系统资源。后来为了缓解这种极端场景,pdflush 现成设计了一种拥塞回避策略:每个线程需要主动识别出那些当前不拥塞的磁盘 I/O 队列,然后尽量往这些磁盘上去执行 writeback,这样就能让 pdflush 线程将其工作负载平摊开来,避免负载过于集中而导致饥饿问题。
pdflush 线程的拥塞控制策略从设计上是比较优秀的,但是有两个问题:
- 实现上过于复杂,从前文的描述可知,每个线程都要主动检测 I/O 队列的繁忙情况,这又增加了内核与 I/O 系统通信成本,而且还需要平衡好每个磁盘的线程分布,不能过于集中也不能过于稀疏,算法复杂度较高。
- I/O 总线技术和计算机其他部分的发展是不同步,通常前者的进步要缓慢很多,这就导致了计算机内各个部件之间的速度一直存在着代差,比如 CPU 因为摩尔定律的存在所以其处理速度进步很快,而磁盘的速度则一直都很缓慢,而且除了 pdflush 以外,I/O 系统中很少有其他组件应用了类似的拥塞控制策略,所以 pdflush 线程的拥塞控制就像是孤军奋战,虽然已经尽力在避免拥塞了,但是 I/O 栈中的拥塞还是时有发生,导致精心设计的拥塞控制算法性价比一直不高。
2.6.32 内核引入了新的方案:flusher 线程,并一直沿用至今。这个新方案使用了更简单的实现:将全局线程改为本地线程,每一块磁盘独占一个 flusher 线程,每个线程就只负责它所在的那块磁盘的 writeback 工作,也就是只从自己负责的那块磁盘上的脏页链表收集数据并回写到磁盘;这样也就不需要实现很复杂的拥塞控制算法了,通过这种相对简单的架构,实现了 I/O 请求的负载均衡,降低了饥饿风险,同时又能维持一个较高的 I/O 吞吐。这就是 HDD 磁盘的单一 I/O 队列下的 writeback 机制,至于 SSD 磁盘的多 I/O 队列下的 writeback 机制我们会在后面介绍。
第二个关于 writeback 机制的注意点是 dirty_background_ratio 和 dirty_ratio 这两个内核参数的区分:前者是控制 flusher 线程开始执行 writeback 的时机,后者是阻挡新的写操作的时机。这两个值常常会被混淆使用,所以需要在这里讲解一下。首先是 dirty_background_ratio,这个相对简单,就是一个脏页占所有内存的比例阀值,当系统中的脏页比例超过这个阀值,内核就会调用 wakeup_flusher_threads() 函数开始 writeback。然而,就算 flusher 线程开始清理脏页了,系统中的用户进程还是可以继续执行各种对磁盘的写操作,如果用户进程的写操作速度快于 flusher 线程的清理速度,那么脏页比例还是持续上升,那么 Page Cache 中的脏页比例就永远无法降下来了,所以就需要另一个内核参数来限制脏页比例的持续上升,也就是 dirty_ratio。
当脏页比例越过了 dirty_background_ratio 而且继续上升,最后达到了 dirty_ratio 这个阀值,在比较老的内核中就会拦截新的写操作并阻塞所有用户进程,好让 flusher 能先把已有的脏页处理完,把脏页比例尽快降到 dirty_background_ratio 以下。在相对较新的内核中则是会采取一种渐进式的方案:在脏页比例超过 dirty_background_ratio 而且往 dirty_ratio 靠近的过程中,内核会渐渐对写操作进行限流,刚开始的力度会比较小,越往后力度越大,直到触及 dirty_ratio 时就会把闸门完全关闭,此时所有写操作都会被阻塞,从官方文档来看,内核除了会阻塞正在执行写操作的用户进程同时还可能会利用这些进程的 CPU 时间片让它们自己把脏页写回磁盘。这个过程有点像 Java 和 Go 的垃圾回收中的 write barrier 写屏障和 STW,事实上内核的这个机制也常常是导致系统长时间 I/O 暂停的元凶,所以 dirty_background_ratio 和 dirty_ratio 这两个内核参数调优过程中要非常谨慎,特别是后者,如果设置得太小就容易引起整个系统的 I/O 长时间暂停。按照SUSE 团队的建议,dirty_background_ratio 的值最好设置成 dirty_ratio 1/4 到 1/2 之间。如果你把这两个参数的值设置成相同的值,那么内核也会自动做 dirty_background_ratio = dirty_ratio/2 的转换。这个规则也适用于 dirty_background_bytes 和 dirty_bytes15。
手动 writeback
前文提到过,为了防止机器宕机导致 page cache 中的数据更新丢失,Linux 实现了 writeback 机制,保证了系统的可靠性。除了内核的自动 writeback 机制,用户进程也能通过系统调用来手动将脏页刷盘。为什么已经有了自动机制,还要提供手动的方式让用户进程去操作呢?因为自动的机制虽然方便,但是内核为了尽量减少对磁盘的写操作,其默认的刷盘策略通常不会太激进,也就是会平衡可靠性和成本,虽然我们可以通过修改内核参数来实现更激进的 writeback 策略,但是有时候用户程序希望数据能马上刷盘,那么最快的方式当然还是让用户进程自己手动写磁盘。因此,Linux 提供了以下几个系统调用:
sync & syncfs
#include<unistd.h>
void sync(void);
int syncfs(int fd);
进行全局 writeback,将系统中的所有脏页都回写到磁盘。按照 POSIX 标准16,sync() 的语义是较为宽松的,该标准只要求这个系统调用通知内核开始脏页刷盘之后就可以返回了,至于内核什么时候开始、什么时候完成,POSIX 对此没有要求。Linux 早期确实按照这个标准去实现的,用户进程调用该系统调用之后内核仅仅是唤醒 flusher 线程去工作就返回了,但是后来 Linux 加强了 sync() 的语义17:系统调用阻塞直到存储设备向内核确认数据已经写入。从源码看,用户进程调用 sync(),内核会通过 wakeup_flusher_threads() 唤醒所有 flusher 线程并行进行 writeback,并且同步所有 inode 到磁盘,之后同步所有的块设备,而且等待所有工作完成后才返回。
syncfs() 的实现和 sync() 一样,但是它只针对给定文件所在的那一个文件系统进行同步 (而不是所有文件系统)。这个系统调用不属于 POSIX 标准,是 Linux 特有的。
fsync & fdatasync
#include<unistd.h>
int fsync(int fd);
int fdatasync(int fd);
Linux 上的 fsync() 从一开始就严格按照 POSIX 标准的语义实现18,也就是该系统调用必须等到内核真正把脏页写入磁盘之后才能返回。fsync() 不仅会将文件数据刷盘,而且还会把文件的元信息 metadata (inode) 也刷盘,这就表示一次 fsync() 调用会触发两次写操作。另外,fsync() 不保证文件所在目录的 dentry 也会一起同步到磁盘,因此通常还要针对目录的 fd 再调用一次。
fdatasync() 是为了解决上面提到的 fsync() 两次写操作的问题而引入的,它通常只会同步写文件数据到磁盘而异步写文件元数据,除非 metadata 的更新会影响到后续的文件数据读取,比如像是文件的大小 st_size,如果这个数据不更新到磁盘,其他用户进程读取文件的时候就可能造成数据错乱,所以如果这个元数据有更新,那么 fdatasync() 也会将其一起刷盘;而像 st_atime (文件最后访问时间) 和 st_mtime (文件最后修改时间) 这样并不会影响后续的文件读取的 metadata,fdatasync() 就不会同步写到磁盘,节省 I/O 开销。
这两个系统调用都是 POSIX 标准。需要注意的是,这两个系统调用的真实行为取决于具体的文件系统的实现,因为它们是通过 VFS 的 file_operations.fsync 函数指针实现的,所以在不同的文件系统中这两个系统调用的行为有可能不一致,比如有些文件系统会把 fsync() 实现成和 fdatasync() 一样,只同步文件数据而不同步元信息,在内核 2.2 以及之前的版本也是如此,甚至在一些更老的内核版本和文件系统中,文件系统不知道怎么进行脏页刷盘19。
sync_file_range
#define _GNU_SOURCE /* See feature_test_macros(7) */
#define _FILE_OFFSET_BITS 64
#include <fcntl.h>
int sync_file_range(int fd, off_t offset, off_t nbytes, unsigned int flags);
sync() 的粒度是整个系统,syncfs() 的粒度是一个文件系统,fsync()/fdatasync() 的粒度是一个文件。对于 I/O 密集型的应用 (比如数据库) 来说,经常需要对大文件做多次小更新,而且需要频繁地刷盘而不想这里成为性能瓶颈,即便是用 fdatasync(),这个场景的 I/O 开销也非常大;而如果等所有更新完成之后再在一次性调用 fsync()/fdatasync() 的话会因为脏页数量过大而执行得特别慢。这时候就需要 sync_file_range() 出马了,这个系统调用在内核 2.6.1720 引入,其核心的卖点就是细粒度刷盘+异步化,首先是细粒度,sync_file_range() 支持指定文件范围而不是整个文件去刷盘,其次是它可以异步操作,也就是不用阻塞等待它返回。
这个系统调用使用起来比较复杂,而且按照内核官方的文档,它使用起来有一定的风险,所以最好不要在编写跨平台可移植的程序时使用它21,因为它完全不会同步文件的 metadata,所以只能依靠自动 writeback 机制去同步这些 metadata,因此如果发生宕机或重启,sync_file_range() 不保证那些调用过它同步数据的文件能恢复,因为磁盘上的文件元信息很可能是不全的,所以这个系统调用的不适合那些需要强持久化保证的数据库,比如 mysql,而只适合那些对持久化要求不高的数据库,比如 redis。总而言之,这个系统调用的适用范围比较窄,使用起来也比较复杂,而且风险较高,需要谨慎使用。这里就不过多介绍了,有兴趣的读者可以直接参考官方文档,另外我推荐一篇写得很好的关于 sync_file_range() 的文章,那里面除了介绍该系统调用的用法以外,还比较深度地剖析了它的工作原理,值得一读。
注意,这个系统调用不是 POSIX 标准,是 Linux 特有的。
O_SYNC & O_DSYNC & O_RSYNC
上面的那几个系统调用都是在需要的时候才对一个文件调用的,优点是比较灵活,只在有需求的时候才手动把脏页刷到磁盘,缺点是在一些场景中比较繁琐,比如某一个文件的所有写操作都需要马上刷回磁盘,那么每次写操作之后还得再调一个系统调用,不仅麻烦而且损耗性能。这个时候就可以通过 open() 系统调用打开文件的时候指定 O_SYNC、 O_DSYNC 和 O_RSYNC 标志22,也可以通过 fcntl() 对已有的文件设置这两个标志。这三个文件标志是 POSIX 标准23。
对一个文件指定这三个标志会开启同步 I/O (Synchronized I/O)24:
O_SYNC:每次读文件写操作都会阻塞直到数据被写入磁盘,相当于每次写操作之后都调用fsync()。O_DSYNC:和O_SYNC一样,但是只会把文件数据写入磁盘,只有在某些特定的文件元信息会影响后续的读写操作的时候才会将其一起写入磁盘,相当于fdatasync()。O_RSYNC:只影响读操作,需要和O_SYNC或O_DSYNC一起用。当设置了这个标志之后,调用read()的时候就会阻塞直到文件中的所有最近更新的数据都被写回磁盘之后才返回,也就是确保读操作取回的数据永远是最新的。实际上 Linux 并没有严格按照 POSIX 标准实现这个标志,而是在内核中简单地定义O_RSYNC为O_SYNC。
读缓存
Page Cache 本质上是内存中的物理页面组成的,其内容对应磁盘上的物理块 (Block)。Page Cache 的大小是动态调整的 —— 内存富余的时候会申请更多的内存以扩充自己,内存紧张的时候会释放自己占用的内存以缓解系统压力。当用户进程发起一个 read() 系统调用的时候,内核会先检查用户请求的数据是否已经在 Page Cache 中,如果是的话,则直接从缓存中读取出来返回给用户进程,这个过程被称之为缓存命中 —— cache hit;反过来如果数据不在缓存中,那么内核将不得不调度 I/O 操作从磁盘读取数据,然后把这些数据存入 Page Cache 以供下次使用,这个过程被称之为缓存未命中 —— cache miss。这里需要注意的是,内核并不一定会将整个磁盘文件都缓存起来,通常只会缓存其中的几个(内存)页,如果是很小的文件,则整个被缓存的概率会大一点。
预读策略
Page Cache 的缓存策略本质是基于计算机系统中数据访问的时间局部性 (Temporal Locality):对同一内存位置的相邻的访问之间存在时间上的紧凑性,说人话就是说如果某个内存页在某一个时刻被访问,那么这个内存页在短时间内很可能会被再次访问。而 Page Cache 的预读策略本质则是基于计算机系统中数据访问的空间局部性 (Spatial Locality):时间上相邻的内存访问之间存在空间上的紧凑性,说人话就是如果一个特定的内存页在某个特定的时刻被访问,那么这个内存页相邻的其他内存页在短时间内很可能也会被访问。Temporal Locality 实际上是 Spatial Locality 的一个特例。从前文所述中我们可以得知,I/O 栈里写操作是异步的,写完 Page Cache 就可以直接返回了;但是读操作却是同步的,如果 Page Cache 没有命中,则需要从磁盘读取,性能较差。因为处理磁盘文件的时候大多数时候都是顺序访问的,又根据 Spatial Locality 原理,访问了 [A, B] 地址范围内的数据之后很可能会继续访问 [B+1, B+N] 地址范围的数据,因此 Page Cache 就可以执行预读策略,在读取了当前内存页之后再异步地加载这一页后面内存页到 Page Cache,等到用户程序请求访问后面的内存页的时候,数据已经在 Page Cache 里了,可以直接返回给用户进程,大幅减少了磁盘 IO 的次数,避免阻塞 read() 等系统调用,延迟可以大大降低。内核中将这种预读机制称为 readahead。
以下是内核中的 VFS 读取文件的底层函数25,可以看到内核会应用 readahead 预读机制加载磁盘数据到 Page Cache,如果请求读取的 Page 不在 Cache 中,那就需要同步地从磁盘加载上来,但是后续的相邻 Pages 就可以异步地加载,以便能尽快先把用户进程请求的数据返回到用户空间。在我们介绍完了 Linux I/O 栈的所有分层之后,进行整个 I/O 执行栈的具体分析的时候还会讲解这个函数,所以这里对这个函数有一个印象就行。
/**
* filemap_read - Read data from the page cache.
* @iocb: The iocb to read.
* @iter: Destination for the data.
* @already_read: Number of bytes already read by the caller.
*
* Copies data from the page cache. If the data is not currently present,
* uses the readahead and read_folio address_space operations to fetch it.
*
* Return: Total number of bytes copied, including those already read by
* the caller. If an error happens before any bytes are copied, returns
* a negative error number.
*/
ssize_t filemap_read(struct kiocb *iocb, struct iov_iter *iter,
ssize_t already_read)
{
...
}
address_space 对象
Page Cache 中最核心的数据结构就是 address_space,它是一个嵌入在内存页对应的磁盘文件的 inode 中的数据结构。page cache 中的多个内存页可能是属于同一个磁盘文件的,也就是说这些页会被同一个 address_space 引用 (通过上面的 struct page 中的 mapping 和 index 字段指向 address_space),因此 address_space 的主要作用是对内存页进行分组和管理,追踪内存页在磁盘文件中对应的位置,以及跟踪文件数据在进程虚拟地址空间中的映射地址。
通过 address_space 可以实现很多不一样但有关联的服务:缓解内存压力、按地址查找内存页,以及追踪脏页等。它的定义位于 <include/linux/fs.h>:
struct address_space {
struct inode *host;
struct xarray i_pages;
struct rw_semaphore invalidate_lock;
gfp_t gfp_mask;
atomic_t i_mmap_writable;
#ifdef CONFIG_READ_ONLY_THP_FOR_FS
/* number of thp, only for non-shmem files */
atomic_t nr_thps;
#endif
struct rb_root_cached i_mmap;
unsigned long nrpages;
pgoff_t writeback_index;
const struct address_space_operations *a_ops;
unsigned long flags;
errseq_t wb_err;
spinlock_t i_private_lock;
struct list_head i_private_list;
struct rw_semaphore i_mmap_rwsem;
void * i_private_data;
} __attribute__((aligned(sizeof(long)))) __randomize_layout;
其中,a_ops 指向了 address_space 的操作函数表 address_space_operations,看到这个名字大家应该不陌生了,VFS 的四大核心数据结构都有它们自己的函数操作表,VFS 通过这些函数来操作具体的文件系统。而 address_space_operations 也是相似的原理:VFS 所有针对 page cache 的操作都要通过这个函数操作表来实现。
这个函数操作表的定义位于 <include/linux/fs.h>:
struct address_space_operations {
int (*writepage)(struct page *page, struct writeback_control *wbc);
int (*read_folio)(struct file *, struct folio *);
/* Write back some dirty pages from this mapping. */
int (*writepages)(struct address_space *, struct writeback_control *);
/* Mark a folio dirty. Return true if this dirtied it */
bool (*dirty_folio)(struct address_space *, struct folio *);
void (*readahead)(struct readahead_control *);
int (*write_begin)(struct file *, struct address_space *mapping,
loff_t pos, unsigned len,
struct page **pagep, void **fsdata);
int (*write_end)(struct file *, struct address_space *mapping,
loff_t pos, unsigned len, unsigned copied,
struct page *page, void *fsdata);
...
};
这里只简单介绍几个与本文有关联的函数:
read_folio():VFS 调用这个函数经过具体的文件系统把物理页的内容存入 page cache。dirty_folio():虚拟内存调用这个函数把一个或者多个页面标记为脏页。readahead():虚拟内存调用这个函数读取被 address_space 对象引用的内存页。writepage():虚拟内存调用这个函数把一个脏页写回磁盘。使用系统调用如sync()的时候就是通过这个函数来完成。writepages():虚拟内存调用这个函数把 address_space 引用的那些脏页写回磁盘。write_begin():VFS 调用这个函数告知具体的文件系统要准备开始写文件了。write_end():write_begin()返回之后,数据也写入了之后,必须调用这个函数告知具体的文件系统写入操作已完成。
关于 address_space_operations 中每一个函数功能的详细介绍请参考官方文档26,文档里已经都有介绍了,这里便不再赘述。
Buffered I/O
这种借助 Page Cache 来实现的 I/O 称之为 Buffered I/O,也叫 Standard I/O,是大多数文件系统的默认 I/O。
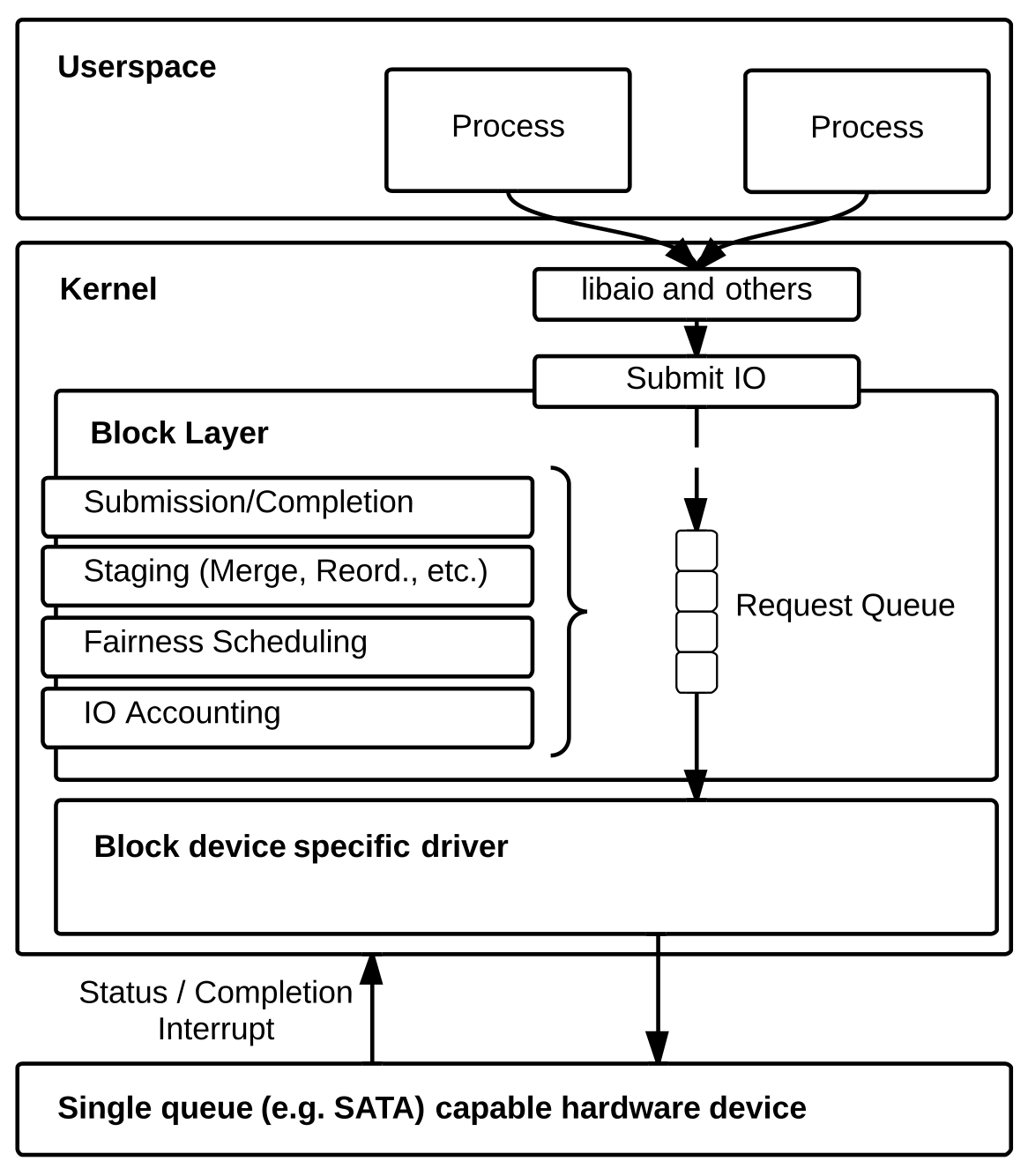
现在让我们来看看在 Linux 中实际的 I/O 过程是怎么样的27:
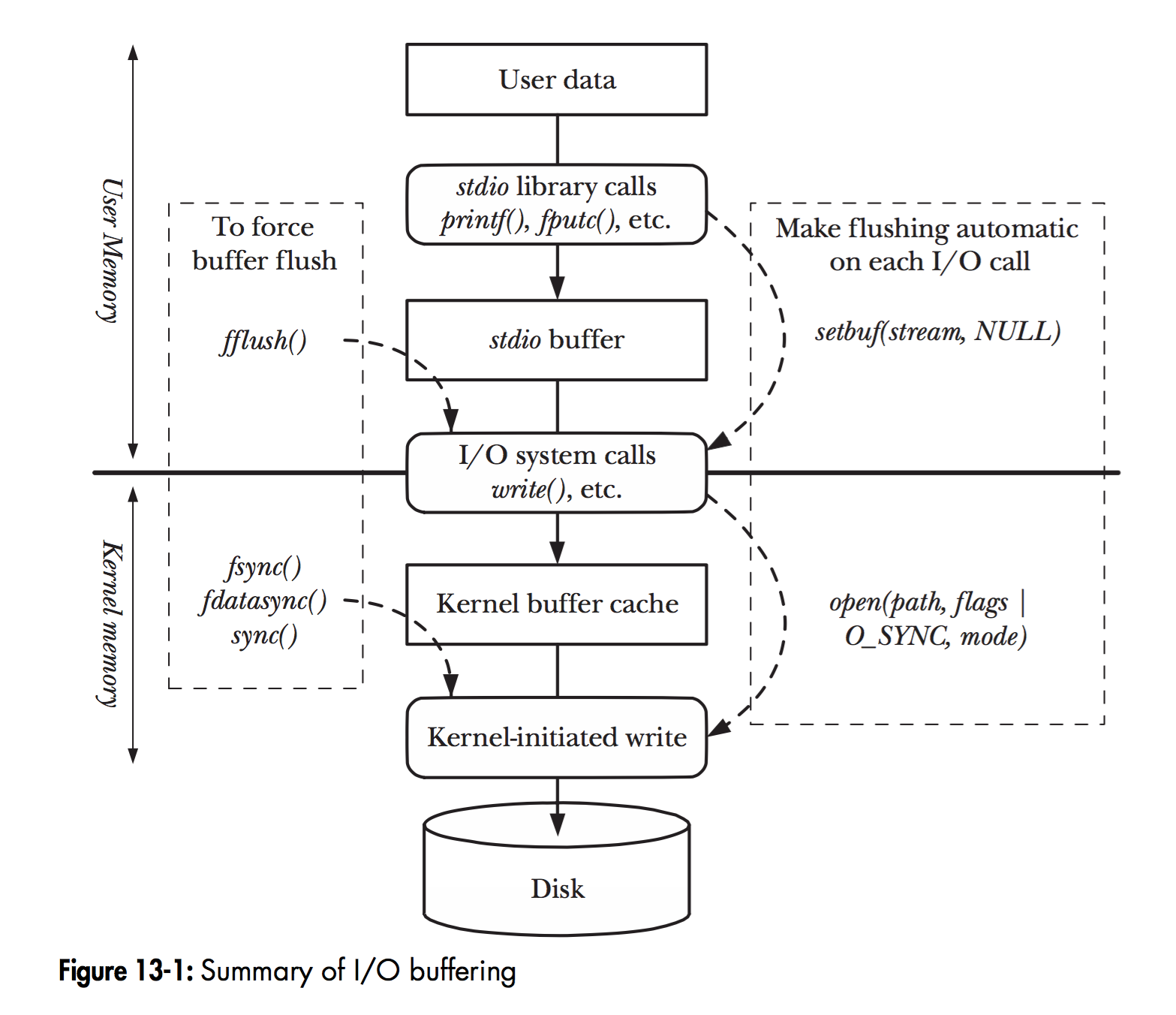
在 Linux 中,当程序调用各类文件操作函数后,用户数据 (User Data) 到达磁盘 (Disk) 的流程如上图所示。
图中描述了 Linux 中文件操作函数的层级关系和内存缓存层的存在位置,中间的黑色实线是用户态和内核态的分界线。
read(2)/write(2) 是 Linux 系统中最基本的 I/O 读写系统调用,我们开发操作 I/O 的程序时必定会接触到它们,而在这两个系统调用和真实的磁盘读写之间存在一层称为 Kernel buffer cache 的缓冲区缓存。在 Linux 中 I/O 缓存其实可以细分为两个:Page Cache 和 Buffer Cache,这两个其实是一体两面,共同组成了 Linux 的内核缓冲区 (Kernel Buffer Cache) :
- 读磁盘:内核会先检查
Page Cache里是不是已经缓存了这个数据,若是,直接从这个内存缓冲区里读取返回,若否,则穿透到磁盘去读取,然后再缓存在Page Cache里,以备下次缓存命中; - 写磁盘:内核直接把数据写入
Page Cache,并把对应的页标记为PG_dirty,添加到 dirty list 里,然后就直接返回,内核会定期把 dirty list 的页缓存 flush 到磁盘,保证页缓存和磁盘的最终一致性。
Page Cache 会通过页面置换算法如 LRU 定期淘汰旧的页面,加载新的页面。可以看出,所谓 I/O 缓冲区缓存就是在内核和磁盘、网卡等外设之间的一层缓冲区,用来提升读写性能的。
Direct I/O
与 Buffered I/O 相对的是 Direct I/O,这种 I/O 要求操作系统绕过 Page Cache 直接和块设备进行 I/O 交互,也就是再也不需要存储额外的缓存数据在内存中,所以也不需要那些 writeback 机制和预读策略等。这部分内容会放到后面的 Zero Copy 的那一章中介绍,这里就先略过。
映射层 (Mapping Layer)
映射层是 VFS 和 Page Cache 下面的一个逻辑层,主要由各种文件系统 (Ext2/3/4、BtrFS、XFS 等等) 和块设备文件组成。这一层的主要职责是在 I/O 操作的过程中提供映射功能:
- 内核通过映射层先确定文件所在的文件系统或者块设备文件上的块大小,然后根据文件所分布的磁盘块数量计算请求的数据长度。在这一阶段,内核还会通过文件描述符 (fd) 找到存储文件数据的所有逻辑块编号。
- 紧接着,映射层需要调用文件系统提供的特定映射函数 (也就是
inode_operations中的函数) 并通过文件描述符 (fd) 访问到磁盘上的 inode,然后根据逻辑块编号找到真正的物理块编号从而找到文件所在的实际物理磁盘位置。需要注意的是,因为文件在物理块设备 (比如磁盘) 中的分布不一定是连续的,所以文件系统会记录所有逻辑块和物理块之间的映射关系,这些关系会保存在 inode 中。
通用块层 (Generic Block Layer)
通用块层 (GBL) 是一个内核组件,负责为系统中的所有块设备处理 I/O 请求,同时屏蔽不同的块设备驱动实现细节,为上层提供一个统一的编程接口。GBL 通过定义了一系列的函数,为 Linux I/O 系统提供以下的功能28:
- 将数据缓冲区放在高端内存 (如果存在) —— 仅当 CPU 访问其数据时,才将页框映射为内核中的线性地址空间,并在数据访问完后取消映射。
- 通过一些附加手段,实现一种称之为"零拷贝"的模式,将磁盘数据直接存储在用户态的地址空间而非内核态的地址空间;事实上,内核为 I/O 数据传输使用的缓冲区所在的页框就映射在用户态的线性地址空间上。
- 管理逻辑卷 (logical volumes) —— 比如那些由 LVM (the Logical Volume Manager,逻辑卷管理器) 和 RAID (Redundant Array of Inexpensive Disks,廉价磁盘冗余阵列) 使用的逻辑卷:几个磁盘分区,即使位于不同的块设备中,也可以被看作是一个单一的分区。
- 发挥大部分新磁盘控制器的高级特性,例如大主板磁盘高速缓存、强化型 DMA 性能、I/O 传输请求调度等。
bio 数据结构
GBL 的核心数据结构是 bio 结构体29:
struct bio {
struct bio *bi_next; /* request queue link */
struct block_device *bi_bdev;
unsigned short bi_vcnt; /* how many bio_vec's */
...
/*
* Everything starting with bi_max_vecs will be preserved by bio_reset()
*/
unsigned short bi_max_vecs; /* max bvl_vecs we can hold */
atomic_t __bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list */
struct bio_set *bi_pool;
/*
* We can inline a number of vecs at the end of the bio, to avoid
* double allocations for a small number of bio_vecs. This member
* MUST obviously be kept at the very end of the bio.
*/
struct bio_vec bi_inline_vecs[];
};
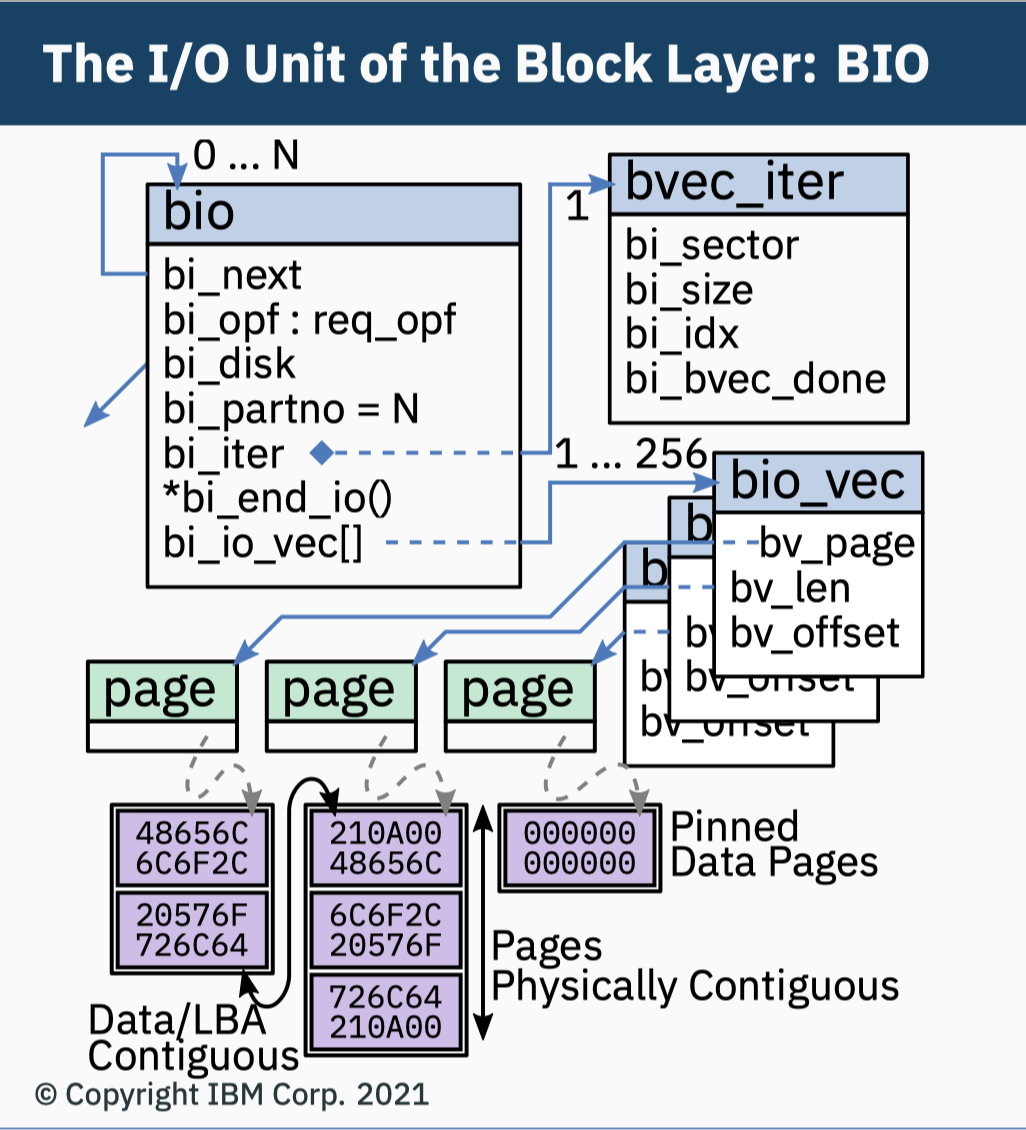
bio 是块设备 I/O 操作的抽象,它为上层屏蔽了底层不同的块设备驱动的实现细节,将 I/O 操作统一化了。就如同前面介绍的 VFS 所做的事情一样。bio 描述了从上层提交过来的一次活跃的 I/O 操作,由一系列片段 (segment) 组成的链表。一个片段代表一小块连续的内存 buffer,也就是说某些单独的 buffer 就不要求一定得是连续内存,通过使用片段来描述这些 buffer,bio 不仅能描述简单的单一且连续的块 I/O 操作,而且能描述多重且分散的块 I/O 操作,也就是 vector I/O 向量 I/O,使得内核可以处理这些不同的块 I/O 操作。
I/O vectors
bio 中的每个片段都是由一个 bio_vec 结构体表示30:
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};
bio 结构体中的 bi_io_vec 字段就是指向到一个 bio_vec 数组,该数组由一个特定的块 I/O 操作所需要的所有片段组成。每一个 bio_vec 都描述了一个特定的 I/O 片段:该片段所在的物理页、块在物理页中的起始偏移地址,以及块数据的长度。这个片段就代表了一个连续的内存 buffer。bi_vcnt 则代表了 bi_io_vec 链表的长度。
当 GBL 收到一次新的块 I/O 操作请求时,就会调用 bio_alloc() 函数分配一个新的 bio 对象 (通常是由 slab 分配器分配的),如果此时内存不足,那么内核就会使用一个备用的小内存池来分配内存。每个 I/O 请求包含一个或多个块,存储在 bio_vec 数组中,每一个元素都记录了当前片段在物理内存页中的实际地址,一共有 bi_vcnt 个片段。__bi_cnt 则记录了其所在的 bio 的引用计数,当这个值减少为 0 的时候,当前 bio 结构体就会被销毁,其所占用的内存也会被回收。引用计数的管理是通过以下两个函数来完成的:
static inline void bio_get(struct bio *bio);
extern void bio_put(struct bio *);
bio_get() 增加计数,bio_put() 减少计数,内核在开始使用每一个新创建的 bio 的时候都需要先调用 bio_get(),以避免在使用过程中该 bio 被意外地销毁掉,使用完毕之后则要调用 bio_put() 减少计数,以求那些引用计数已经归零的 bio 能尽早被回收。bio 的构成如下31:
I/O 调度层 (I/O Scheduling)
从通用块层下来的 I/O 请求并不会直接就提交到块设备驱动层,因为这些 I/O 请求的数量和顺序从执行性能上来看对于块设备来说通常不会是最优解,所以最好能把这些请求优化一下再推送到下层去。Linux 因此在通用块层和块设备驱动层之间嵌入了一个 I/O 调度层,用以对那些从上层流入的 I/O 请求进行优化 (主要是合并和排序)。
为了能更好地应对来自上层海量 I/O 请求,I/O 调度层设计了一个 staging area (暂存区),主要的目的是为了异步处理任务以及进行流量削峰 (或者说流量控制),为下层的块设备驱动程序缓解压力,否则的话内核有可能会被流量淹没而挂掉,暂存区是基于块设备 I/O 请求队列来实现的,这个队列由 request_queue 结构体表示32:
struct request_queue {
/*
* The queue owner gets to use this for whatever they like.
* ll_rw_blk doesn't touch it.
*/
void *queuedata;
struct elevator_queue *elevator;
const struct blk_mq_ops *mq_ops;
/* sw queues */
struct blk_mq_ctx __percpu *queue_ctx;
/*
* various queue flags, see QUEUE_* below
*/
unsigned long queue_flags;
unsigned int rq_timeout;
unsigned int queue_depth;
refcount_t refs;
/* hw dispatch queues */
unsigned int nr_hw_queues;
struct xarray hctx_table;
struct percpu_ref q_usage_counter;
struct request *last_merge;
spinlock_t queue_lock;
int quiesce_depth;
struct gendisk *disk;
...
};
做过大型业务系统的读者应该对这个设计不陌生,其实对应的就是 MQ (Kafka, RabbitMQ, Pulsar 等)。
I/O scheduler
I/O 调度程序的职责是管理块设备的 I/O 请求队列,它会根据相关的算法来优化队列中的请求的顺序和数量,然后决定应该在什么时候将优化后的 I/O 请求推送到下层的块设备驱动层去。I/O 程序的优化工作基本是围绕着降低 I/O 操作的磁盘寻址时间从而提升 I/O 系统的全局吞吐量来做的,因为对于 HDD 磁盘来说,磁盘 I/O 的性能瓶颈主要集中在磁盘的寻址操作上,核心的优化策略就是合并与排序。这里之所以强调全局,是因为在优化的过程中可能无法做到公平对待每一个 I/O 请求,也就是说为了全局最优可能会牺牲掉一些局部最优,就像是选择动态规划算法 (全局最优) 而非贪心算法 (局部最优) 一样。
一个 I/O 请求可能会操作多个磁盘块,因此每个请求可以包含多个 bio 对象。一开始,GBL 会构建一个只含单个 bio 的 I/O 请求,然后 I/O 调度程序在有需要的时候要么向这个初始的 bio 插入一个新的片段,要么把另一个新创建的 bio 整个链接到初始 bio 的后面,从而扩展该 I/O 请求。I/O 请求队列的简化结构如下4:
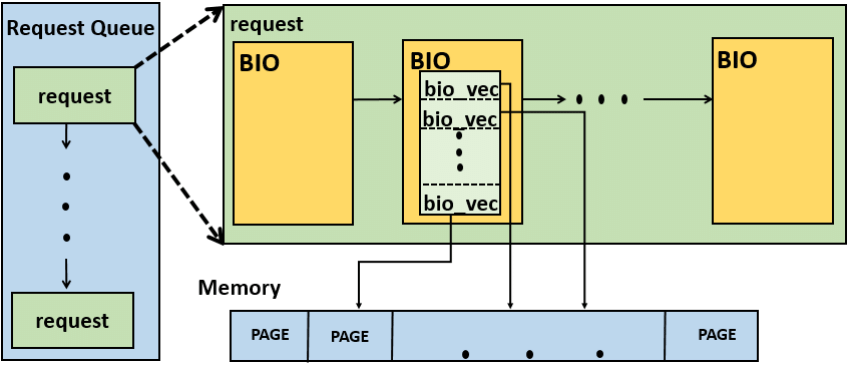
前文已经提到过,I/O 调度程序的核心优化手段就是对 I/O 请求进行合并与排序。
合并,是指将多个请求合并成单个的优化。我们可以通过一个例子来理解:用户进程通过 VFS 读取一个文件中的部分数据 (从底层的视角看就是读取磁盘中的块和扇区),此时 VFS 会向下层提交一个 I/O 请求,经过层层包装和转发最终来到了 I/O 调度层进入缓冲队列,如果当前队列中已经有了另一个 I/O 请求,其请求读取的是同一个文件的数据,而且数据所在的磁盘扇区和这个新来的请求访问的磁盘扇区是相邻的 (当前扇区的紧邻的前一个扇区或者后一个),那么这两个请求完全可以合并为一个访问多个连续扇区的新请求。请求合并之后,原先的对多次磁盘的多次寻址操作就会被压缩成一次,也就是原先的请求需要多条磁道寻址命令,现在只需要一条寻址命令就能取回所有请求的磁盘数据,大大地降低了系统开销。
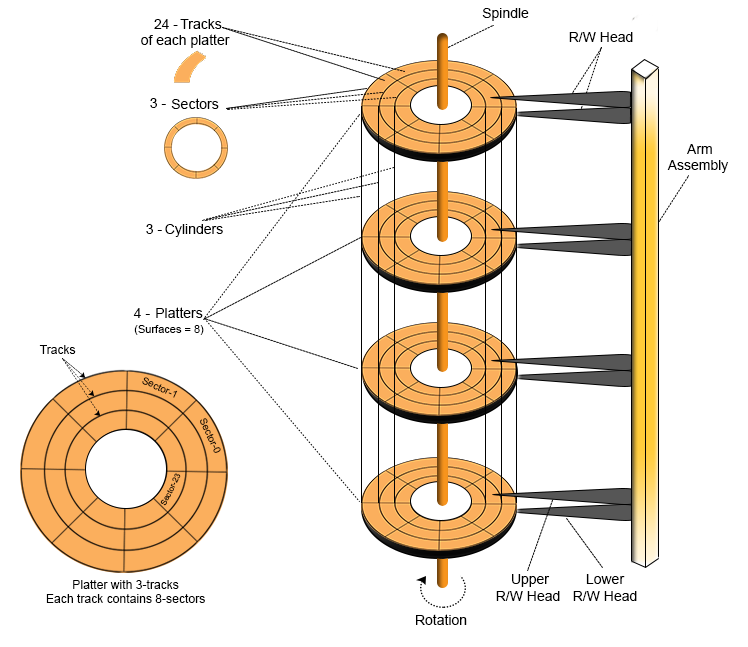
排序,是指把那些随机访问块设备地址的 I/O 请求变得有序。还是通过一个例子来理解:假设一个 I/O 请求进入 I/O 调度层的队列之后,队列中并没有其他尝试访问与该请求的相邻扇区的 I/O 请求,看起来这种情况下 I/O 调度程序就无法做合并优化而只能选择将这个 I/O 请求插入队列尾部,但是我们再进一步思考一下,既然没有找到相邻扇区的 I/O 请求,那么可不可以退而求其次把要求降低一点,只要是相近的扇区就行,然后就按照地址增长的方向进行排序,把这两个 I/O 请求在队列中的位置调整成相邻的前后顺序。虽然因为扇区不相邻而无法像合并优化那样能够把多个 I/O 请求的多次磁道寻址操作压缩成一次,但是因为扇区是按照地址增长方向排列的,那么磁头的寻址操作就会更加方便和高效。这是什么原理呢?我们先来看一下磁盘的结构,一个磁盘由多个盘片组成的,盘片由一圈圈的多个磁道组成,每个盘片上对应一个磁头,所有磁头都焊接在一个机械臂上。磁盘的寻址操作是通过两种机械运动来实现的:盘片围绕主轴的旋转运动和机械臂控制磁头沿着盘片的半径从内向外的直线运动。前者产生的寻址延迟时间被称之为旋转时间,后者则是寻道时间。一般来说,寻道时间要远大于旋转时间,所以按顺序访问分布于同一个磁道的数据要比访问分布于不同磁道的数据快很多。即便是位于不同磁道的数据,只要是按地址增长方向去访问,磁头虽然必须走直线运动,但也只需走单一方向 —— 从内到外,如果是随机地址的访问,那磁头很可能要经常变换方向,寻址性能就会下降。这就是 I/O 调度程序的排序优化的基本原理。
HDD 机械硬盘的结构33:
I/O 调度程序从实现上又分为单队列 (下文统一简称为 SQ) 架构和多队列 (下文简称为 MQ) 架构,分别对应 HDD 硬盘和 SSD 硬盘:单队列 I/O 调度架构服务于 HDD 硬盘,多队列 I/O 调度架构服务于 SSD 硬盘。
HDD VS SSD34:

单队列 I/O 调度程序 (Single-queue I/O schedulers)
Single-queue 顾名思义就是单一队列,这里的单一队列指的是硬盘的 I/O Submission 和 I/O Completion 队列,这两种队列在每一块硬盘上各配备一条,也就是全局的单一队列,所有针对该硬盘的 I/O 请求共享,早期的大部分 SATA/SAS 接口的硬盘都是这种 SQ 架构。SQ 架构很容易会让人担心存在性能瓶颈,但是在 HDD 磁盘占主流的年代,I/O 操作的性能瓶颈主要集中在磁盘本身,也就是磁盘寻址和磁盘读写,通常 HDD 的随机 I/O 只能达到几百 IOPS (input/output operations per second),所以 SQ 架构对于 HDD 硬盘的性能需求来说已经足够了。到后来 SSD 硬盘的出现,极大地提升了磁盘本身的性能,才反转了局面,使得 SQ 架构成为了性能瓶颈,跟不上磁盘本身的速度了。关于这方面的内容,我们会在下一节讲解。
SQ I/O 调度的工作原理如下35:
Linus 电梯算法
Linus 电梯算法是第一个 I/O 调度算法,在 2.4 版内核中首次引入。其原理遵循我们前面介绍的合并与排序优化:检测到新 I/O 请求进入队列的时候,它就会逐一检查当前队列中的每一个待处理的 I/O 请求是否可以与新请求合并,如果可以就合并请求;否则的话,它就会尝试按照磁盘扇区地址的顺序为这个新请求在队列中寻找合适插入点 (排序优化),如果找到便直接插入,要是没找到合适的位置,就将其插入到队尾。
Deadline 算法
工作原理如下36:
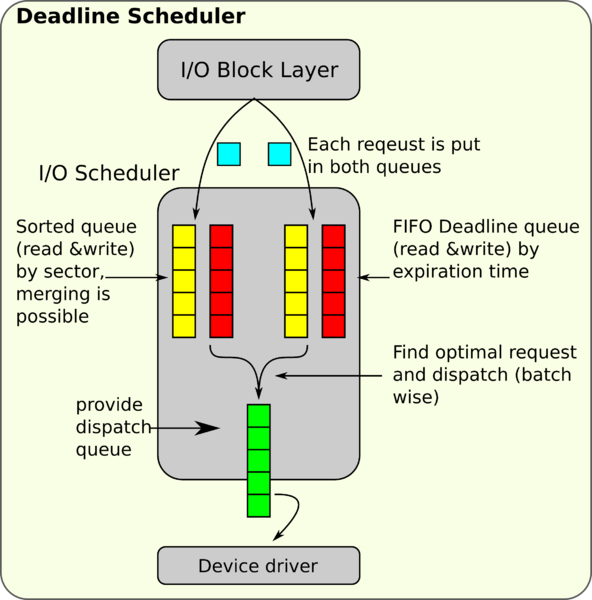
Deadline 算法是为了解决 Linus 电梯算法所带来的饥饿问题而引入的。所谓的饥饿问题,主要是由于合并和排序优化过后,很容易形成磁盘的局部热点,也就是磁盘的某一片区域的 I/O 操作过多,导致其他区域的 I/O 请求一直没有机会被执行。
2.6 版本的内核因此引入了 Deadline 算法,它的工作原理基本和 Linus 电梯算法是一样的,但是它为每一个 I/O 请求加上了过期时间,默认情况下,读请求是 500ms,写请求是 5s,之所以读请求的过期时间要远小于写请求是因为在 Linux I/O 系统中读请求要比写更重要,或者应该说更紧急,因为有 Page Cache 层的存在导致了写操作是异步(非阻塞)的,但是读操作依然还是同步(阻塞)的,所以 I/O 调度程序要尽量保证先执行读请求以求能尽快返回结果给用户进程。
这个算法中有两种队列:Sorted Queue —— 将 I/O 请求按磁盘地址排序并尝试合并,FIFO Queue —— 将 I/O 请求按过期时间排序,FIFO Queue有两条,分别存放读请求和写请求,当这两个队列头上的 I/O 请求过期之时,调度程序就会从队头把请求取下来推送到下层去执行,这样就保证了每一个请求都会有机会被处理,避免了饥饿问题;Sorted Queue 一开始也有两条,分别存放读写请求,后来的内核版本中合并成了一条。而且因为读请求的过期时间相比写请求要短得多,这个算法对多读少写的场景更加友好,因此该算法比较适合 I/O 密集的应用,比如数据库。
CFQ (Completely Fair Queueing) 算法
工作原理如下36:
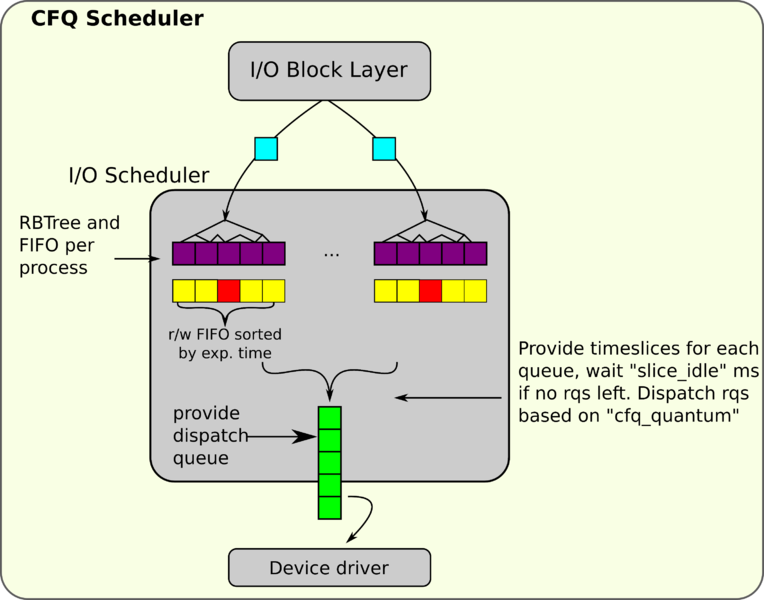
CFQ 算法的主要目标是尽量公平地把磁盘 I/O 带宽分配给所有的用户进程。它为每一个用户进程都分配了两个 I/O 请求队列:Sorted Queue 和 FIFO Queue,这两种队列的功能和 Deadline 算法中的同名队列是一样的,但是也有一些区别:前者使用红黑树实现,后者存放所有 I/O 请求。CFQ 算法以时间片轮询调度队列,每一轮都从每个队列中取出一定数量 (默认是 4,可更改) 的 I/O 请求数进行调度。这样就能保证所有进程的 I/O 请求按照一种公平的方式进行调度,每个进程分到的磁盘 I/O 带宽基本是一样的。
这个算法是专门为多媒体设备 (音视频) 和个人电脑而设计的,比如说个人电脑,用户通常会同时开启多个任务一起执行,比如写文档的时候听音乐,同时还在下载东西,这个时候要公平地协调系统的 I/O 资源,保证用户能同时执行这些任务而不会卡顿,虽说这个算法很适合多任务系统,但是因为 CFQ 算法的通用性,所以它在其他场景也能运行得很好。
Noop (No-operation) 算法
工作原理如下36:
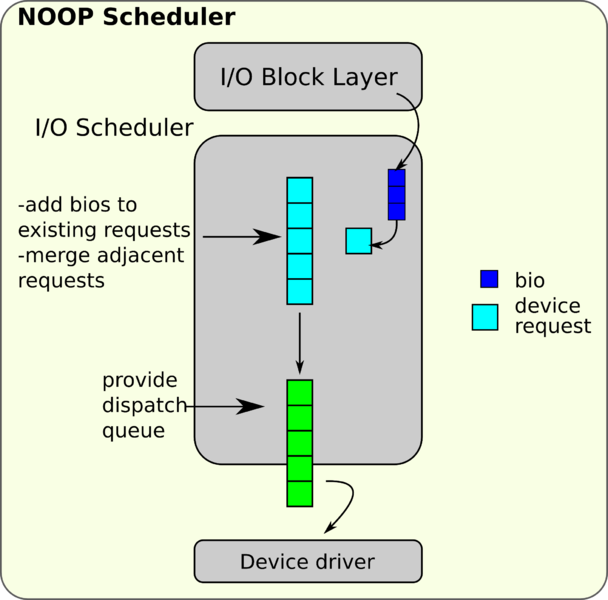
这是 I/O 调度程序实现的最简单的调度算法,其核心逻辑是只应用合并优化而放弃排序优化。这个算法是专门为随机访问设备而设计的,比如 Flash 闪存盘,RAM 盘等,也非常适合那些能够提前把 I/O 请求排好序的高级存储控制器。SQ I/O 调度程序的算法都是针对 HDD 也就是机械硬盘而优化的,而这些优化对于 SSD 固态硬盘来说基本没有什么意义了,所以 SQ 架构的 I/O 调度程序及其算法都在 5.0 版内核之后被陆陆续续地移除掉了,要发挥出 SSD 的最大性能,最好是选用下一节要介绍的 MQ 架构。当然,SQ I/O 调度程序在 SSD 上也可以工作,这种情况下这几种 SQ I/O 调度算法的性能差别不大,而 noop 算法反而因为实现简单而比 CFQ 和 Deadline 算法要更省 CPU 资源,因此如果一定要在 SSD 用 SQ I/O 调度的话,最好选择 noop 算法。
多队列 I/O 调度程序 (Multi-queue I/O schedulers)
随着 SSD 硬盘逐渐取代 HDD 硬盘成为主流,磁盘的 IOPS 也如同坐火箭般高速飞升,随机 I/O 的 IOPS 从原来的几百到现在的十万级甚至未来的百万级。于是局面反转了,原先的性能瓶颈在磁盘,现如今转移到了 Linux 内核的 SQ I/O 调度程序上,再加上以 NUMA (Non-Uniform Memory Access) 多核架构和 NVMe (Non-Volatile Memory express) 通信协议的横空出世,计算机系统的多核处理与数据传输能力也与日俱增,更是进一步加剧了内核的 SQ I/O 调度架构的性能滞后。因此内核亟需引入新的 I/O 调度架构来跟上 SSD 的速度,将 SSD 的速度潜能都发挥出来。于是 Linux I/O Block Layer 的 maintainer —— Jens Axboe (同时也是 CFQ/Noop/Deadline I/O 调度器、splice() 和 io_uring 的作者) 再次出手,设计了 Multi-queue I/O scheduler,补齐了这一部分的性能差。
根据 Jens Axboe 等内核开发者的调研,他们总结出了 SQ I/O 调度程序在扩展性方面的三个主要的问题35:
-
请求队列锁:SQ 在并发处理的场景下带来的是粗粒度的锁机制和激烈的锁竞争:
- 从队列插入或者移除 I/O 请求时需要加锁;
- 对 request queue 进行其他任何操作也需要加锁;
- Block layer 对进行 I/O 请求进行堆积优化 (堆积 I/O 请求最后让硬件一次性处理,期间还可以对请求进行合并优化) 时需要加锁;
- I/O 请求重排的时候需要加锁;
- 对 I/O 请求进行公平性调度的时候还需要加锁;
上述的场景全部都需要加锁才能进行,导致了剧烈的锁竞争。
-
硬件中断:高 IOPS 伴随着高频次的硬件中断,当下大部分存储设备都被设计成由一个 CPU 全权负责处理所有的硬中断,不论 I/O 请求是不是它自己发出的,它都会通过软中断的方式转发给其他 CPU。结果就是这个 CPU 需要耗费大量的时间处理硬中断、上下文切换和刷新 L1/L2 缓存 (这些缓存本来可以用来为上层应用加速其数据访问)。而且其他 CPU 也必须接受这个来自主 CPU 的 IPI (inter-processor interrupt,处理器间中断) 然后停止手头上的工作去走一遍 I/O 处理的流程 (即便这个 I/O 请求不是它发出的)。因此,在大多数情况下,仅处理一次 I/O 请求就需要两次中断和上下文切换。
-
远端内存访问:NUMA 架构下,如果处理 I/O 请求的过程中发生跨核的内存访问 (或者是跨 socket 也就是 CPU 槽),那么队列锁竞争的情况会进一步恶化。不幸的是,当一个 I/O 请求最终被交付给另一个 CPU 而非那个最开始发起 I/O 请求的那个 CPU 时,这种远端内存访问就必定会发生。那样的话,根据 MESI 协议37,一个 CPU 尝试加锁去取队列中的 I/O 请求的行为就会触发一个远端内存访问到那个最后加锁成功并保存锁状态到其缓存行中的 CPU,然后这个 CPU 缓存就会被标记成共享状态并最终导致缓存失效。如果多个 CPU 一直在发起 I/O 请求然后竞争队列锁,那么锁状态就会一直在多个 CPU 缓存之间反复横跳,极大地降低 CPU 的处理效率。
基于以上的原因,内核团队为 NUMA 架构的机器重新设计了一个全新的 MQ I/O 调度层,主要的目标和难点是降低锁粒度 (减少锁竞争) 和跨核内存访问35:
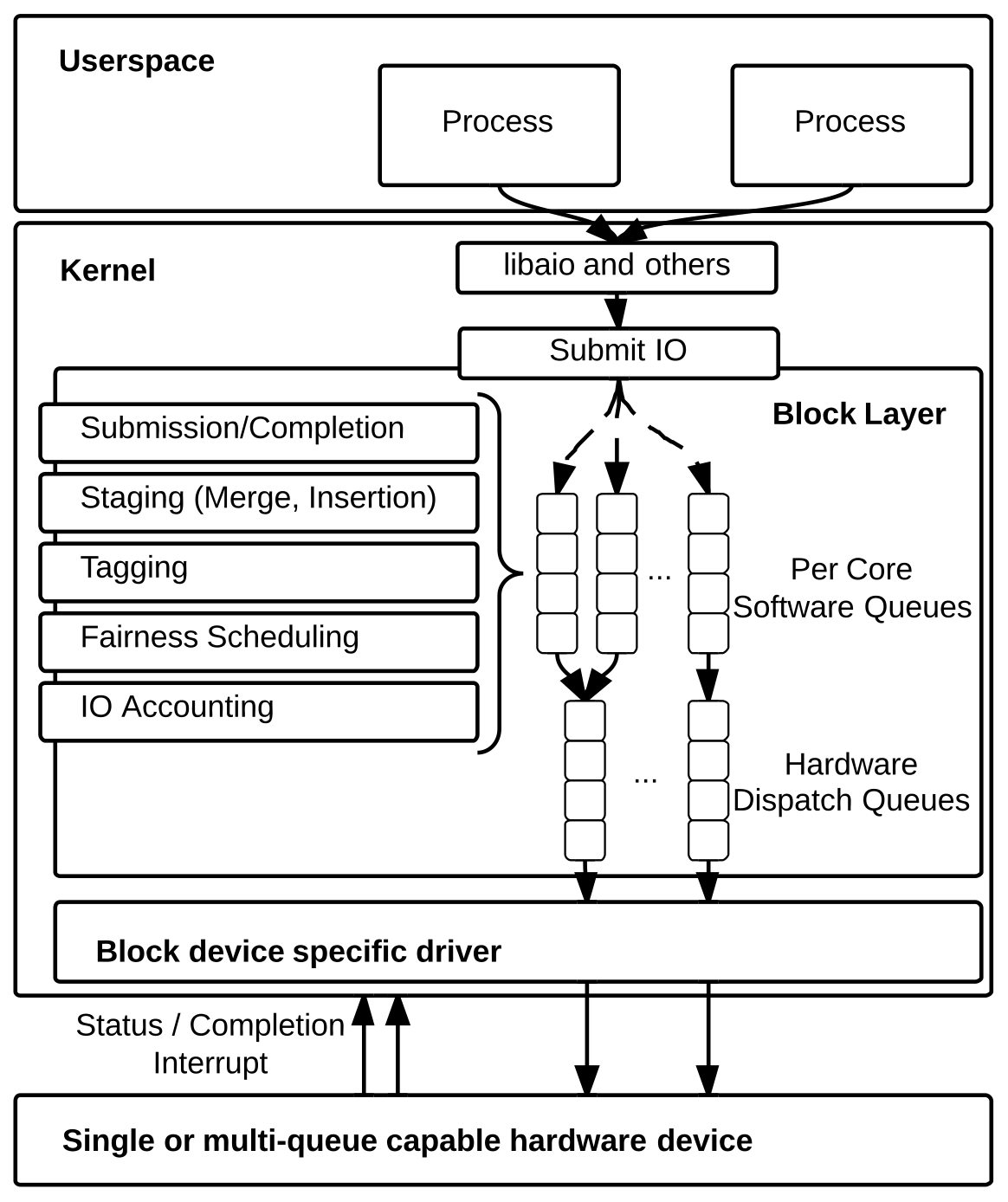
既然要改造旧系统,那么必须先明确我们的需求和目标,也就是我们期望新架构最终能达成哪些成果,内核团队提出的主要需求是35:
- 保证单个设备上的 I/O 公平性:多个用户进程可能会共享一块设备,为了避免某一个进程的 I/O 操作一直占用设备导致其他进程被饿死,内核的 Block Layer 需要解决这个问题。以往的 SQ 架构中,会使用 CFQ 和 Deadline 等算法对请求进行合并与排序来保证这个公平性。如果 Block Layer 不做这个事情的话,那么就要么需要上层的多个用户程序协调彼此的执行顺序,要么就让硬件设备的内部实现来保证 I/O 的公平性 (事实上现在的大多数 SSD 都有这个功能)。
- 提供更友好的存储设备 accounting (中文里没有很好的对应翻译,其实就是能更方便地提取设备运行过程中的监控和统计数据):Block layer 应该要为系统管理员提供更方便的手段去调试和监控存储设备。最好是能提供一个统一的性能监控和统计的接口,可以让用户程序和内核组件能够利用这个接口去实现一些优化策略:程序调度、负载均衡和性能调优。
- 设置块设备 I/O 的暂存区:前面我提到过 SQ 架构里的队列的核心功能之一就是进行流量控制 (削峰),MQ 架构下也同样需要一个 staging area 暂存区,有了它,我们不仅可以缓冲海量的 I/O 请求以便我们对它们进行合并和排序优化,而且还能在底层设备过载的时候,调控 I/O 请求的速率,进行限流,以减轻设备的压力,避免引发硬件问题。
明确了需求之后,我们就可以着手设计新架构了,整个架构的核心是一个两级队列的设计,通过引入这个两级队列来降低队列锁粒度和减少锁竞争,同时还能简化原先那复杂的调度算法,将部分系统复杂度下沉到硬件设备层,其核心要点分为软件和硬件两个层面35:
- Software Staging Queues 软件暂存队列 (下文简称为 SSQ):将原来的那个 SQ I/O 队列改造成可调整的 MQ (可配置任意的队列数量,甚至可以退化成单队列),同时为 NUMA 的每一个 socket (CPU 槽) 配备一个 I/O 队列,也可以为每一个 core 配备一个。这样的话,一个带有 4 个 6 核的 socket 的 NUMA 系统,它的 I/O 队列数的范围在 4 ~ 24 个之间。如此便能极大地减少锁竞争。在多数 CPU 都提供了大容量 L3 cache 的现状下,一个 socket 里的多个 cores 即便是共享 L3 也足够快了,没必要让每个 core 再独占一个 I/O queue。所以每个 socket 配备一个 I/O queue 通常是一个性价比较高的选择。
- Hardware Dispatch Queues 硬件调度队列 (下文简称为 HDQ):I/O 请求从 SSQ 出来之后,不会被直接推送给下层的块设备驱动程序,而是会被发送到一个硬件调度队列 HDQ,这个队列是由磁盘驱动提供的,队列数量通常取决于设备驱动支持的硬件上下文 (contexts) 数量,设备驱动会基于 MSI-X (Message Signal Interrupts) 标准提供 1 ~ 2048 个队列。大部分 SSD 只提供了一个队列。在针对 SSD 的 MQ 架构下,通常不再需要 I/O 请求基于磁盘地址保持全局有序,也就是可以不用再执行排序优化了,而是让硬件为每一个 NUMA node 或者 CPU 配备一个本地队列从而避免跨核内存访问。
硬件调度队列 HDQ 的数量
HDQ 的数量在内核的 I/O Scheduling 架构的演变过程中可以说是扮演着核心角色,单队列和多队列架构指的就是 HDQ 的数量。这个地方特别容易引起混淆,所以要专门澄清一下:很多人以为 SQ 和 MQ 指的是的内核的 request queue (也就是 SSQ,软件层面),实际上这两个概念真正代表的是硬盘的 I/O Submission 和 I/O Completion 队列 (也就是 HDQ,硬件层面)。如果不理解这一点,那么很容易在阅读上一节内容的时候感到困惑:如果 SQ 指的是 request queue,虽然 noop 和 deadline 算法可以算是单一 request queue,但是 CFQ 算法明显有多条 request queues,怎么也算到 SQ 架构里了?因此,在这里要拨乱反正,SQ 和 MQ 是针对 HDQ 提出来的概念。
目前,SATA 协议的 SSD 只支持单 I/O 队列 (一条 I/O Submission 队列和一条 I/O Completion 队列),队列长度 32 (也就是 TCQ 和 NCQ);SAS 协议的 SSD 可以支持最多 256 条长度为 256 的队列,而 NVMe 协议的 SSD 则支持最多 64K 条长度为 64K 的队列38。
相信各位都能看出来 NVMe 在这几种主流的 SSD 协议/接口中是鹤立鸡群的存在。事实上,NVMe 作为一种专为 SSD 而生的协议,其技术非常出众,在存储空间、读写速度和兼容性方面都优于其他的协议,IOPS 最高能达到百万级。这其中,I/O 队列的设计可谓是居功至伟:NVMe 为每个 CPU 核心提供至少一个 I/O Submission 和 I/O Completion 队列,这种多队列设计相较于单队列可以避免核心之间的锁竞争,在 NUMA 架构下还能避免跨核内存访问,进一步提升性能。NVMe 还支持了 Vector I/O,最大限度地减少了跨核数据传输的开销,甚至可以根据工作负载调整 I/O 优先级。
NVMe 多 I/O 队列设计39:

虽然未必所有的 Linux 设备都能用上基于 NVMe 协议的 SSD 的多 HDQ,但是 Linux 的 I/O 调度程序经过改造之后,从 SQ 架构转向了 MQ 架构,设计了多个 SSQ 取代了原先的单一 Request Queue,因此即便所用的硬盘上只有一条 HDQ,从 SQ I/O 架构切换到 MQ 架构还是能带来可观的性能提升。
Tagged I/O & I/O Accounting
SSD 的工作原理可以简单地概括如下40:
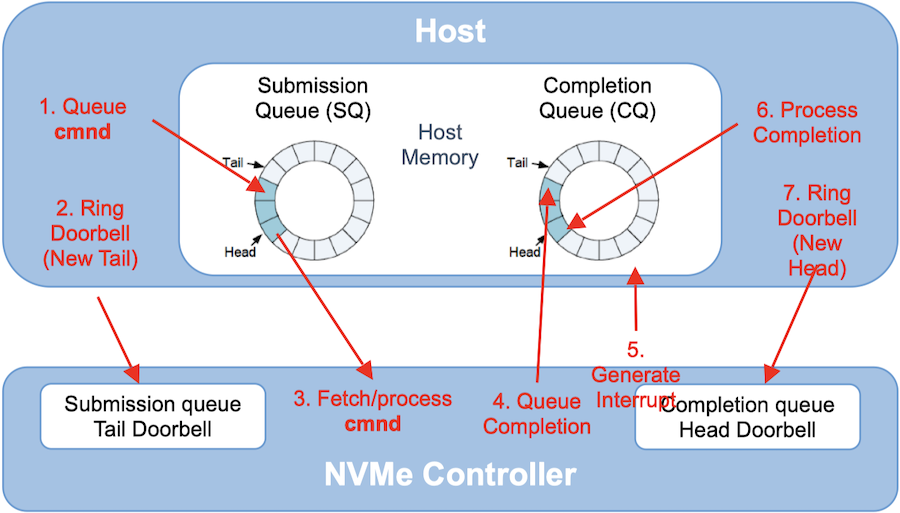
主机往其内存 (或者硬盘的内存) 中的 I/O Submission 环形队列写进一个 I/O 命令 (command, 主机驱动硬盘工作的原理就是通过一个个的 I/O command),同时往一个叫 doorbell 的寄存器里写入一个 I/O 命令就绪的信号,然后 NVMe SSD 的控制器按照命令的接收顺序或优先级顺序从队列中取出 I/O 命令并执行,完成之后便往 I/O Completion 队列写入命令已完成的状态,随后向主机发出一个中断信号。主机收到之后会记录下 I/O Completion 队列中的命令已完成状态,最后清除掉 doorbell 寄存器里的内容。
上述的这个过程在早期的时候是没有对 I/O 命令进行标记的,所以导致命令完成之后,I/O 调度程序还要对队列进行线性扫描,找到已完成的命令,有点低效,后来在 NCQ 技术被引入 SSD 之后,支持了给 I/O 命令生成一个整型数标签 (范围是 [0, len(HDQ)]),然后在命令执行完成之后被回传给内核,这样内核就能通过这个标签直接定位到是哪个 I/O 命令执行完了。内核的 MQ I/O 调度程序在这里还做了一个优化:在内核的软件层就提前生成了每个 I/O 命令的标签并随之一起推送到 HDQ 里,这样的话 SSD 就不用自己生成标签了,直接复用就行。
另外值得一提另一个优化是优化了内核的 accounting 库,以此实现了更加细粒度的统计功能,同时考虑了 SSQ 和 HDQ;而且还修改了 blktrace 现有的 tracing 和 profiling 机制,以适配那些多队列的 SSD 设备。
软硬件分离的 I/O 调度
I/O 调度层的两个主要的优化手段:合并与排序,其中排序是专门针对 HDD 硬盘的优化。前面我已经讲解过机械硬盘的寻址过程,HDD 的 I/O 寻址是基于机械运动,受限于物理盘片、磁头和机械臂,所以其随机 I/O 的性能比较差,从 HDD 的结构上也能看出来,如果执行随机 I/O 需要不断地驱动机械臂移动磁头以及转动盘片,效率很低,所以早期的内核 I/O 调度才需要设计专门的算法对 I/O 请求进行排序,其本质就是避免随机 I/O,优先执行顺序 I/O,提升性能。但是 SSD 硬盘完全由电子元件组成,其中三个核心组件是 NAND 闪存 (flash) 或者 DRAM、主控芯片 (控制器)、固件。所以 SSD 的 I/O 是基于电磁原理甚至是量子力学,其内部寻址和读写都是通过主控芯片利用固件程序执行数据读写、自动信号处理、耗损平衡、错误校正码 (ECC)、坏块管理、垃圾回收算法、与主机设备(如电脑)通信,以及执行数据加密等任务。因此即便 SSD 的存储还是基于块 (block) 的,但是随机寻址对于 SSD 来说已经不是什么性能瓶颈了,虽然顺序 I/O 通常还是要比随机 I/O 更快一点,但二者可以说基本持平,不会有 HDD 那样的数量级差距。
基于上述的事实,既然使用 SSD 的随机 I/O 基本不会拖累性能,而且随着 TCQ 和 NCQ 等技术的出现,软件层面的 I/O 请求排序也变得越来越没有价值,于是内核的 MQ I/O 调度程序开始摒弃那些早期的复杂排序算法,而只是简单地基于 FIFO 原则将每一个 I/O 请求按顺序插入到发出该请求的 CPU 的专属 SSQ 中,然后执行合并、打标签和其他优化之后就推送到 HDQ 中,让块设备直接去执行。MQ I/O 调度程序之所以摒弃排序优化而保留合并优化,是因为合并优化的收益更大,因为即便是在 SSD 上,多个小 I/O 请求合并成一个大请求对性能的提升也是立竿见影的。当然,MQ 架构并没有把排序优化完全封死,还是预留了对 MQ 的全局重排序的可能性,如果磁盘制造商想再进一步把随机 I/O 重排成顺序 I/O 从而再加速一下读写的话,则可以自己在固件程序中实现排序优化,就算是要把排序优化重新加回到内核的 I/O 调度程序中,内核维护者们也是持开放态度的。最后通过将这部分的系统复杂度下沉到硬件层,MQ I/O 调度程序的实现更加的精简和高效。
Multi-Queue Block IO Queueing Mechanism (blk-mq)
最后就是 MQ 架构在内核中的各种具体实现了。blk-mq 是内核的 Block Layer 中多 I/O 队列框架,也就是我们这一章节所述原理的具体实现。
MQ-Deadline Scheduler
MQ-Deadline 是内核从 SQ 往 MQ 架构转变的过程中的第一个 MQ 实现,这个 mq-deadline scheduler 是直接从 SQ 中的 deadline scheduler 重构而来的一个改版,专门针对多队列设备而改造,其特定是通用性很好、实现简单、调度过程中 CPU 开销很低。
BFQ (Budget Fair Queueing) Scheduler
BFQ 调度器在 4.12 内核中首次实现41,是一种"比例配额" (proportional-share) 的低延迟 I/O 调度器,支持 cgroups。代码实现很复杂,所以调度过程中的 CPU 开销比较大,同时追求 I/O 调度的低延迟 (尤其是在那些速度较慢的块设备上),为了达成这个目标甚至可以牺牲掉 I/O 的吞吐量,因此这个调度器并不适合那些 CPU 性能较差或者硬盘吞吐量较高的设备。
BFQ 的架构是从 CFQ 借鉴过来的,同时也借鉴了大量的代码。其公平性调度是主要是基于 I/O 请求的扇区数 (HDD 的说法,SSD 的话则是储存颗粒,总之本质是数据多少),而不是时间片 (当需要保持高吞吐量的时候可能会切换成时间片),它会将设备的带宽按权重比例在进程(组)之间进行分配,权重的计算和进程的工作负载和其他设备参数都无关,只和 I/O 请求的优先级有关;工作方式是启发式调度。BFQ 在默认配置下会优先考虑延迟而不是吞吐量,所以如果你的场景是高吞吐量,那么就需要关闭所有低延迟的启发式方法的选项:将 low_latency 设置为 042。关于如何在延迟和吞吐量之间权衡配置,以官方文档为准。
BFQ 比较适合多媒体设备,比如个人电脑,或者是一些为实时应用服务的后端服务器,比如视频直播、游戏等。事实上,如果使用了比较高端的 SSD 设备,由于 SSD 内部有足够多的硬件优化,内核 (软件层) 的 I/O 调度能带来的性能提升相比之下可能是小巫见大巫了,再考虑到 I/O 调度引入的复杂性,这种情况下使用另一个简单一点的调度器可能是更好的选择。
Kyber I/O Scheduler
Kyber 调度器也是在 4.12 内核中实现的41 (和 BFQ 调度器一起),也是一种较复杂的调度器,但这个复杂是相对 mq-deadline 以及下一节要介绍的 none 调度器而言的,如果是和 BFQ 对比,那这点复杂度是不足为惧的,其实现代码还不到一千行。Kyber 专为高性能的多队列设备设计,旨在提供高吞吐量的同时尽量兼顾延迟时间,同时其 CPU 开销也会比较高。
其内部有两个 I/O 请求队列,分别存放同步请求(读)和异步请求 (写),然后只进行一些简单的优化策略比如合并请求。正如我们在前文提到过的,前者的优先度要高于后者,因此 kyber 会优先调度读请求,但是它也会通过其他策略来规避写请求饿死的问题。Kyber 算法的一个核心逻辑就是严格限制发送到 HDQ 的 I/O 请求数量,因此 HDQ 的长度会很短,也就缩短了每个请求在队列中的停留时间,所以 I/O 请求 (尤其是高优先级的请求) 能被更快地推送到块设备上去执行。
由于 kyber 没有加入过多复杂的调度逻辑,实现相对简单,因此能较大程度地发挥出 SSD 的高吞吐能力,因此更加适合那些 I/O 密集型的应用,比如数据库。值得一提的另一个点是,kyber 算法虽然简单,但可以看做是对网络栈中的 bufferbloat (缓冲区肿胀) 设计的一种反向思维,也因此它理论上能够在 I/O 拥塞时尽量避免 I/O 请求在队列中长期滞留41。
None
最后也是最简单的一种调度器,基本原理和 SQ 架构下的 noop 算法一致:用来缓冲 I/O 请求的队列是 FIFO,而且不执行排序优化,只做合并优化。None 基本上就是把 noop 进行多队列的改造,为每一个 CPU core 或者 NUMA node 配备一个本地 FIFO 队列,避免跨核内存访问和锁竞争。本质上来说,None 就是一个简单的中转程序,把绝大部分的复杂度下沉到硬件设备中,将所有 I/O 工作都交给块设备区完成。
虽然 none 算法的极其简单,但是却非常适合用在 NVMe 协议的 SSD 上,因为这种 SSD 本身的随机 I/O 性能极高,与顺序 I/O 相比不遑多让,因此软件层的调度优化反而是越简单越好。而且未来随着NVMe SSD 的普及,None I/O Scheduler 这样策略简单的调度器可能反而会后来居上,成为内核中首选的调度器。
切换默认的 I/O scheduler
Linux 5.0 之前的版本默认是使用单队列 I/O 调度器 —— deadline、cfq 和 noop。内核 5.0 之后则默认使用多队列 I/O 调度器 —— mq-deadline、bfq、kyber 和 none。
从内核 5.3 开始,单队列 I/O 调度器就被全部移除了,之前的内核版本如果想要切换回单队列 I/O 调度的话,可以通过修改内核参数来实现。这里以 Ubuntu 系统为例,执行以下的命令查看当前是否开启了多队列 I/O 调度:
[root@localhost ~] cat /sys/module/scsi_mod/parameters/use_blk_mq
Y
[root@localhost ~] cat /sys/module/dm_mod/parameters/use_blk_mq
Y
输出 Y 则表示开启了 blk-mq 调度,如果是 N 则表示关闭,这里 scsi_mod 和 dm_mod 分别表示 SCSI 设备和 DM-Multipathing。如果要关闭 blk-mq,可以修改 /etc/default/grub 中的 GRUB_CMDLINE_LINUX_DEFAULT 字符串,加上 scsi_mod.use_blk_mq=N 和 dm_mod.use_blk_mq=N,然后执行 sudo update-grub 使配置生效 (要谨慎操作)。
如果是要切换多队列 I/O 调度器,通常是在某一块磁盘上操作的。这里以我的 Ubuntu 22.04 服务器来举例,内核版本是 5.15,配备了 NVMe 硬盘。先查看当前的默认 I/O 调度器:
cat /sys/block/vda/queue/scheduler
[mq-deadline] none
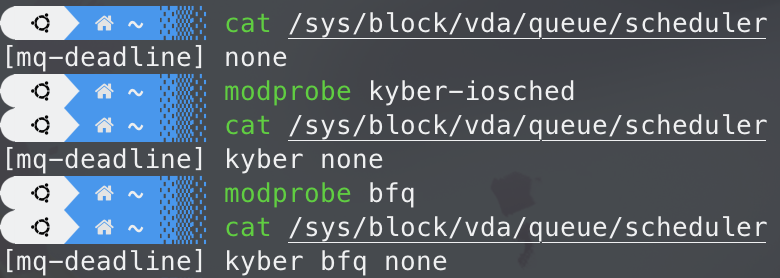
可以看到当前默认的多队列 I/O 调度器是 mq-deadline,另外还有一个 none。这里可能会有疑问:为什么没有前面介绍过的 bfq 和 kyber?是因为这两个 I/O 调度器是作为内核模块存在的,而且默认没有安装,需要手动安装,方法也很简单,使用 modprobe 命令就能安装:
sudo modprobe kyber-iosched
sudo modprobe bfq
cat /sys/block/vda/queue/scheduler
[mq-deadline] kyber bfq none
切换默认的 I/O 调度器也很简单,就是通过 echo 命令更新 /sys/block/vda/queue/scheduler 即可。比如要切换到 bfq 调度器,可以执行以下命令:
echo "bfq" | sudo tee /sys/block/vda/queue/scheduler
同理,如果是要切换到 kyber,则执行:
echo "kyber" | sudo tee /sys/block/vda/queue/scheduler
前面我就讲过,如果是 SSD 硬盘,特别是 NVMe 的硬盘,因为硬盘本身的硬件性能已经非常高了,相比之下软件层面 (内核) 的 I/O 调度就不是特别重要了,除了一些特定的使用场景,通常用一些像 none 和 mq-deadline 这一类比较简单的 I/O 调度算法就足够了,使用 kyber 也是个不错的选择但是可能要对其内核参数进行调优,否则可能也会折损性能,使用复杂的 bfq 算法可能反而会事倍功半。我读过一篇对 Linux 上的多队列 I/O 调度器进行实测的论文,作者们针对 Linux 的 blk-mq 调度器 —— mq-deadline、bfq、kyber 和 none 在 NVMe SSD 上的性能、开销和扩展性进行了全方位的测试。根据这篇论文的结论,在 NVMe SSD 上使用调优过的 kyber 调度器性能最高、扩展性最好,同时 CPU 开销也最低43,不过需要精心对参数进行调优,否则可能会有反效果。
块设备驱动层 (Block Device Driver)
块设备驱动层是 Linux 内核 Block 子系统管辖范围内的最低的一层,而块设备驱动程序则是 Block subsystem 中最底层的组件,驱动程序负责对接底层的硬件设备,Linux 中负责绝大部分的持久存储控制器的块设备驱动程序是 SCSI (Small Computer Systems Interface) 驱动程序,其所在的地方就是 SCSI layer,是 Linux 的一个子系统,负责使用 SCSI 协议和底层的存储设备通信,也就是为内核提供与 SCSI 存储设备的软件接口。
SCSI 协议是一组规定如何在计算机和外围设备之间传输数据的标准,广泛应用在硬盘、磁带和光盘等存储设备上。Linux 内核专门实现了一整个 SCSI 子系统来管理绝大多数的底层存储设备。
SCSI 驱动程序会将 I/O 调度层推送下来的 I/O 请求转换成 SCSI 命令 (也就是上一章的 "Tagged I/O & I/O Accounting" 一节中的 I/O command),然后提交到 I/O Submission HDQ 发送给块设备去处理。块设备按要求执行这些命令,完成之后便往 I/O Completion 队列写入命令已完成的状态并向主机 (请求方) 发出一个中断,中断处理程序收到以后就会调用预先设置好的中断回调函数释放一些占用的资源并把数据返回给上层。
块设备硬件层 (Block Devices)
这一层就是物理设备层,也就是我们熟悉的 HDD、SDD 等内嵌设备,还有其他的外部设备比如外接硬盘,U 盘等。
I/O 栈的执行过程
至此,整个 Linux I/O 栈就已经解析完成了。理论层面的分析结束了,一直在纸上谈兵,纸上得来终觉浅,绝知此事要躬行。现在让我们通过真正的内核代码来了解一下整个 Linux I/O 的执行栈过程。
内核代码剖析
这里我们先暂停一下 I/O 栈的分层解析。前面纸上谈兵这么久,现在让我们进入到内核看看 VFS 作为一个所谓的抽象层到底是如何和 Page Cache 配合完成 I/O 工作的。我们就以最经典、最广泛使用的文件系统 ext4 以及最常用的 read() 和 wirte() 系统调用作为例子来分析44:
ssize_t ksys_read(unsigned int fd, char __user *buf, size_t count)
{
...
ret = vfs_read(f.file, buf, count, ppos);
...
}
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
return ksys_read(fd, buf, count);
}
ssize_t ksys_write(unsigned int fd, const char __user *buf, size_t count)
{
...
ret = vfs_write(f.file, buf, count, ppos);
...
}
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
return ksys_write(fd, buf, count);
}
可以看到这两个系统调用实际上最终调用的底层实现是 vfs_read() 和 vfs_write() ,这种以 vfs_ 开头的内核函数就是 VFS 的 wrapper function,每一个操作文件系统的系统调用通常都会对应这么一个函数。这些函数里封装了文件系统操作的通用逻辑,确保不管当前挂载的是哪一种文件系统都能可以用44:
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{
...
if (file->f_op->read)
ret = file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
ret = new_sync_read(file, buf, count, pos);
else
ret = -EINVAL;
...
}
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{
...
if (file->f_op->write)
ret = file->f_op->write(file, buf, count, pos);
else if (file->f_op->write_iter)
ret = new_sync_write(file, buf, count, pos);
else
ret = -EINVAL;
...
}
此时我们在虚拟文件系统层 (VFS)。还记得前面说过的 VFS 数据结构中那些 xxx_operations 字段吗?这里的 file 对象的 f_op 指针字段指向的就是一系列的回调函数的实现,也就是函数操作表。现在我们看看 ext4 文件系统中是怎么定义和实现这些回调函数的45:
const struct file_operations ext4_file_operations = {
.llseek = ext4_llseek,
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
.iopoll = iocb_bio_iopoll,
.unlocked_ioctl = ext4_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext4_compat_ioctl,
#endif
.mmap = ext4_file_mmap,
.open = ext4_file_open,
.release = ext4_release_file,
.fsync = ext4_sync_file,
.get_unmapped_area = thp_get_unmapped_area,
.splice_read = ext4_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = ext4_fallocate,
.fop_flags = FOP_MMAP_SYNC | FOP_BUFFER_RASYNC |
FOP_DIO_PARALLEL_WRITE,
};
可以看到最新的内核 (v6.10) 代码中 ext4 并没有为 file_operations.read 和 file_operations.write 指定回调函数,但是注意到 file_operations.read_iter 和 file_operations.write_iter 则是指定了回调函数。回看一下 vfs_read() 和 vfs_write() 中的代码,它们会先检查 file->f_op->read 和 file->f_op->write,如果当前文件系统的接口实现了它们就调用,否则就再检查 file->f_op->read_iter 和 file->f_op->write_iter。这两组函数的区别是普通 I/O (单 buffer) 操作与 vectored I/O (多 buffers),后者可以实现前者,所以对于文件系统来说,read()/write() 和 read_iter()/write_iter() 这两组回调函数,选择其中之一实现就行了。目前内核中很多的 I/O 函数都从普通 I/O 迁移到 vectored I/O 了46,因此很多具体文件系统 (btrfs/ext4/fuse/xfs 等) 现在也都不实现 file_operations.read和 file_operations.write 而改为实现 file_operations.read_iter 和 file_operations.write_iter。
从前面的源码可以看出,vfs_read() 会调用 new_sync_read() 而 vfs_write() 会调用 new_sync_write()44:
static ssize_t new_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos)
{
struct kiocb kiocb;
struct iov_iter iter;
ssize_t ret;
// 结构体 kiocb 的作用是跟踪记录后面的 I/O 操作
// 的完成状态。这里使用内联函数 init_sync_kiocb()
// 对其进行初始化,指示 read_iter() 进行同步 I/O 操作。
// 这里会将文件的一些属性存在 kiocb 里,比如文件的
// O_DIRECT、O_NONBLOCK 等 flags
init_sync_kiocb(&kiocb, filp);
kiocb.ki_pos = (ppos ? *ppos : 0);
// 把用户空间的 buffer 绑定到内核的 iov_iter 上
iov_iter_ubuf(&iter, ITER_DEST, buf, len);
// 真正的底层实现在 read_iter() 里
ret = filp->f_op->read_iter(&kiocb, &iter);
BUG_ON(ret == -EIOCBQUEUED);
if (ppos)
*ppos = kiocb.ki_pos;
return ret;
}
static ssize_t new_sync_write(struct file *filp, const char __user *buf, size_t len, loff_t *ppos)
{
struct kiocb kiocb;
struct iov_iter iter;
ssize_t ret;
// 同上
init_sync_kiocb(&kiocb, filp);
kiocb.ki_pos = (ppos ? *ppos : 0);
iov_iter_ubuf(&iter, ITER_SOURCE, (void __user *)buf, len);
// 真正的底层实现在 write_iter() 里
ret = filp->f_op->write_iter(&kiocb, &iter);
BUG_ON(ret == -EIOCBQUEUED);
if (ret > 0 && ppos)
*ppos = kiocb.ki_pos;
return ret;
}
从函数名字能看出这两个函数都是同步函数,如果前面的内容有仔细阅读的话,这里可能会有疑问,读操作是同步的没问题,但是写操作应该是异步的,怎么这里也变成同步的了?并不是我前面的内容讲错了,而是内核源码里另有玄机,后面我会讲到。
接着就是调用 f_op->read_iter() 和 f_op->write_iter() 了,从前文可知这两个函数指针指向的是 ext4_file_read_iter() 和 ext4_file_write_iter()。每个具体文件系统在实现这两个函数的时候必须要使其支持同步 I/O 和异步 I/O,然后让调用方通过设置 struct kiocb 来控制函数执行时底层使用的 I/O 模式。就像上面的源码中,new_sync_read() 和 new_sync_write() 都使用了 init_sync_kiocb() 来设置 kiocb,说明这两个函数使用的 I/O 模式都是同步 I/O。
static ssize_t ext4_file_read_iter(struct kiocb *iocb, struct iov_iter *to)
{
...
return generic_file_read_iter(iocb, to);
}
ssize_t
generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
...
// 如果文件指定了 O_DIRECT,就执行 Direct I/O,
// 绕过 page cache 直接读写磁盘。
if (iocb->ki_flags & IOCB_DIRECT) {
...
}
return filemap_read(iocb, iter, retval);
}
ssize_t filemap_read(struct kiocb *iocb, struct iov_iter *iter,
ssize_t already_read)
{
...
do {
...
// 尝试从 page cache 读取数据,如果 cache missed,也就是
// 没有缓存这部分数据的话,则同步从磁盘加载这部分数据到 page cache
// 并异步预读后面的数据 (如果需要的话)
error = filemap_get_pages(iocb, iter->count, &fbatch, false);
if (error < 0)
break;
...
/*
* Once we start copying data, we don't want to be touching any
* cachelines that might be contended:
*/
writably_mapped = mapping_writably_mapped(mapping);
// 开始逐页拷贝数据
for (i = 0; i < folio_batch_count(&fbatch); i++) {
struct folio *folio = fbatch.folios[i];
size_t fsize = folio_size(folio);
size_t offset = iocb->ki_pos & (fsize - 1);
size_t bytes = min_t(loff_t, end_offset - iocb->ki_pos,
fsize - offset);
size_t copied;
...
/*
* If users can be writing to this folio using arbitrary
* virtual addresses, take care of potential aliasing
* before reading the folio on the kernel side.
*/
if (writably_mapped)
flush_dcache_folio(folio);
// 将数据拷贝到 iov_iter 绑定的用户空间的内存
copied = copy_folio_to_iter(folio, offset, bytes, iter);
already_read += copied;
iocb->ki_pos += copied;
last_pos = iocb->ki_pos;
if (copied < bytes) {
error = -EFAULT;
break;
}
}
put_folios:
for (i = 0; i < folio_batch_count(&fbatch); i++)
// 解除对 folio 的引用,也就是将引用计数减一,
// 方便后面回收 folio
folio_put(fbatch.folios[i]);
folio_batch_init(&fbatch);
} while (iov_iter_count(iter) && iocb->ki_pos < isize && !error);
file_accessed(filp);
ra->prev_pos = last_pos;
return already_read ? already_read : error;
}
static int filemap_get_pages(struct kiocb *iocb, size_t count,
struct folio_batch *fbatch, bool need_uptodate)
{
...
// 根据请求数据的偏移量计算其在 page cache 中的位置并尝试从 page cache 批量加载数据
filemap_get_read_batch(mapping, index, last_index - 1, fbatch);
// 数据不在 page cache 里
if (!folio_batch_count(fbatch)) {
if (iocb->ki_flags & IOCB_NOIO)
return -EAGAIN;
// Cache missed, 启动同步 readahead 从磁盘加载所需的数据到 page cache,
// 这个函数的核心逻辑是根据上一次读请求位置和本次读请求的数据大小计算
// 出接下来的同步预读应该从磁盘读取多少数据,然后提交 I/O 请求就返回了
page_cache_sync_readahead(mapping, ra, filp, index,
last_index - index);
// 再次尝试从 page cache 遍历加载请求的数据,如果上面提交的 I/O 请求执行得足够快的话,
// 那么这里应该就能从 page cache 里取到数据了
filemap_get_read_batch(mapping, index, last_index - 1, fbatch);
}
// 检查是否已经从 page cache 取到了数据,如果此时 fbatch 的数量还是 0,
// 则说明下层还没有完成 I/O 请求,很可能是因为 page cache 内存不足,
// 没有空间存放新的数据了,那么就分配新的 folio 页并阻塞进程等待 I/O 请求完成
if (!folio_batch_count(fbatch)) {
if (iocb->ki_flags & (IOCB_NOWAIT | IOCB_WAITQ))
return -EAGAIN;
// 分配新的 folio 页并通过 folio_wait_locked_killable() 阻塞等待 I/O 完成
err = filemap_create_folio(filp, mapping,
iocb->ki_pos >> PAGE_SHIFT, fbatch);
if (err == AOP_TRUNCATED_PAGE)
goto retry;
return err;
}
folio = fbatch->folios[folio_batch_count(fbatch) - 1];
// 测试 folio 中的 pages 的状态是否是 PG_readahead,
// 如果是则说明已经进入 page cache 可读数据的临界区,
// 需要进行异步预读,加载后面的数据到 page cache 中
// 以供下次读操作
if (folio_test_readahead(folio)) {
// 启动异步预读流程
err = filemap_readahead(iocb, filp, mapping, folio, last_index);
if (err)
goto err;
}
// 检查 folio 页的状态是不是 PG_uptodate,如果不是则表明
// 内存页的数据不是最新的,更新内存页的数据,并阻塞等待完成
if (!folio_test_uptodate(folio)) {
if ((iocb->ki_flags & IOCB_WAITQ) &&
folio_batch_count(fbatch) > 1)
iocb->ki_flags |= IOCB_NOWAIT;
// 更新 page 并通过 folio_wait_locked_killable() 阻塞等待 I/O 完成
err = filemap_update_page(iocb, mapping, count, folio,
need_uptodate);
if (err)
goto err;
}
...
}
static inline
void page_cache_sync_readahead(struct address_space *mapping,
struct file_ra_state *ra, struct file *file, pgoff_t index,
unsigned long req_count)
{
DEFINE_READAHEAD(ractl, file, ra, mapping, index);
page_cache_sync_ra(&ractl, req_count);
}
void page_cache_sync_ra(struct readahead_control *ractl,
unsigned long req_count)
{
bool do_forced_ra = ractl->file && (ractl->file->f_mode & FMODE_RANDOM);
/*
* Even if readahead is disabled, issue this request as readahead
* as we'll need it to satisfy the requested range. The forced
* readahead will do the right thing and limit the read to just the
* requested range, which we'll set to 1 page for this case.
*/
// blk_cgroup_congested() 检查 I/O 调度层的队列当前是否拥塞,
// 如果是则说明当前的 I/O 很密集,系统很繁忙,但这是同步 I/O 请求,
// 用户进程正在等待系统调用 `read()` 返回数据,无法像异步预读那样
// 推迟,所以只能减少预读数据的大小,只读一个 page,优先保证返回数据
// 给用户进程。
if (!ractl->ra->ra_pages || blk_cgroup_congested()) {
if (!ractl->file)
return;
req_count = 1;
do_forced_ra = true;
}
/* be dumb */
if (do_forced_ra) {
force_page_cache_ra(ractl, req_count);
return;
}
ondemand_readahead(ractl, NULL, req_count);
}
static int filemap_readahead(struct kiocb *iocb, struct file *file,
struct address_space *mapping, struct folio *folio,
pgoff_t last_index)
{
DEFINE_READAHEAD(ractl, file, &file->f_ra, mapping, folio->index);
if (iocb->ki_flags & IOCB_NOIO)
return -EAGAIN;
page_cache_async_ra(&ractl, folio, last_index - folio->index);
return 0;
}
void page_cache_async_ra(struct readahead_control *ractl,
struct folio *folio, unsigned long req_count)
{
...
// blk_cgroup_congested() 检查 I/O 调度层的队列当前是否拥塞,
// 如果是则说明当前的 I/O 很密集,系统很繁忙,那么就推迟这一次的
// 异步预读流程。
if (blk_cgroup_congested())
return;
ondemand_readahead(ractl, folio, req_count);
}
static int filemap_create_folio(struct file *file,
struct address_space *mapping, pgoff_t index,
struct folio_batch *fbatch)
{
struct folio *folio;
int error;
...
// 从块设备读取数据
error = filemap_read_folio(file, mapping->a_ops->read_folio, folio);
...
return error;
}
static int filemap_read_folio(struct file *file, filler_t filler,
struct folio *folio)
{
...
/* Start the actual read. The read will unlock the page. */
if (unlikely(workingset))
psi_memstall_enter(&pflags);
// 这里的 filter 回调函数就是 address_space_operations.read_folio(),
// 执行真正的读操作,从底层块设备读取数据上来
error = filler(file, folio);
if (unlikely(workingset))
psi_memstall_leave(&pflags);
if (error)
return error;
// 阻塞等待相关的页面被解锁之后才能返回
error = folio_wait_locked_killable(folio);
...
}
此时我们经由页高速缓存层 (Page Cache) 进入了映射层 (Mapping Layer)。ext4_file_read_iter() 调用了 generic_file_read_iter() 来完成功能,后者是一个通用函数,这是内核提供给 VFS 使用的,所有文件系统的核心功能都是基于这些通用函数实现的,generic_file_read_iter() 会先处理 Direct I/O 的场景 (使用 Direct I/O 需要用户程序自己处理 block alignment (块大小对齐),如果是 Buffered I/O,则 page cache 层会自动帮我们处理),接着调用 filemap_read() 函数,调用 filemap_get_pages(),在其中计算数据的位置和偏移量并调用 filemap_get_read_batch() 先尝试从 page cache 中读取数据,如果数据不在其中则启动预读流程。
预读过程中又分为同步预读和异步预读,同步预读流程会调用 page_cache_sync_readahead(),往下层提交 I/O 请求,从磁盘加载本次系统调用请求的数据,然后检查最后一个 folio 中的 pages 的状态是否为 PG_readahead,如果是的话就调用 filemap_readahead() 进行异步预读。之所以要通过检查做是因为 Linux 会把预读的内存页区域做如下划分47 48:
|<----- async_size ---------|
|------------------- size -------------------->|
|==================#===========================|
^start ^page marked with PG_readahead
/**
* struct file_ra_state - Track a file's readahead state.
* @start: Where the most recent readahead started.
* @size: Number of pages read in the most recent readahead.
* @async_size: Numer of pages that were/are not needed immediately
* and so were/are genuinely "ahead". Start next readahead when
* the first of these pages is accessed.
* @ra_pages: Maximum size of a readahead request, copied from the bdi.
* @mmap_miss: How many mmap accesses missed in the page cache.
* @prev_pos: The last byte in the most recent read request.
*
* When this structure is passed to ->readahead(), the "most recent"
* readahead means the current readahead.
*/
struct file_ra_state {
pgoff_t start;
unsigned int size;
unsigned int async_size;
unsigned int ra_pages;
unsigned int mmap_miss;
loff_t prev_pos;
};
内核使用 file_ra_state 结构体来维护预读的相关信息,size 是内核设置的异步 readahead 缓冲区大小,也就是这一次同步预读的窗口,async_size 表示这一次读请求用不到的预读数据长度,也就是真正的预读窗口大小,prev_pos 是最近一次读请求读取的最后一个字节的位置,可以理解成是上一次读操作的游标。进入 page_cache_sync_readahead()->page_cache_sync_ra()->ondemand_readahead() 之后,会根据 prev_pos 计算出 size 和 async_size 的值,然后往下层提交 I/O 请求启动预读流程,这里需要注意一下,这个函数名里的 sync 可能会造成误解,让人以为这个函数会同步阻塞直到数据从磁盘读上来了,其实这个函数提交完 I/O 请求就返回了,不会阻塞等待 I/O 完成,这里的 sync 和"同步预读"中的"同步"只是表示提交的 I/O 请求是同步的。
page_cache_sync_readahead() 返回之后,后面的代码会再尝试到 page cache 去遍历查找请求的数据,如果还是没找到则断定是 page cache 空间不足无法完成 I/O 请求,于是就会调用 filemap_create_folio() 分配 folio 页然后调用 filemap_read_folio()->folio_wait_locked_killable() 阻塞等待 I/O 完成再返回,这里实际是等待直到相关的内存页在读取完成之后被解锁才能返回,killable 表示这个过程是可以被中断信号打断的。这里设定 index 为本次读操作游标,如果本次读请求访问到了有 PG_readahead 标记的页 (也就是 index > size - async_size),那么就认为本次是顺序访问,窗口 size 就在当前的基础上成倍扩大 (2 倍或者 4 倍),接着调用 filemap_readahead()->page_cache_async_ra()->ondemand_readahead() 启动异步预读流程,填充这些 size 扩大之后多出来的内存页并把最新的异步预读加载进来的第一个页标记为 PG_readahead,如此循环往复。如果是随机访问,则关闭预读,因为预读只对顺序访问有意义。
另外一点指的一提的是 page_cache_sync_ra() 和 page_cache_async_ra() 都会先检查当前 I/O 调度层的队列是否拥塞,如果确实拥塞的话,则表明当前的 I/O 很密集,也就是说系统现在过于繁忙,那么异步预读流程就取消,毕竟预读本来也只是针对顺序 I/O 的一个优化策略而已,如果现在系统 I/O 已经过载了,那么就不要再通过预读操作雪上加霜了。而同步预读则没有办法取消,因为此时用户进程还阻塞在 read() 系统调用上等待内核返回数据,所以只能是减少这一次读操作的数据大小,只读一个 page,优先确保返回数据给用户进程。
同步预读和异步预读的逻辑最终会利用前面介绍过的 address_space_operations 的 read_folio 和 readahead() 函数提交 I/O 请求,启动预读流程。这两个函数同样是由具体的文件系统实现的,ext4 文件系统的具体实现是 ext4_readahead 和 ext4_read_folio 这两个函数,ext4 的完整 address_space_operations 如下49:
static const struct address_space_operations ext4_aops = {
.read_folio = ext4_read_folio,
.readahead = ext4_readahead,
.writepages = ext4_writepages,
.write_begin = ext4_write_begin,
.write_end = ext4_write_end,
.dirty_folio = ext4_dirty_folio,
.bmap = ext4_bmap,
.invalidate_folio = ext4_invalidate_folio,
.release_folio = ext4_release_folio,
.migrate_folio = buffer_migrate_folio,
.is_partially_uptodate = block_is_partially_uptodate,
.error_remove_folio = generic_error_remove_folio,
.swap_activate = ext4_iomap_swap_activate,
};
static int ext4_read_folio(struct file *file, struct folio *folio)
{
int ret = -EAGAIN;
struct inode *inode = folio->mapping->host;
trace_ext4_read_folio(inode, folio);
if (ext4_has_inline_data(inode))
ret = ext4_readpage_inline(inode, folio);
if (ret == -EAGAIN)
// 提交 I/O 请求到 I/O 调度层
return ext4_mpage_readpages(inode, NULL, folio);
return ret;
}
static void ext4_readahead(struct readahead_control *rac)
{
struct inode *inode = rac->mapping->host;
/* If the file has inline data, no need to do readahead. */
if (ext4_has_inline_data(inode))
return;
// 提交 I/O 请求到 I/O 调度层
ext4_mpage_readpages(inode, rac, NULL);
}
int ext4_mpage_readpages(struct inode *inode,
struct readahead_control *rac, struct folio *folio)
{
struct bio *bio = NULL;
...
if (bio)
submit_bio(bio);
return 0;
}
/**
* submit_bio - submit a bio to the block device layer for I/O
* @bio: The &struct bio which describes the I/O
* ...
*/
void submit_bio(struct bio *bio)
{
if (bio_op(bio) == REQ_OP_READ) {
task_io_account_read(bio->bi_iter.bi_size);
count_vm_events(PGPGIN, bio_sectors(bio));
} else if (bio_op(bio) == REQ_OP_WRITE) {
count_vm_events(PGPGOUT, bio_sectors(bio));
}
bio_set_ioprio(bio);
submit_bio_noacct(bio);
}
从源码可以看出,read_folio 和 readahead() 最终都会调用 ext4_mpage_readpages(),在其中分配和打包好 bio,传入 submit_bio() 提交一个同步或者异步的 readahead I/O 请求到下层,我们便进入了通用块层 (Generic Block Layer)。接下来会依次进入 I/O 调度层 (I/O Scheduling Layer)、块设备驱动层 (Block Device Driver Layer),最后到块设备层 (Block Device Layer),从磁盘加载后面的相邻数据到 page cache,调用 copy_folio_to_iter() 把数据拷贝到用户程序指定用户空间地址。最后,沿着函数栈层层回溯,最终从内核态返回到用户态。(对应的计算机硬件层面的 I/O 过程在下一章节介绍)
讲解到这里可以算是描绘了一个大概的轮廓,我个人认为对绝大部分的读者来说应该足够了,剩下的那些 I/O 系统层,比如 I/O 调度层,前面的剖析已经比较详细了,如果有读者还想进一步深入源码细节,我想可以考虑以后补充这部分的内容,至于块设备驱动层和块设备层,属于软硬件边界的部分,可能会涉及到比较多的硬件相关的细节,我感觉可能对大部分程序员读者来说不是很必要?
// TODO: 补充 I/O 调度层、块设备驱动层和块设备层的源码实现细节。
static ssize_t
ext4_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
...
if (iocb->ki_flags & IOCB_DIRECT)
return ext4_dio_write_iter(iocb, from);
else
return ext4_buffered_write_iter(iocb, from);
}
static ssize_t ext4_buffered_write_iter(struct kiocb *iocb,
struct iov_iter *from)
{
ssize_t ret;
struct inode *inode = file_inode(iocb->ki_filp);
if (iocb->ki_flags & IOCB_NOWAIT)
return -EOPNOTSUPP;
inode_lock(inode);
ret = ext4_write_checks(iocb, from);
if (ret <= 0)
goto out;
// 执行写操作的核心逻辑
ret = generic_perform_write(iocb, from);
out:
inode_unlock(inode);
if (unlikely(ret <= 0))
return ret;
return generic_write_sync(iocb, ret);
}
ssize_t generic_perform_write(struct kiocb *iocb, struct iov_iter *i)
{
struct file *file = iocb->ki_filp;
loff_t pos = iocb->ki_pos;
// 从文件对象中取出 address_space 和 address_space_operations
struct address_space *mapping = file->f_mapping;
const struct address_space_operations *a_ops = mapping->a_ops;
long status = 0;
ssize_t written = 0;
do {
struct page *page;
unsigned long offset; /* Offset into pagecache page */
unsigned long bytes; /* Bytes to write to page */
size_t copied; /* Bytes copied from user */
void *fsdata = NULL;
offset = (pos & (PAGE_SIZE - 1));
bytes = min_t(unsigned long, PAGE_SIZE - offset,
iov_iter_count(i));
...
// 通知文件系统准备好往给定的文件中写入数据,
// 同时告知要往文件的那个位置写入多少数据,
// 让文件系统提前做一些准备工作,比如分配内存之类的
status = a_ops->write_begin(file, mapping, pos, bytes,
&page, &fsdata);
if (unlikely(status < 0))
break;
if (mapping_writably_mapped(mapping))
flush_dcache_page(page);
// 从用户空间的指定地址拷贝数据到内核中的 page cache
copied = copy_page_from_iter_atomic(page, offset, bytes, i);
flush_dcache_page(page);
// 通知文件系统,数据已经拷贝完成
status = a_ops->write_end(file, mapping, pos, bytes, copied,
page, fsdata);
if (unlikely(status != copied)) {
iov_iter_revert(i, copied - max(status, 0L));
if (unlikely(status < 0))
break;
}
...
balance_dirty_pages_ratelimited(mapping);
} while (iov_iter_count(i));
if (!written)
return status;
iocb->ki_pos += written;
return written;
}
static inline ssize_t generic_write_sync(struct kiocb *iocb, ssize_t count)
{
if (iocb_is_dsync(iocb)) {
// 如果这个写操作被指定要为同步写的话就执行
// fsync 将数据同步到磁盘再返回
int ret = vfs_fsync_range(iocb->ki_filp,
iocb->ki_pos - count, iocb->ki_pos - 1,
(iocb->ki_flags & IOCB_SYNC) ? 0 : 1);
if (ret)
return ret;
}
return count;
}
同样的,在 ext4_file_write_iter() 判断是 Direct I/O 还是 Buffered I/O 分条件处理,我们这里还是讨论 Buffered I/O,于是进入 ext4_buffered_write_iter(),先取得 address_space 和 address_space_operations,然后先调用 address_operations->write_begin() (ext4 的具体实现是 ext4_write_begin()),通知文件系统做一些准备工作,比如为该页分配内存,然后就调用 copy_page_from_iter_atomic() 把给定的用户空间地址上的数据拷贝进内核空间,接着就 address_operations->write_end() (ext4 的具体实现是 ext4_write_end()) 完成一些收尾的工作,通过 address_operations->dirty_folio() (ext4 对应实现是 dirty_folio()) 把对应的页面标记为 PG_dirty。到这里写操作就完成了,写操作的源码结构相对直观一点,流程也更简短一些,因为写操作是异步的,只需要把数据写入 page cache 然后将相关的页面标记成脏页就行了。内核的自动 writeback 机制会定期将这些脏页落盘。
注意到这里有一个有趣的函数调用 —— flush_dcache_page(),如果之前在分析读操作那边的源码时有仔细看的话,应该能发现那边也有一个类似的函数 —— flush_dcache_folio(),后者和前者是一样的功能,只不过它针对的是 folio 复合页。那么这个函数到底是在做什么呢?从源码结构上看,这两个函数都是在内核空间和用户空间之间拷贝数据的前后附近调用的,想必应该是一个相当重要的函数。
想要了解这两个函数的作用,首先我们需要先了解两个概念:CPU 高速缓存 (CPU Cache) 和虚拟别名 (Virtual Aliasing)。
CPU 高速缓存与虚拟内存
CPU 高速缓存的通用架构如下所示 (接下来的内容会借用一下《深入理解计算机系统》50一书中的一些图来进行分析):
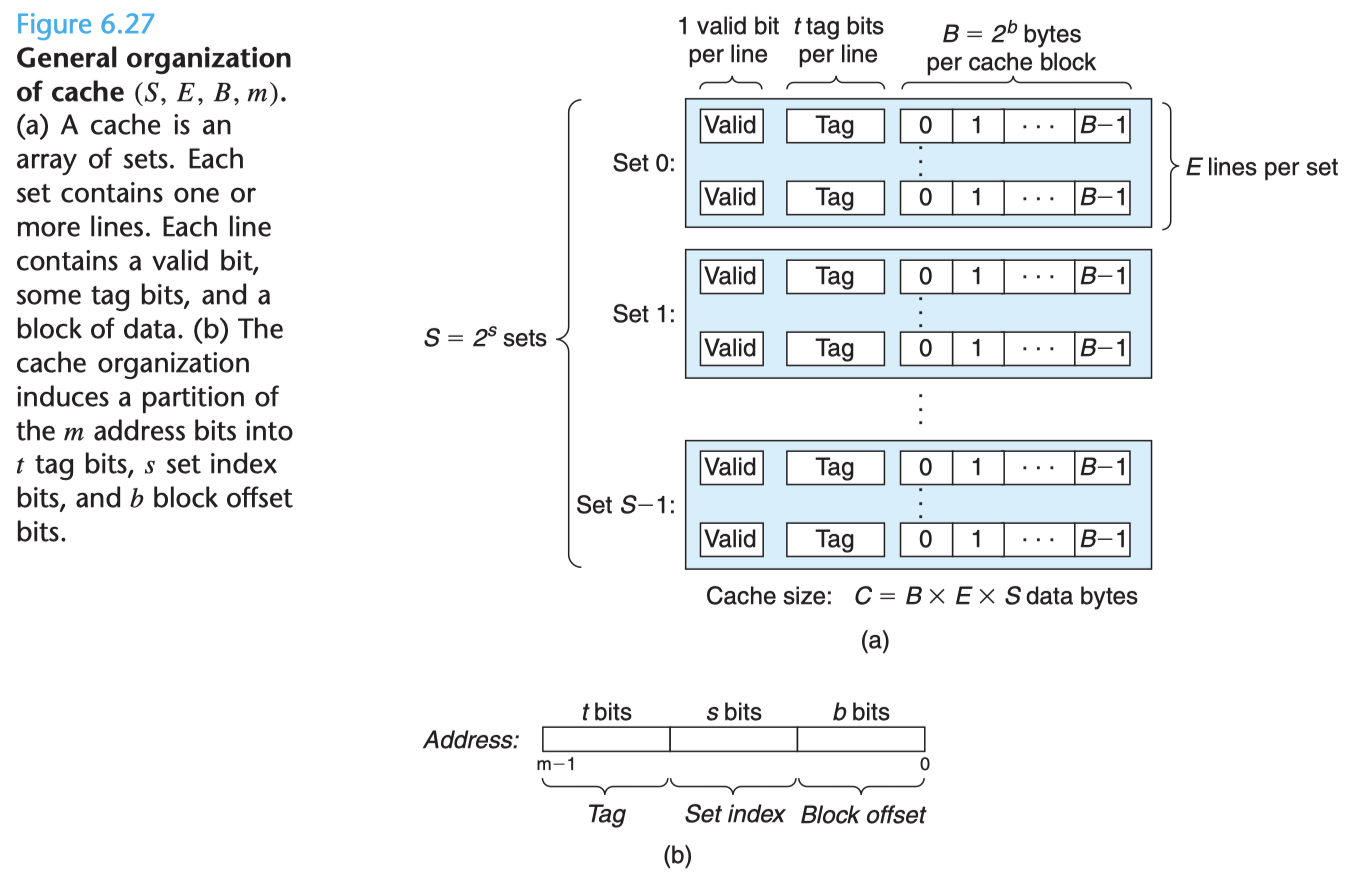
CPU 高速缓存的地址有 m 位,形成 M = 2m 个不同的地址。如上图 6.27 所示,CPU 高速缓存由 S = 2s 个高速缓存组 (cache set) 组成,每个组包含 E 个高速缓存行 (cache line)。每个行是由一个 B = 2b 字节的数据块组成的 (block),一个有效位 (valid bit) 表示该行是否包含有效的缓存数据,还有 t = m - (b+s) 个标记位 (tag bit),它们是当前块的内存地址位的一个子集,它们唯一地标识存储在这个缓存行中的块。通常 CPU 高速缓存的结构可以用一个元组 (S, E, B, m) 来表示,其容量 C 指的是所有块的大小之和。标记位和有效位不计入在内。所以,存在公式 C = S × E × B。
基于通用架构,又有三种具体的实现:
- 直接映射高速缓存
- 组相联高速缓存
- 全相联高速缓存
本文这里只用第一种『直接映射高速缓存』来进行分析,因为这种架构是最简单的,它的每个组只有一行 (E = 1),便于入门学习。
首先是 CPU 高速缓存,它是多层存储架构:分为 L1、L2 和 L3 三层。L1 又分为 Instruction Cache (指令缓存,用来加速 CPU 指令获取,又称为 I-cache,icache 等) 和 Data Cache (数据缓存,用来加速数据获取和存储,又称为 D-cache,dcache 等)。指令缓存通常只在 L1 上,数据缓存则是遍布 L1、L2 和 L3。这三种级别的 CPU 高速缓存的速度和容量都是依次递减:L1 直接嵌入在 CPU 上,离 CPU 最近,CPU 访问 L1 通常只需要两三个时钟周期,所以其速度最快,最高可达到主内存的百倍,容量通常是 64KB,但也有更大的,比如我手头上的 Mac Studio (M1 Max),其 L1 cache 有 192KB;L2 通常也是 CPU 独占的 (也有一些架构是同一个 cluster 共享,比如 mac M1) 但离 CPU 更远一点,CPU 访问 L2 一般要 10+ 个时钟周期,其速度大概能达到主存的 25 倍左右,容量通常是在 256 ~ 512KB 之间,有一些 CPU 能达到几 MB;L3 的速度通常只有主存的四五倍,容量最大,大概 4 ~ 64MB。 CPU 高速缓存由一行行的连续地址的缓存行 (cache line) 组成,缓存行大小通常从 16B 到 256B 不等。

其次是虚拟别名 (virtual aliasing),文章开头我写过虚拟地址由虚拟页号和偏移量构成,还可以进一步细化成偏移 (offset,上图 9.15 中的 VPO)、索引 (index,上图 9.15 的 TLB index) 和标签 (tag,上图 9.15 的 TLB tag)。
CPU 缓存行中除了数据之外也会有对应的 index (上图 6.31 的 Set index) 和 tag (上图 6.31 的 Tag),CPU 通过 index 定位到虚拟地址所对应的缓存行 (比如通过硬件哈希取模,如下图 6.30 所示),然后检查有效位是否设置,如果是则再通过 tag 和缓存行进行比较,如果相等则说明缓存命中,最后通过 offset 确定数据在缓存行中的偏移量,取回数据,至此就完成了一个缓存查询和读取。也就说 index 是缓存行的位置索引,tag 通常是内存地址剪除掉 offset 和 index 的剩余部分,其作用是绑定缓存行和内存地址,确保该缓存行真的属于当前这个地址而非其他地址,offset 是虚拟地址指向的数据在缓存行中的偏移量。虚拟别名是虚拟内存的一个特性,但也可以说是一种问题,其含义是多个虚拟地址映射到同一个物理地址。CPU 高速缓存需要处理虚拟别名,否则会导致同一个 CPU 缓存了同一块内存在不同的缓存行进行读写,从而可能会导致缓存不一致的问题。这里的 offset 要注意和上一段的同名词区分开来,上一段的的 offset 是 VPO,是虚拟地址的页偏移量,这一段中的 offset 是缓存行的偏移量,前者通常要比后者大得多。
除了虚拟别名其实还有另一个问题:歧义 (homonyms)。这个词本义是"同音(形)异义词",用来表示同一个虚拟地址映射到了多个不同的物理地址。比如不同进程上的同一个虚拟地址映射到了不同的物理地址,因为 CPU 高速缓存控制器是根据 index 和 tag 来判断到底是缓存命中 (cache hit) 还是缓存缺失 (cache miss),所以如果虚拟地址相同则根本无法做区分。与此相对,虚拟别名 (virtual aliasing) 页也被称为 synonym (同义词),因为有多个虚拟地址指向了同一个物理地址。
据此,CPU 高速缓存和虚拟内存的协作模式可以归纳为以下四种。
VIVT
全称是 Virtually indexed, virtually tagged,这是最直接的一种架构,CPU 缓存行中的 index 和 tag 都直接取自虚拟地址,这种架构的查询性能最高,因为 CPU 直接根据 index 和 tag 就能判断该虚拟地址对应的数据是否在 CPU 缓存中,再通过 offset 就能定位到缓存行。然而,如果多进程访问同一个物理地址,因为每一个用户进程都有自己的虚拟地址空间和页表,又因为 index 决定了缓存行所在的位置,如果两个进程中的虚拟地址的 index 不一样,就会导致同一个物理地址上的数据被加载到同一个 CPU 上的不同缓存行中。这两个虚拟地址虽然不同,但是映射的物理地址是一样的,即是虚拟别名问题。
从内核的角度来看,甚至可能都不需要多进程,因为内核在处理用户进程的 I/O 请求的时候就需要把对应的物理地址映射到自己的虚拟地址上,这时候就算只有一个用户进程也会和内核一起触发虚拟别名。前面说了虚拟别名是一个特性也是一个问题,因为虚拟别名又分为合法虚拟别名和非法虚拟别名,合法虚拟别名是允许的,不会有什么问题,非法虚拟别名则会导致一些问题,那么到底会引起什么问题呢?
![]()
下面是一些符号解释:
| 符号 | 描述 |
|---|---|
| N = 2n | 虚拟地址空间的大小 |
| M = 2m | 物理地址空间的大小 |
| P = 2p | 页大小 (字节) |
| VPO | 虚拟页面偏移量 (字节) |
| VPN | 虚拟页号 |
| PPO | 物理页面偏移量 (字节) |
| PPN | 物理页号 |
我这里以 32 (n = 32) 位系统为例,系统的物理页大小 P = 4KB = 212,所以 p = 12,虚拟内存管理的页大小和物理页一样。此时虚拟地址的长度就是 32 bit,VPO 的范围是 [11:0] (低地址 0 到 11 bit),VPN 的范围是 [31:12],因为虚拟内存页的大小和物理内存页相同,因此 PPO 也是 [11:0],也就是说虚拟地址和物理地址在 [11:0] 的这部分是完全一致的。最后假设 CPU 的缓存行大小是 64B = 26,所以缓存行的 offset 是 [5:0]。
当 CPU 的 dcache 小于等于 P (4KB) 的时候,此时就是虚拟别名就是合法的。因为此时 dcache 的整个寻址范围小于 4KB,而缓存行大小又是 64B,也就是说缓存行数量肯定要小于等于 4096/64 = 64 = 26 个,所以 index 最多只需要用到虚拟地址中的 6 个 bit,也就是 [11:6],又因为虚拟地址和物理这一部分的地址是一样的 (VPO = PPO = [11:0]),也就是说 index 是取自物理地址,而物理地址是唯一的,那么被调度到同一个 CPU 上运行的不同用户进程即便是用不同的虚拟地址去映射同一个物理地址,最终得到的 index 肯定是一样的,当系统加载物理地址上的数据到 CPU 缓存中的时候,CPU 高速缓存控制器会通过 index 进行硬件哈希计算出数据应该存储在哪一个缓存行,结果当然是两个进程得到的结果是一样的,也就是都会存储到同一个缓存行,那么就不会出现一个 CPU 上的不同缓存行存储了同一个物理地址上的数据,也就不会有缓存数据不一致的问题。因此,这种情况下虚拟别名就是合法的。
虚拟别名不合法的时候就是当 dcache 大于 P (4KB) 的时候:假设 dcache 是 8KB,此时 [11:6] 就不够 index 用了,因为现在的缓存行数量是 8096/64 = 128 = 27,所以 index 现在必须要占用 7 个 bit,也就是 [12:6],此时显然已经超过了虚拟地址和物理地址重合的范围 [11:0] 了,这也就意味着虚拟地址可以映射到同一个物理地址。也就是说这时候如果再发生同一个 CPU 上多个进程访问同一个物理地址并把数据存入 dcache 的情况,此时多个进程中映射到同一个物理地址的不同虚拟地址的 index 有可能是不一样的,那么就会导致 CPU 高速缓存控制器把同一个物理地址上的数据存储到不同的缓存行中,进而可能引发 CPU 缓存不一致的问题。
用一个例子来加深一下理解,假设有一个用户进程访问它的虚拟地址 0x1000,这个虚拟地址在页表中被映射到物理地址 0x8000,然后触发了一个 cache miss,系统就会访问内存的物理地址,然后把该地址上的数据加载到 dcache,之后发生了 CPU 上下文切换,这个进程被调度走了,另一个进程上来了,它访问虚拟地址 0x1800,这个虚拟地址也在页表中被映射到物理地址 0x8000,此时分两种情况讨论:
- dcache <= 4KB,假设就是 4KB,缓存行大小是 64B,一共有 4096/64 = 64 个缓存行,此时第一个进程进来 CPU,访问 0x1000,虚拟地址被发送给 CPU 高速缓存控制器,该虚拟地址的
index地址范围是 [11:6],也就是二进制值 000000,通过哈希取模计算缓存行索引:0 % 64 = 0,定位到第 0x0 个缓存行,发现该行还没有缓存数据 —— cache miss,将虚拟地址通过总线发给 MMU 转化成物理地址 0x8000,然后按照物理地址到内存去加载数据存入第 0x0 个缓存行;CPU 切换上下文,第二个进程上来,访问 0x2000,走一样的流程:对虚拟地址的index000000 哈希取模:0 % 64 = 0,定位到第 0x0 个缓存行,发现这个缓存行有数据于是把数据取出来,但是对比tag发现不一致 —— cache miss,将虚拟地址通过总线发给 MMU 转化成物理地址 0x8000,然后按照物理地址到内存去加载数据存入第 0x0 个缓存行,因为是同一个缓存行,所以不会导致缓存不一致,这是合法虚拟别名。 - dcache > 4KB,假设是 8KB,缓存行大小是 64B,一共有 8192/64 = 128 个缓存行,此时第一个进程进来 CPU,访问 0x1000,虚拟地址被发送给 CPU 高速缓存控制器,该虚拟地址的
index地址范围是 [12:6],也就是二进制值 1000000,通过哈希取模计算缓存行索引:64 % 128 = 64,定位到第 0x40 个缓存行,发现该行还没有缓存数据 —— cache miss,将虚拟地址通过总线发给 MMU 转化成物理地址 0x8000,然后按照物理地址到内存去加载数据存入第 0x40 个缓存行;CPU 切换上下文,第二个进程上来,访问 0x2000,走一样的流程:对虚拟地址的index0000000 哈希取模:0 % 64 = 0,定位到第 0x00 个缓存行,发现该行还没有缓存数据 —— cache miss,将虚拟地址通过总线发给 MMU 转化成物理地址 0x8000,然后按照物理地址到内存去加载数据存入第 0x00 个缓存行,此时这个 CPU 上有两个缓存行存储了同一个物理地址上的数据,这是非法虚拟别名。
第二种情况的非法虚拟别名到底可能会导致什么问题呢?假设在两个进程切换之间,物理地址 0x8000 上的数据发生了更新,那么当第二个进程把数据加载进第 0x00 个缓存行之后,之前第一个进程存放在第 0x40 个缓存行就相当于是过期数据了 (抑或是第二个进程自己就把那个物理地址上的数据更新了),这时候如果 CPU 再次切换上下文把第一个进程调度回来,这个进程继续访问它的虚拟地址 0x1000,这时候就会取到过期数据。那么如何解决非法虚拟别名的问题呢?从第一个场景应该可以看出一些头绪:缓存行刷新,也就是旧数据被新数据覆盖了,而且在那个条件下是完全自动的,不需要程序去操心。那么内核要解决这个问题,也可以通过在进程切换时手动将 dcache 给刷掉,这也就是前面内核源码中的 flush_dcache_folio()/flush_dcache_page() 的作用:flush cache (冲刷高速缓存),通常分为两步,先把 CPU cache 中的"脏"缓存行 writeback 回写到主内存 (和 page cache 的脏页和 writeback 是一样的原理) ,然后 invalidate cache (使高速缓存失效),后续有需要再重新从内存加载到 CPU cache。
既然虚拟别名可能会带来这么多问题,那为什么不一开始直接就通过某种方式禁止虚拟别名呢?为什么还要允许它的存在并分成合法和非法的虚拟别名呢?我们现在就来讲讲合法虚拟别名有什么用。我们写程序的时候可以发现很多时候进行 I/O 处理的场景是读多写少,甚至是完全不需要写操作,这对于内核来说也是一样的,内核中有一些场景其实也是读多写少,比如复制一段内存数据,但是只会执行读操作而不会去修改这一段数据,这时候虚拟别名的优势就体现出来了,如果只是复制数据用来读的话,那么完全不需要真的去把数据复制过来,而只需要用虚拟别名这个特性,再借助 CPU 高速缓存,实现一个指向同一个物理地址的虚拟地址别名就行了,和别人共享这一段内存数据。虚拟别名的一个典型的应用就是写时复制 (CoW, Copy-on-Write),Linux 的 fork() 系统调用创建子进程的时候几乎得把父进程的虚拟地址空间的内容都复制过来 (数据段和堆栈;代码段会共享),不仅耗时又浪费内存,子进程之后再调用 exec() 来重载整个进程的话,那么之前的数据复制就完全是在做无用功,这个时候就会使用 CoW 技术,子进程不再复制数据其父进程的数据,而只是复制它的页表,那么 fork() 之后父子进程的虚拟地址空间就会指向相同的物理地址,因为进程彼此的虚拟地址空间和页表是私有的,因此这种操作是允许的,于是子进程的所有读操作访问的数据在内存中就只有一份,父子进程共享,只有当子进程进行写操作的时候才会分配新的内存页。
虚拟内存的地址翻译是通过全局 (per CPU) 的 MMU 实现的,它内部有一个页表以及 TLB,而 Linux 还为每一个进程维护了一个页表 (page table),虚拟地址翻译通常不会用到那些进程独立的页表,这些页表的作用更多是在于辅助 MMU,CPU 进行上下文切换进程的时候,内核会把进程的页表发送到 CPU 寄存器最后到 MMU,不过通常不是全量替换而是增量更新,也就说只会替换 MMU 中关于这个进程跟上次对比的页表项 (PTE, page table entry) 更新。在 VIVT 模式下有可能会引发虚拟歧义的问题:A 进程占用 CPU,使用虚拟地址 0x1000 映射到物理地址 0x8000,MMU 页表更新这一条记录,然后上下文切换,B 进程上来了,其页表中的虚拟地址 0x1000 也映射了物理地址 0xF000,此时 MMU 页表会更新这一条记录,又发生上下文切换,A 进程又回来了,此时继续访问 0x1000,导致访问到错误的物理地址。这个问题的解决一样是通过冲刷 CPU 高速缓存和 TLB,Linux 提供了另一组接口用来处理这种问题51。
早期的计算机基本都是采用 VIVT 模式,但是由于这种模式存在前文所述的虚拟别名和歧义问题,虽然通过高速缓存刷新能解决,但是频繁的执行高速缓存刷新会导致高速缓存的价值无法发挥出来,降低系统性能,现在渐渐被弃用了。
PIPT
全称是 Physically indexed, physically tagged,CPU 缓存行中的 index 和 tag 都取自真正的物理地址。这种方式实现简单,而且可以彻底规避掉虚拟别名和虚拟歧义的问题。这两个问题的本质是地址不唯一,前者是虚拟地址不唯一,后者是物理地址不唯一,现在 index 和 tag 都取自唯一的物理地址,那么也就能解决这两个问题了:虚拟别名这个问题的根源就在于 index 取自虚拟地址,而虚拟地址不是(全局)唯一的,导致不同 index 指向的不同缓存行但是都缓存了相同物理地址上的数据,结果就是可能会访问到过期数据。而虚拟歧义的根源在 tag,因为 tag 原本是用来绑定虚拟地址和缓存行的唯一标识,正常情况下虚拟地址只映射一个物理地址,但是因为上文所述的场景会导致一个虚拟地址可能映射到多个物理地址,所以 tag 就失去作用了;现在 tag 也取自物理地址,那么就保证了其唯一性,不会再有歧义。
现在 index 和 tag 都直接取自物理地址,物理地址是全局唯一的,所以 index 也是全局唯一的,也就是说其指向的缓存行也是全局唯一的了,因此肯定不会再出现非法虚拟别名了。
这种模式可以完全解决非法虚拟别名的问题,而且完全不需要在内核 (软件层面) 中开发和维护一套相关的机制,从原理上就是一种釜底抽薪的机制,因此可以说是软件成本很低。但是天下没有免费的午餐,软件成本下去了,硬件成本就该上来了:计算机系统是基于虚拟地址来处理 I/O,而 CPU 每次都需要先到缓存行中去找该地址上的数据,但是现在缓存行里的 index 和 tag 都已经是取自物理地址了,那么 CPU 就需要先把虚拟地址发给 MMU 去转换成物理地址之后才能到缓存中去查询,这样的话 PIPT 模式的缓存查询效率肯定要比 VIVT 差很多。好在 MMU 有 TLB 硬件加速,在一定程度上缓解了这个问题,不过这个成本还是存在的,而且 TLB 也会发生 cache miss,那时候就更慢了。
由于 PIPT 的可靠性 (彻底解决虚拟别名和歧义问题),虽然增加了硬件成本,但随着计算机硬件的发展,这方面的成本也越来越小,所以越来越多新造的计算机采用了 PIPT 模式。
VIPT
全称是 Virtually indexed, physically tagged,这是一种折中的方案:CPU 缓存行中的 index 取自虚拟地址,tag 取自物理地址。仔细研究 PIPT 模式之后可以发现,CPU 查询缓存和 MMU 翻译虚拟地址这两个流程其实是可以并行的,我们回忆一下在 VIVT CPU 查询缓存的流程:
- 先用虚拟地址的
index进行哈希取模定位到缓存行; - 取出缓存行中的
tag与虚拟地址的tag进行对比,如果相同则表示 缓存命中 (cache hit),否则就是缓存缺失 (cache miss); - 如果缓存命中就按照
offset的定位到数据在缓存行中的偏移量取出数据,如果是缓存缺失就把虚拟地址发到 MMU 转换成物理地址,然后到内存去加载数据。
如果我们从虚拟地址和物理地址各取一段作为 index 和 tag 的值,那么我们就可以实现这样的优化:CPU 收到用户进程的虚拟地址之后将其拆分成两部分,index 部分交给高速缓存控制器先去进行哈希取模,同时把 tag 部分的地址发给 MMU 去转换成物理地址,两边同时进行,等到 MMU 发回来 tag 部分的物理地址的时候,缓存控制器这边也已经通过 index 定位到了缓存行的位置并把数据取出来了,刚好可以拿着 tag 进行比对判断是否缓存命中。
VIPT 汲取了前面的 VIVT 和 PIPT 各自的一部分优势同时又不可避免地继承了它们的一部分劣势。所以 VIPT 模式的优点是:
- 因为
tag取自物理地址所以可以避免 VIVT 模式中虚拟歧义的问题。 index取自虚拟地址则可以提升 PIPT 的缓存查询速度。
缺点是:
index取自虚拟地址就意味着还是会有跟 VIVT 模式下的一样的虚拟别名问题,需要单独处理。- 只有
tag取自物理地址虽然可以缓解一部分性能问题,但是成本依然存在,而且如果最终是缓存缺失则需要再把index发到 MMU 去转换成物理地址,和tag部分的地址一起组成完整的物理地址去内存加载数据,也就是说 VIPT 在最坏情况下需要两次 MMU 地址翻译,比 PIPT 还慢。
VIPT 的综合性最好,兼顾了可靠性和性能,性价比高,所以有很多中低端硬件配置的计算机会选择 VIPT 模式,如果机器的 dcache 不超过 4KB,VIPT 的虚拟别名问题也就不存在了,在这方面就和 PIPT 一样,同时它的缓存查询性能比 PIPT 更快,这是最理想的状态。
PIVT
全称是 Physically indexed, virtually tagged,CPU 缓存行中的 index 取自物理地址,tag 取自虚拟地址。基本没有计算机会使用这么模式,因为它的理论价值就已经几乎为零了,更别提其实用价值:因为 index 取自物理地址,CPU 收到用户进程的虚拟地址之后必须先发给 MMU 去转换成物理地址才能开始进行高速缓存查询,也就是无法执行像 VIPT 模式那样的优化,缓存查询的性能很差,这一点和 PIPT 一样,但是又因为 tag 取自虚拟地址,所以 PIVT 还会有虚拟歧义的问题。这个模式唯一的优势就只是解决了虚拟别名问题,但是代价太大,所以没有什么价值,只有极少数有非常特殊的使用场景的计算机才可能会用 PIVT。
内核的 CPU cache 管理
现在可以回到内核源码中了,前面的 I/O 读写过程中,内核的源码在用户空间和内核空间之间拷贝数据的代码前后都调用了 flush_dcache_folio()/flush_dcache_page() 这两个函数就是我前面提到的 flush cache,主要用于那些使用了 VIVT 和 VIPT 的机器,用来解决虚拟别名和歧义问题,因此其底层实现高度依赖 CPU 架构,正如前文所述,VIVT 模式已经渐渐被弃用了,VIPT 模式则一般用于一些中等硬件配置的计算机,随着计算机硬件的高速发展,高端计算机越来越常见,这一类计算机通常倾向于选择 PIPT 模式,所以在内核里的很多 CPU 架构上这两个函数是空函数,只有在那些比较老的 CPU 架构中才有真正的实现,比如 m68k (摩托罗拉 68000) 和 arm 。下面是 m68k 架构的实现,用的是 C 语言的内联汇编实现的,可见这个 CPU 架构真的很老了52:
/* Push the page at kernel virtual address and clear the icache */
/* RZ: use cpush %bc instead of cpush %dc, cinv %ic */
static inline void __flush_pages_to_ram(void *vaddr, unsigned int nr)
{
if (CPU_IS_COLDFIRE) {
unsigned long addr, start, end;
addr = ((unsigned long) vaddr) & ~(PAGE_SIZE - 1);
start = addr & ICACHE_SET_MASK;
end = (addr + nr * PAGE_SIZE - 1) & ICACHE_SET_MASK;
if (start > end) {
flush_cf_bcache(0, end);
end = ICACHE_MAX_ADDR;
}
flush_cf_bcache(start, end);
} else if (CPU_IS_040_OR_060) {
unsigned long paddr = __pa(vaddr);
do {
__asm__ __volatile__("nop\n\t"
".chip 68040\n\t"
"cpushp %%bc,(%0)\n\t"
".chip 68k"
: : "a" (paddr));
paddr += PAGE_SIZE;
} while (--nr);
} else {
unsigned long _tmp;
__asm__ __volatile__("movec %%cacr,%0\n\t"
"orw %1,%0\n\t"
"movec %0,%%cacr"
: "=&d" (_tmp)
: "di" (FLUSH_I));
}
}
#define flush_dcache_page(page) __flush_pages_to_ram(page_address(page), 1)
#define flush_dcache_folio(folio) \
__flush_pages_to_ram(folio_address(folio), folio_nr_pages(folio))
还有 arm 架构53:
/*
* Ensure cache coherency between kernel mapping and userspace mapping
* of this page.
*
* We have three cases to consider:
* - VIPT non-aliasing cache: fully coherent so nothing required.
* - VIVT: fully aliasing, so we need to handle every alias in our
* current VM view.
* - VIPT aliasing: need to handle one alias in our current VM view.
*
* If we need to handle aliasing:
* If the page only exists in the page cache and there are no user
* space mappings, we can be lazy and remember that we may have dirty
* kernel cache lines for later. Otherwise, we assume we have
* aliasing mappings.
*
* Note that we disable the lazy flush for SMP configurations where
* the cache maintenance operations are not automatically broadcasted.
*/
void flush_dcache_folio(struct folio *folio)
{
struct address_space *mapping;
/*
* The zero page is never written to, so never has any dirty
* cache lines, and therefore never needs to be flushed.
*/
if (is_zero_pfn(folio_pfn(folio)))
return;
if (!cache_ops_need_broadcast() && cache_is_vipt_nonaliasing()) {
if (test_bit(PG_dcache_clean, &folio->flags))
clear_bit(PG_dcache_clean, &folio->flags);
return;
}
mapping = folio_flush_mapping(folio);
if (!cache_ops_need_broadcast() &&
mapping && !folio_mapped(folio))
clear_bit(PG_dcache_clean, &folio->flags);
else {
__flush_dcache_folio(mapping, folio);
if (mapping && cache_is_vivt())
__flush_dcache_aliases(mapping, folio);
else if (mapping)
__flush_icache_all();
set_bit(PG_dcache_clean, &folio->flags);
}
}
上面这段源码可以看出,这个函数就是专门针对 VIVT 和 VIPT 的虚拟别名问题的,而如果没有虚拟别名问题的情况下则会采用"懒处理",也就是延迟内核冲刷 dcache 的操作,这是通过清除页面的 PG_dcache_clean 标识来实现的 (后面会解释)。
在一些采用 PIPT 的较新的 CPU 架构中则这两个函数的实现要么是空要么就只做了一些简单的工作,比如 arm6454:
/*
* This function is called when a page has been modified by the kernel. Mark
* it as dirty for later flushing when mapped in user space (if executable,
* see __sync_icache_dcache).
*/
void flush_dcache_folio(struct folio *folio)
{
if (test_bit(PG_dcache_clean, &folio->flags))
clear_bit(PG_dcache_clean, &folio->flags);
}
void flush_dcache_page(struct page *page)
{
flush_dcache_folio(page_folio(page));
}
可以看到 arm64 架构下的这两个函数就只是把 folio 页的 PG_dcache_clean 标识清理了一下,这个标识表示页面是"干净" (没有被修改过) 的,也就是说如果用户进程需要它的话可以直接返回,把它清除掉就等于是告知内核后续要用 set_pte_at()/__sync_icache_dcache() 把这个页面在 dcache 的缓存给冲刷掉。
这里还需要注意一下,前面的内核源码中的在读和写操作中对这两个函数的调用还略微有点不一样,读操作的一侧只在数据拷贝之前调用一次 flush_dcache_folio()25:
static inline int mapping_writably_mapped(struct address_space *mapping)
{
return atomic_read(&mapping->i_mmap_writable) > 0;
}
writably_mapped = mapping_writably_mapped(mapping);
...
if (writably_mapped)
flush_dcache_folio(folio);
copied = copy_folio_to_iter(folio, offset, bytes, iter);
mapping_writably_mapped() 判断 mapping->i_mmap_writable 是否大于 0,这个字段记录了这个文件对应的虚拟内存区域是否包含 VM_SHARED/VM_MAYWRITE 页面数量,如果大于 0 则说明页面被共享使用,可能会出现虚拟别名问题,调用 flush_dcache_folio() 冲刷 dcache。
写操作的一侧则是数据拷贝之前调用 flush_dcache_page(),拷贝之后再调用一次25:
if (mapping_writably_mapped(mapping))
flush_dcache_page(page);
copied = copy_page_from_iter_atomic(page, offset, bytes, i);
flush_dcache_page(page);
为什么读操作不需要第二次调用而写操作需要呢?因为读操作不会修改内存页内容,所以只需要在内存页被共享时冲刷 dcache 避免虚拟别名问题即可,但是写操作修改内容之后会使得内存页变"脏",此时 CPU 高速缓存中如果缓存了这个页面,那么对应的缓存行就是过期数据了,为了防止后面这个 CPU 上的读请求拿到过期数据,就算该页没有被共享使用,也需要冲刷 dcache。
至此,Linux I/O 栈的源码分析也到此结束。
I/O 模式
在 Linux 或者其他 Unix-like 操作系统里,I/O 模式一般有三种:
- 程序控制 I/O
- 中断驱动 I/O
- DMA I/O
下面我分别详细地讲解一下这三种 I/O 模式。
程序控制 I/O
这是最简单的一种 I/O 模式,也叫忙等待或者轮询:用户通过发起一个系统调用,陷入内核态,内核将系统调用翻译成一个对应设备驱动程序的过程调用,接着设备驱动程序会启动 I/O 不断循环去检查该设备,看看是否已经就绪,一般通过返回码来表示,I/O 结束之后,设备驱动程序会把数据送到指定的地方并返回,切回用户态。
比如发起系统调用 recvfrom()55:
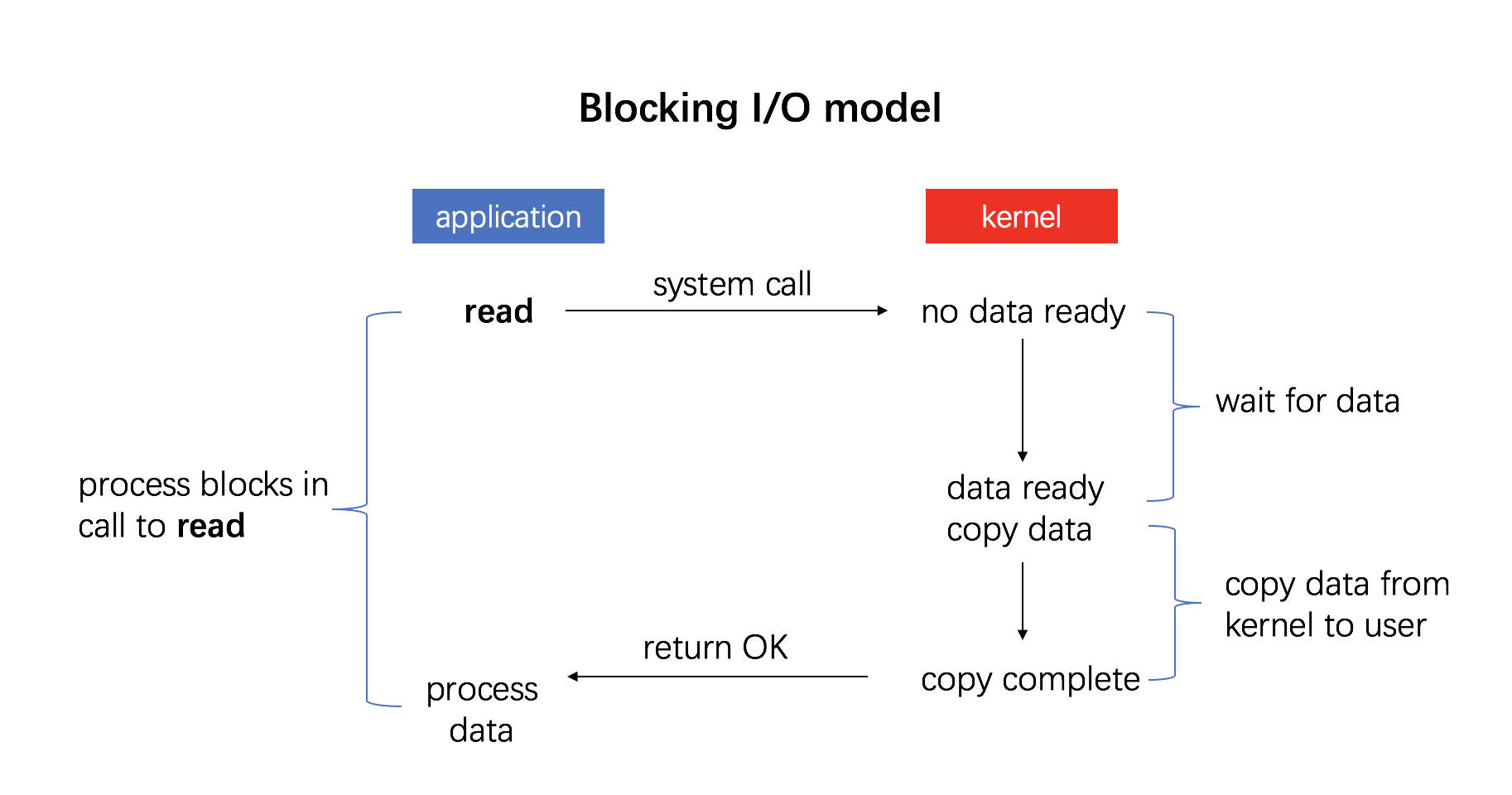
中断驱动 I/O
第二种 I/O 模式是利用中断来实现的:
流程如下:
- 用户进程发起一个
read()/recv()/recvfrom()/recvmsg()系统调用读取磁盘文件,陷入内核态并由其所在的 CPU 通过设备驱动程序向设备寄存器写入一个通知信号,告知设备控制器 (我们这里是磁盘控制器)要读取数据; - 磁盘控制器启动磁盘读取的过程,把数据从磁盘拷贝到磁盘控制器缓冲区里;
- 完成拷贝之后磁盘控制器会通过总线发送一个中断信号到中断控制器,如果此时中断控制器手头还有正在处理的中断或者有一个和该中断信号同时到达的更高优先级的中断,则这个中断信号将被忽略,而磁盘控制器会在后面持续发送中断信号直至中断控制器受理;
- 中断控制器收到磁盘控制器的中断信号之后会通过地址总线存入一个磁盘设备的编号,表示这次中断需要关注的设备是磁盘;
- 中断控制器向 CPU 置起一个磁盘中断信号;
- CPU 收到中断信号之后停止当前的工作,把当前的 PC/PSW 等寄存器压入堆栈保存现场,然后从地址总线取出设备编号,通过编号找到中断向量所包含的中断服务的入口地址,压入 PC 寄存器,开始运行磁盘中断服务,把数据从磁盘控制器的缓冲区拷贝到主存里的内核缓冲区;
- 最后 CPU 再把数据从内核缓冲区拷贝到用户缓冲区,完成读取操作,
read()返回,切换回用户态。
DMA I/O
并发系统的性能高低究其根本,是取决于如何对 CPU 资源的高效调度和使用,而回头看前面的中断驱动 I/O 模式的流程,可以发现第 6、7 步的数据拷贝工作都是由 CPU 亲自完成的,也就是在这两次数据拷贝阶段中 CPU 是完全被占用而不能处理其他工作的,那么这里明显是有优化空间的;第 7 步的数据拷贝是从内核缓冲区到用户缓冲区,都是在主存里,所以这一步只能由 CPU 亲自完成,但是第 6 步的数据拷贝,是从磁盘控制器的缓冲区到主存,是两个设备之间的数据传输,这一步并非一定要 CPU 来完成,可以借助 DMA 来完成,减轻 CPU 的负担。
DMA 全称是 Direct Memory Access,也即直接存储设备存取,是一种用来提供在外设和存储设备之间或者存储设备和存储设备之间的高速数据传输。整个过程无须 CPU 参与,数据直接通过 DMA 控制器进行快速地移动拷贝,节省 CPU 的资源去做其他工作。
目前,大部分的计算机都配备了 DMA 控制器,而 DMA 技术也支持大部分的外设和存储设备。借助于 DMA 机制,计算机的 I/O 过程就能更加高效:
DMA 控制器内部包含若干个可以被 CPU 读写的寄存器:一个主存地址寄存器 MAR (存放要交换数据的主存地址) 、一个外设地址寄存器 ADR (存放 I/O 设备的设备码,或者是设备信息存储区的寻址信息) 、一个字节数寄存器 WC (对传送数据的总字数进行统计) 、和一个或多个控制寄存器。
- 用户进程发起一个
read()/recv()/recvfrom()/recvmsg()系统调用读取磁盘文件,陷入内核态并由其所在的 CPU 通过设置 DMA 控制器的寄存器对它进行编程:把内核缓冲区和磁盘文件的地址分别写入 MAR 和 ADR 寄存器,然后把期望读取的字节数写入 WC 寄存器,启动 DMA 控制器; - DMA 控制器根据 ADR 寄存器里的信息知道这次 I/O 需要读取的外设是磁盘的某个地址,便向磁盘控制器发出一个命令,通知它从磁盘读取数据到其内部的缓冲区里;
- 磁盘控制器启动磁盘读取的过程,把数据从磁盘拷贝到磁盘控制器缓冲区里,并对缓冲区内数据的校验和进行检验,如果数据是有效的,那么 DMA 就可以开始了;
- DMA 控制器通过总线向磁盘控制器发出一个读请求信号从而发起 DMA 传输,这个信号和前面的中断驱动 I/O 小节里 CPU 发给磁盘控制器的读请求是一样的,它并不知道或者并不关心这个读请求是来自 CPU 还是 DMA 控制器;
- 紧接着 DMA 控制器将引导磁盘控制器将数据传输到 MAR 寄存器里的地址,也就是内核缓冲区;
- 数据传输完成之后,返回一个 ack 给 DMA 控制器,WC 寄存器里的值会减去相应的数据长度,如果 WC 还不为 0,则重复第 4 步到第 6 步,一直到 WC 里的字节数等于 0;
- 收到 ack 信号的 DMA 控制器会通过总线发送一个中断信号到中断控制器,如果此时中断控制器手头还有正在处理的中断或者有一个和该中断信号同时到达的更高优先级的中断,则这个中断信号将被忽略,而 DMA 控制器会在后面持续发送中断信号直至中断控制器受理;
- 中断控制器收到磁盘控制器的中断信号之后会通过地址总线存入一个主存设备的编号,表示这次中断需要关注的设备是主存;
- 中断控制器向 CPU 置起一个 DMA 中断的信号;
- CPU 收到中断信号之后停止当前的工作,把当前的 PC/PSW 等寄存器压入堆栈保存现场,然后从地址总线取出设备编号,通过编号找到中断向量所包含的中断服务的入口地址,压入 PC 寄存器,开始运行 DMA 中断服务,把数据从内核缓冲区拷贝到用户缓冲区,完成读取操作,
read()返回,切换回用户态。
通用 I/O 流程
Linux 中传统的 I/O 流程是通过 read()/write() 系统调用完成的,read() 把数据从硬件设备 (磁盘、网卡等) 读取到用户缓冲区,write() 则是把数据从用户缓冲区写出到硬件设备56 57:
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
一次完整的读磁盘文件然后写出到网卡的底层传输过程如下:
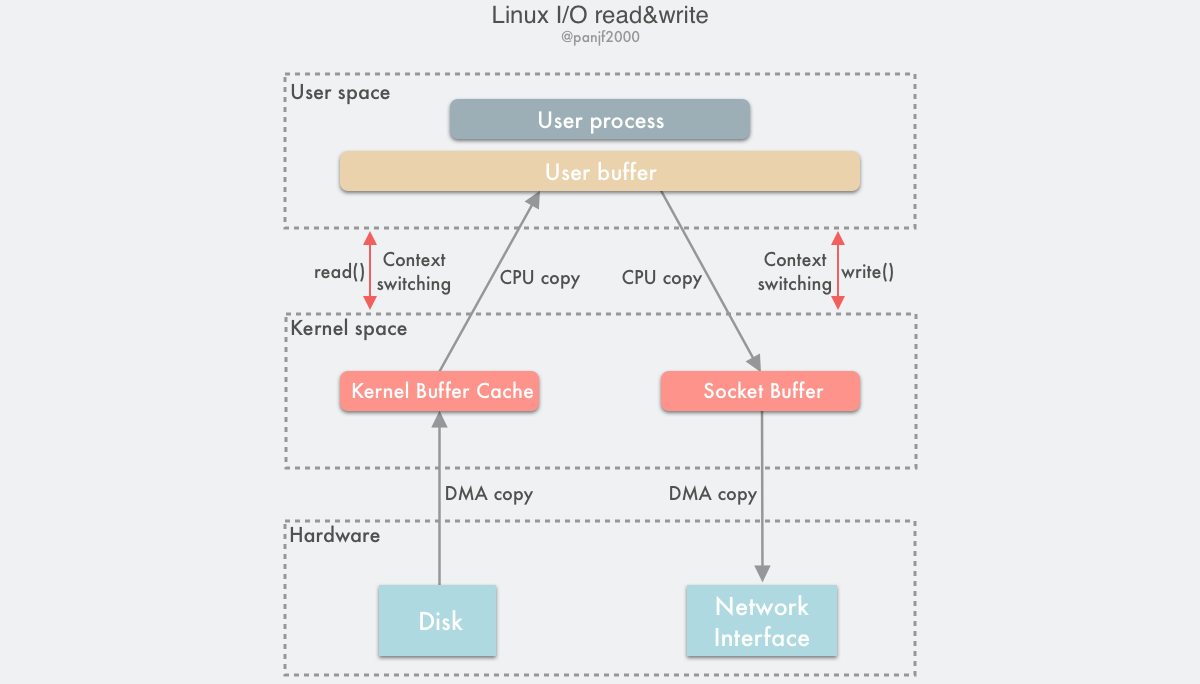
- 用户进程调用
read()系统调用,从用户态陷入内核态; - DMA 控制器将数据从硬盘拷贝到内核缓冲区,同时对 CPU 发出一个中断信号;
- CPU 收到中断信号之后启动中断程序把数据从内核空间的缓冲区复制到用户空间的缓冲区;
read()系统调用返回,上下文从内核态切换回用户态;- 用户进程调用
write()系统调用,再一次从用户态陷入内核态; - CPU 将用户空间的缓冲区上的数据复制到内核空间的缓冲区,同时触发 DMA 控制器;
- DMA 将内核空间的缓冲区上的数据复制到网卡;
write()返回,上下文从内核态切换回用户态。
可以清楚看到这里一共触发了 4 次用户态和内核态的上下文切换,分别是 read()/write() 调用和返回时的切换,2 次 DMA 拷贝,2 次 CPU 拷贝,加起来一共 4 次拷贝操作。
通过引入 DMA,我们已经把 Linux 的 I/O 过程中的 CPU 拷贝次数从 4 次减少到了 2 次,但是 CPU 拷贝依然是代价很大的操作,对系统性能的影响还是很大,特别是那些频繁 I/O 的场景,更是会因为 CPU 拷贝而损失掉很多性能,我们需要进一步优化,降低、甚至是完全避免 CPU 拷贝。
小结
到这里整个 Linux I/O 栈也算是做了一个概要性的分析,不仅从理论层面对其每一个分层都进行了剖析,还对相应的内核源码做了深入浅出的解读,加深理解。总结一下 Linux I/O 栈的七层结构如下:
- 虚拟文件系统层
- Page Cache 层
- 映射层
- 通用块层
- I/O 调度层
- 块设备驱动层
- 块设备硬件层
然后我介绍了 Linux 等操作系统中的三大基本 I/O 模式:
- 程序控制 I/O
- 中断驱动 I/O
- DMA I/O
让读者了解了用户程序中一个简单的 I/O 操作,在操作系统层面和硬件层面是如何运转的。最后介绍了一下 Linux 中的通用 I/O 流程,涉及了多少次 CPU 拷贝、多少次 DMA 拷贝,结合三大 I/O 模式,为下文的零拷贝 (Zero-Copy) 技术做铺垫。
Linux I/O 栈的内容可以说是浩如烟海,用一篇文章的篇幅就想将其全方位地解析完成是不可能的,这还只是在说理论层面的分析,如果还要结合内核源码一路解读下去,那真是一望无际;所以,这部分内容只能删繁就简地将一些我个人认为比较核心的知识摘出来做剖析,不求能读者在读完之后就立马变成 Linux 内核专家,只求能为各位打开一扇进入 Linux I/O 内核的小门,以后深入研究内核时能因此而方便一二,便足矣。
好了,前面的内容较多,我们稍事歇息片刻,好好消化一番。之后便添酒回灯重开宴,再战下半场的零拷贝技术。
零拷贝 (Zero-copy)
Zero-copy 是什么?
Wikipedia 的解释如下58:
"Zero-copy" describes computer operations in which the CPU does not perform the task of copying data from one memory area to another. This is frequently used to save CPU cycles and memory bandwidth when transmitting a file over a network.
零拷贝技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。
Zero-copy 能做什么?
- 减少甚至完全避免操作系统内核和用户应用程序地址空间这两者之间进行数据拷贝操作,从而减少用户态 -- 内核态上下文切换带来的系统开销。
- 减少甚至完全避免操作系统内核缓冲区之间进行数据拷贝操作。
- 帮助用户进程绕开操作系统内核空间直接访问硬件存储接口操作数据。
- 利用 DMA 而非 CPU 来完成硬件接口和内核缓冲区之间的数据拷贝,从而解放 CPU,使之能去执行其他的任务,提升系统性能。
Zero-copy 的实现方式有哪些?
从 zero-copy 这个概念被提出以来,相关的实现技术便犹如雨后春笋,层出不穷。但是截至目前为止,并没有任何一种 zero-copy 技术能满足所有的场景需求,还是计算机领域那句无比经典的名言:"There is no silver bullet"!
而在 Linux 平台上,同样也有很多的 zero-copy 技术,新旧各不同,可能存在于不同的内核版本里,很多技术可能有了很大的改进或者被更新的实现方式所替代,这些不同的实现技术按照其核心思想可以归纳成大致的以下三类:
- 内核内数据拷贝:主要目标是减少甚至避免用户空间和内核空间之间的数据拷贝。在一些场景下,用户进程在数据传输过程中并不需要对数据进行访问和处理,那么数据在 Linux 的 page cache 和用户进程的缓冲区之间的数据传输就完全可以避免,让数据拷贝完全在内核里进行,甚至可以通过更巧妙的方式避免在内核里的数据拷贝。这一类实现一般是通过增加新的系统调用来完成的,比如 Linux 中的
mmap()、sendfile()、splice()和copy_file_range()等。 - 绕过内核的直接 I/O:允许在用户态进程绕过内核直接和硬件进行数据传输,内核在传输过程中只负责一些管理和辅助的工作。这种方式其实和第一种有点类似,也是试图避免用户空间和内核空间之间的数据传输,只是第一种方式是把数据传输过程放在内核态完成,而这种方式则是直接绕过内核和硬件通信,效果类似但原理完全不同。
- 内核态和用户态之间的传输优化:这种方式侧重于在用户进程的缓冲区和操作系统的页缓存之间的 CPU 拷贝的优化,通过一些手段如 Copy-on-Write —— 减少用户空间和内核空间之间的数据复制、Buffer pool —— 通过回收和重用 buffer 降低内存分配的频次。这种方法延续了以往那种传统的通信方式,但性能上会更高效。
内核内数据拷贝
mmap()
mmap() 创建内存映射59:
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void *addr, size_t length);
一种简单的实现方案是在一次读写过程中用 Linux 的另一个系统调用 mmap() 替换原先的 read(),mmap() 也即是内存映射 (memory map) :把用户进程空间的一段内存缓冲区 (user buffer) 映射到文件所在的内核缓冲区 (kernel buffer) 上。
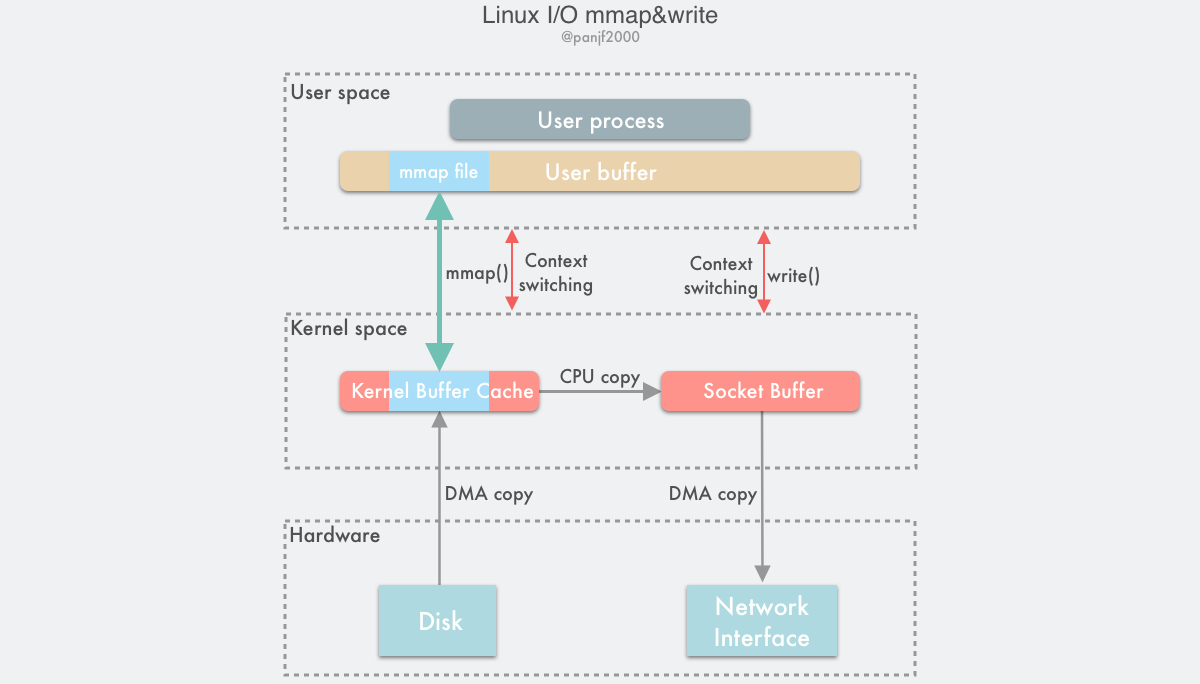
利用 mmap() 替换 read(),配合 write() 调用的整个流程如下:
- 用户进程调用
mmap(),从用户态陷入内核态,将内核缓冲区映射到用户缓存区; - DMA 控制器将数据从硬盘拷贝到内核缓冲区;
mmap()返回,上下文从内核态切换回用户态;- 用户进程调用
write(),尝试把文件数据写到内核里的套接字缓冲区,再次陷入内核态; - CPU 将内核缓冲区中的数据拷贝到的套接字缓冲区;
- DMA 控制器将数据从套接字缓冲区拷贝到网卡完成数据传输;
write()返回,上下文从内核态切换回用户态。
通过这种方式,有两个优点:一是节省内存空间,因为用户进程上的这一段内存是虚拟的,并不真正占据物理内存,只是映射到文件所在的内核缓冲区上,因此可以节省一半的内存占用;二是省去了一次 CPU 拷贝,对比传统的 Linux I/O 读写,数据不需要再经过用户进程进行转发了,而是直接在内核里就完成了拷贝。所以使用 mmap() 之后的拷贝次数是 2 次 DMA 拷贝,1 次 CPU 拷贝,加起来一共 3 次拷贝操作,比传统的 I/O 方式节省了一次 CPU 拷贝以及一半的内存,不过因为 mmap() 也是一个系统调用,因此用户态和内核态的切换还是 4 次。
mmap() 因为既节省 CPU 拷贝次数又节省内存,所以比较适合大文件传输的场景。虽然 mmap() 完全是符合 POSIX 标准的,但是它也不是完美的,因为它并不总是能达到理想的数据传输性能。首先是因为数据数据传输过程中依然需要一次 CPU 拷贝,其次是内存映射技术是一个开销很大的虚拟存储操作:这种操作需要修改页表以及用内核缓冲区里的文件数据汰换掉当前 TLB 里的缓存以维持虚拟内存映射的一致性。但是,因为内存映射通常针对的是相对较大的数据区域,所以对于相同大小的数据来说,内存映射所带来的开销远远低于 CPU 拷贝所带来的开销。此外,使用 mmap() 还可能会遇到一些需要值得关注的特殊情况,例如,在 mmap() --> write() 这两个系统调用的整个传输过程中,如果有其他的进程突然截断了这个文件,那么这时用户进程就会因为访问非法地址而被一个从总线传来的 SIGBUS 中断信号杀死并且产生一个 core dump。有两种解决办法:
- 设置一个信号处理器,专门用来处理 SIGBUS 信号,这个处理器直接返回,
write()就可以正常返回已写入的字节数而不会被 SIGBUS 中断,errno 错误码也会被设置成 success。然而这实际上是一个掩耳盗铃的解决方案,因为 BIGBUS 信号的带来的信息是系统发生了一些很严重的错误,而我们却选择忽略掉它,一般不建议采用这种方式。 - 通过内核的文件租借锁 (这是 Linux 的叫法,Windows 上称之为机会锁) 来解决这个问题,这种方法相对来说更好一些。我们可以通过内核对文件描述符上读/写的租借锁,当另外一个进程尝试对当前用户进程正在进行传输的文件进行截断的时候,内核会发送给用户一个实时信号:RT_SIGNAL_LEASE 信号,这个信号会告诉用户内核正在破坏你加在那个文件上的读/写租借锁,这时
write()系统调用会被中断,并且当前用户进程会被 SIGBUS 信号杀死,返回值则是中断前写的字节数,errno 同样会被设置为 success。文件租借锁需要在对文件进行内存映射之前设置,最后在用户进程结束之前释放掉。
这种方法适用于不同的内存映射的系统调用,同理也可以用 shmget()、shm_open、shmat() 等,但要注意不同的系统调用其使用方法不同,限制条件也不同。
sendfile()
在 Linux 内核 2.2 版本中,引入了一个新的系统调用 sendfile()60:
#include <sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
从功能上来看,这个系统调用将 mmap() + write() 这两个系统调用合二为一,实现了一样效果的同时还简化了用户接口,其他的一些 Unix-like 的系统像 BSD、Solaris 和 AIX 等也有类似的实现,甚至 Windows 上也有一个功能类似的 API 函数 TransmitFile。
out_fd 和 in_fd 分别代表了写入和读出的文件描述符,in_fd 必须是一个指向文件的文件描述符,且要能支持类 mmap() 内存映射,不能是 Socket 类型,而 out_fd 在 Linux 内核 2.6.33 版本之前只能是一个指向 socket 的文件描述符,从 2.6.33 之后则可以是任意类型的文件描述符。off_t 是一个代表了 in_fd 偏移量的指针,指示 sendfile() 该从 in_fd 的哪个位置开始读取,函数返回后,这个指针会被更新成 sendfile() 最后读取的字节位置处,表明此次调用共读取了多少文件数据,最后的 count 参数则是此次调用需要传输的字节总数。
使用 sendfile() 完成一次数据读写的流程如下:
- 用户进程调用
sendfile()从用户态陷入内核态; - DMA 控制器将数据从硬盘拷贝到内核缓冲区;
- CPU 将内核缓冲区中的数据拷贝到套接字缓冲区;
- DMA 控制器将数据从套接字缓冲区拷贝到网卡完成数据传输;
sendfile()返回,上下文从内核态切换回用户态。
基于 sendfile(), 整个数据传输过程中共发生 2 次 DMA 拷贝和 1 次 CPU 拷贝,这个和 mmap() + write() 相同,但是因为 sendfile() 只是一次系统调用,因此比前者少了一次用户态和内核态的上下文切换开销。读到这里,聪明的读者应该会开始提问了:"sendfile() 会不会遇到和 mmap() + write() 相似的文件截断问题呢?",很不幸,答案是肯定的。sendfile() 一样会有文件截断的问题,但欣慰的是,sendfile() 不仅比 mmap() + write() 在接口使用上更加简洁,而且处理文件截断时也更加优雅:如果 sendfile() 过程中遭遇文件截断,则 sendfile() 系统调用会被中断杀死之前返回给用户进程其中断前所传输的字节数,errno 会被设置为 success,无需用户提前设置信号处理器,当然你要设置一个进行个性化处理也可以,也不需要像之前那样提前给文件描述符设置一个租借锁,因为最终结果还是一样的。
sendfile() 相较于 mmap() 的另一个优势在于数据在传输过程中始终没有越过用户态和内核态的边界,因此极大地减少了存储管理的开销。即便如此,sendfile() 依然是一个适用性很窄的技术,最适合的场景基本也就是一个静态文件服务器了。而且根据 Linus 在 2001 年和其他内核维护者的邮件列表内容,其实当初之所以决定在 Linux 上实现 sendfile() 仅仅是因为在其他操作系统平台上已经率先实现了,而且有大名鼎鼎的 Apache Web 服务器已经在使用了,为了兼容 Apache Web 服务器才决定在 Linux 上也实现这个技术,而且 sendfile() 实现上的简洁性也和 Linux 内核的其他部分集成得很好,所以 Linus 也就同意了这个提案。
然而 sendfile() 本身是有很大问题的,从不同的角度来看的话主要是:
- 首先一个是这个接口并没有进行标准化,导致
sendfile()在 Linux 上的接口实现和其他类 Unix 系统的实现并不相同; - 其次由于网络传输的异步性,很难在接收端实现和
sendfile()对接的技术,因此接收端一直没有实现对应的这种技术; - 最后从性能方面考量,因为
sendfile()在把磁盘文件从内核缓冲区 (page cache) 传输到到套接字缓冲区的过程中依然需要 CPU 参与,这就很难避免 CPU 的高速缓存被传输的数据所污染。
此外,需要说明下,sendfile() 的最初设计并不是用来处理大文件的,因此如果需要处理很大的文件的话,可以使用另一个系统调用 sendfile64(),它支持对更大的文件内容进行寻址和偏移。
sendfile() with DMA Scatter/Gather Copy
上一小节介绍的 sendfile() 技术已经把一次数据读写过程中的 CPU 拷贝的降低至只有 1 次了,但是人永远是贪心和不知足的,现在如果想要把这仅有的一次 CPU 拷贝也去除掉,有没有办法呢?
当然有!通过引入一个新硬件上的支持,我们可以把这个仅剩的一次 CPU 拷贝也给抹掉:Linux 在内核 2.4 版本里引入了 DMA 的 scatter/gather —— 分散/收集功能,并修改了 sendfile() 的代码使之和 DMA 适配。scatter 使得 DMA 拷贝可以不再需要把数据存储在一片连续的内存空间上,而是允许离散存储,gather 则能够让 DMA 控制器根据少量的元信息:一个包含了内存地址和数据大小的缓冲区描述符,收集存储在各处的数据,最终还原成一个完整的网络包,直接拷贝到网卡而非套接字缓冲区,避免了最后一次的 CPU 拷贝:
sendfile() + DMA Gather 的数据传输过程如下:
- 用户进程调用
sendfile(),从用户态陷入内核态; - DMA 控制器使用 scatter 功能把数据从硬盘拷贝到内核缓冲区进行离散存储;
- CPU 把包含内存地址和数据长度的缓冲区描述符拷贝到套接字缓冲区,DMA 控制器能够根据这些信息生成网络包数据分组的报头和报尾
- DMA 控制器根据缓冲区描述符里的内存地址和数据大小,使用 scatter-gather 功能开始从内核缓冲区收集离散的数据并组包,最后直接把网络包数据拷贝到网卡完成数据传输;
sendfile()返回,上下文从内核态切换回用户态。
基于这种方案,我们就可以把这仅剩的唯一一次 CPU 拷贝也给去除了 (严格来说还是会有一次,但是因为这次 CPU 拷贝的只是那些微乎其微的元信息,开销几乎可以忽略不计) ,理论上,数据传输过程就再也没有 CPU 的参与了,也因此 CPU 的高速缓存再不会被污染了,也不再需要 CPU 来计算数据校验和了,CPU 可以去执行其他的业务计算任务,同时和 DMA 的 I/O 任务并行,此举能极大地提升系统性能。
splice()
sendfile() + DMA Scatter/Gather 的零拷贝方案虽然高效,但是也有两个缺点:
- 这种方案需要引入新的硬件支持;
- 虽然
sendfile()的输出文件描述符在 Linux kernel 2.6.33 版本之后已经可以支持任意类型的文件描述符,但是输入文件描述符依然只能指向文件。
这两个缺点限制了 sendfile() + DMA Scatter/Gather 方案的适用场景。为此,Linux 内核 2.6.17 版本20引入了一个新的系统调用 splice(),它在功能上和 sendfile() 非常相似,但是能够实现在任意类型的两个文件描述符时之间传输数据;而在底层实现上,splice()又比 sendfile() 少了一次 CPU 拷贝,也就是等同于 sendfile() + DMA Scatter/Gather,完全去除了数据传输过程中的 CPU 拷贝。
splice() 系统调用函数定义如下61:
#define _GNU_SOURCE /* See feature_test_macros(7) */
#define _FILE_OFFSET_BITS 64
#include <fcntl.h>
#include <unistd.h>
int pipe(int pipefd[2]);
int pipe2(int pipefd[2], int flags);
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);
fd_in 和 fd_out 分别代表了输入端和输出端的文件描述符,这两个文件描述符必须有一个是指向管道设备的,这也是一个不太友好的限制,虽然 Linux 内核开发的官方从这个系统调用推出之时就承诺未来可能会重构去掉这个限制,然而他们许下这个承诺之后就如同石沉大海,如今 14 年过去了,依旧杳无音讯...
off_in 和 off_out 则分别是 fd_in 和 fd_out 的偏移量指针,指示内核从哪里读取和写入数据,len 则指示了此次调用希望传输的字节数,最后的 flags 是系统调用的标记选项位掩码,用来设置系统调用的行为属性的,由以下 0 个或者多个值通过『或』操作组合而成:
- SPLICE_F_MOVE:指示
splice()尝试仅仅是移动内存页面而不是复制,设置了这个值不代表就一定不会复制内存页面,复制还是移动取决于内核能否从管道中移动内存页面,或者管道中的内存页面是否是完整的;这个标记的初始实现有很多 bugs,所以从 Linux 2.6.21 版本开始就已经无效了,但还是保留了下来,因为在未来的版本里可能会重新被实现。 - SPLICE_F_NONBLOCK:指示
splice()不要阻塞 I/O,也就是使得splice()调用成为一个非阻塞调用,可以用来实现异步数据传输,不过需要注意的是,数据传输的两个文件描述符也最好是预先通过 O_NONBLOCK 标记成非阻塞 I/O,不然splice()调用还是有可能被阻塞。 - SPLICE_F_MORE:通知内核下一个
splice()系统调用将会有更多的数据传输过来,这个标记对于输出端是 socket 的场景非常有用。
splice() 是基于 Linux 的管道缓冲区 (pipe buffer) 机制实现的,所以 splice() 的两个入参文件描述符才要求必须有一个是管道设备,一个典型的 splice() 用法是:
int pfd[2];
pipe(pfd);
ssize_t bytes = splice(file_fd, NULL, pfd[1], NULL, 4096, SPLICE_F_MOVE);
assert(bytes != -1);
bytes = splice(pfd[0], NULL, socket_fd, NULL, bytes, SPLICE_F_MOVE | SPLICE_F_MORE);
assert(bytes != -1);
数据传输过程图:
使用 splice() 完成一次磁盘文件到网卡的读写过程如下:
- 用户进程调用
pipe(),从用户态陷入内核态,创建匿名单向管道,pipe()返回,上下文从内核态切换回用户态; - 用户进程调用
splice(),从用户态陷入内核态; - DMA 控制器将数据从硬盘拷贝到内核缓冲区,从管道的写入端"拷贝"进管道,
splice()返回,上下文从内核态回到用户态; - 用户进程再次调用
splice(),从用户态陷入内核态; - 内核把数据从管道的读取端"拷贝"到套接字缓冲区,DMA 控制器将数据从套接字缓冲区拷贝到网卡;
splice()返回,上下文从内核态切换回用户态。
相信看完上面的读写流程之后,读者肯定会非常困惑:说好的 splice() 是 sendfile() 的改进版呢?sendfile() 好歹只需要一次系统调用,splice() 居然需要三次,这也就罢了,居然中间还搞出来一个管道,而且还要在内核空间拷贝两次,这算个毛的改进啊?
我最开始了解 splice() 的时候,也是这个反应,但是深入学习它之后,才渐渐知晓个中奥妙,且听我细细道来:
先来了解一下 pipe buffer 管道,管道是 Linux 上用来供进程之间通信的信道,管道有两个端:写入端和读出端,从进程的视角来看,管道表现为一个 FIFO 字节流环形队列:
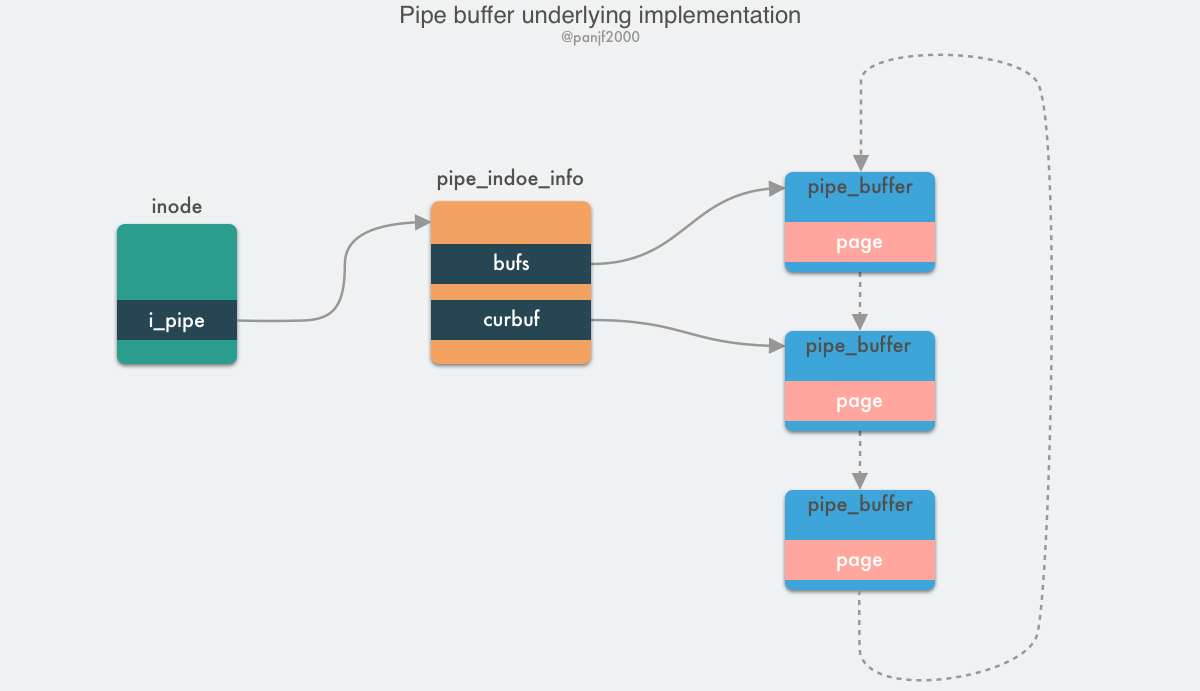
管道本质上是一个内存中的文件,也就是本质上还是基于 Linux 的 VFS,用户进程可以通过 pipe() 系统调用创建一个匿名管道,创建完成之后会有两个 VFS 的 file 结构体的 inode 分别指向其写入端和读出端,并返回对应的两个文件描述符,用户进程通过这两个文件描述符读写管道;管道的容量单位是一个虚拟内存的页,也就是 4KB,总大小一般是 16 个页,基于其环形结构,管道的页可以循环使用,提高内存利用率。 Linux 中以 pipe_buffer 结构体封装管道页,file 结构体里的 inode 字段里会保存一个 pipe_inode_info 结构体指代管道,其中会保存很多读写管道时所需的元信息,环形队列的头部指针页,读写时的同步机制如互斥锁、等待队列等:
struct pipe_buffer {
struct page *page; // 内存页结构
unsigned int offset, len; // 偏移量,长度
const struct pipe_buf_operations *ops;
unsigned int flags;
unsigned long private;
};
struct pipe_inode_info {
struct mutex mutex;
wait_queue_head_t wait;
unsigned int nrbufs, curbuf, buffers;
unsigned int readers;
unsigned int writers;
unsigned int files;
unsigned int waiting_writers;
unsigned int r_counter;
unsigned int w_counter;
struct page *tmp_page;
struct fasync_struct *fasync_readers;
struct fasync_struct *fasync_writers;
struct pipe_buffer *bufs;
struct user_struct *user;
};
pipe_buffer 中保存了数据在内存中的页、偏移量和长度,以这三个值来定位数据,注意这里的页不是虚拟内存的页,而用的是物理内存的页框,因为管道时跨进程的信道,因此不能使用虚拟内存来表示,只能使用物理内存的页框定位数据;管道的正常读写操作是通过 pipe_write()/pipe_read() 来完成的,通过把数据读取/写入环形队列的 pipe_buffer 来完成数据传输。
splice() 是基于 pipe buffer 实现的,但是它在通过管道传输数据的时候却是零拷贝,因为它在写入读出时并没有使用 pipe_write()/pipe_read() 真正地在管道缓冲区写入读出数据,而是通过把数据在内存缓冲区中的物理内存页框指针、偏移量和长度赋值给前文提及的 pipe_buffer 中对应的三个字段来完成数据的"拷贝",也就是其实只拷贝了数据的内存地址等元信息。
splice() 在 Linux 内核源码中的内部实现是 do_splice() 函数,而写入读出管道则分别是通过 do_splice_to() 和 do_splice_from(),这里我们重点来解析下写入管道的源码,也就是 do_splice_to(),我现在手头的 Linux 内核版本是 v4.8.17,我们就基于这个版本来分析,至于读出的源码函数 do_splice_from(),原理是相通的,大家举一反三即可。
splice() 写入数据到管道的调用链式:do_splice() --> do_splice_to() --> splice_read()
static long do_splice(struct file *in, loff_t __user *off_in,
struct file *out, loff_t __user *off_out,
size_t len, unsigned int flags)
{
...
// 判断是写出 fd 是一个管道设备,则进入数据写入的逻辑
if (opipe) {
if (off_out)
return -ESPIPE;
if (off_in) {
if (!(in->f_mode & FMODE_PREAD))
return -EINVAL;
if (copy_from_user(&offset, off_in, sizeof(loff_t)))
return -EFAULT;
} else {
offset = in->f_pos;
}
// 调用 do_splice_to 把文件内容写入管道
ret = do_splice_to(in, &offset, opipe, len, flags);
if (!off_in)
in->f_pos = offset;
else if (copy_to_user(off_in, &offset, sizeof(loff_t)))
ret = -EFAULT;
return ret;
}
return -EINVAL;
}
进入 do_splice_to() 之后,再调用 splice_read():
static long do_splice_to(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len,
unsigned int flags)
{
ssize_t (*splice_read)(struct file *, loff_t *,
struct pipe_inode_info *, size_t, unsigned int);
int ret;
if (unlikely(!(in->f_mode & FMODE_READ)))
return -EBADF;
ret = rw_verify_area(READ, in, ppos, len);
if (unlikely(ret < 0))
return ret;
if (unlikely(len > MAX_RW_COUNT))
len = MAX_RW_COUNT;
// 判断文件的文件的 file 结构体的 f_op 中有没有可供使用的、支持 splice 的 splice_read 函数指针
// 因为是 splice() 调用,因此内核会提前给这个函数指针指派一个可用的函数
if (in->f_op->splice_read)
splice_read = in->f_op->splice_read;
else
splice_read = default_file_splice_read;
return splice_read(in, ppos, pipe, len, flags);
}
in->f_op->splice_read 这个函数指针根据文件描述符的类型不同有不同的实现。本文读到这里,看到 f_op 这个字段应该不会感到陌生了,它就是 VFS 的 file 文件对象操作函数表 file_operations,不同文件系统的 file_operations 中的函数实现可能有略微不同,不过对于 splice_read()/splice_write() 这两个和 splice() 系统调用相关的函数来说,其内部实现通常都是使用内核的通用函数,顶多不同文件系统会有一些不同的前置检查之类的外围代码,这里的 in 是一个文件,因此最终调用的内核通用函数就是 generic_file_splice_read(),如果是 socket 的话,则是 sock_splice_read(),其他的类型也会有对应的实现,总之我们这里将使用的是 generic_file_splice_read() 函数,这个函数会继续调用内部函数 __generic_file_splice_read 完成以下工作:
- 在 page cache 页缓存里进行搜寻,看看我们要读取这个文件内容是否已经在缓存里了,如果是则直接用,否则如果不存在或者只有部分数据在缓存中,则分配一些新的内存页并进行读入数据操作,同时会增加页框的引用计数;
- 基于这些内存页,初始化 splice_pipe_desc 结构,这个结构保存会保存文件数据的地址元信息,包含有物理内存页框地址,偏移、数据长度,也就是 pipe_buffer 所需的三个定位数据的值;
- 最后,调用
splice_to_pipe(),splice_pipe_desc 结构体实例是函数入参。
ssize_t splice_to_pipe(struct pipe_inode_info *pipe, struct splice_pipe_desc *spd)
{
...
for (;;) {
if (!pipe->readers) {
send_sig(SIGPIPE, current, 0);
if (!ret)
ret = -EPIPE;
break;
}
if (pipe->nrbufs < pipe->buffers) {
int newbuf = (pipe->curbuf + pipe->nrbufs) & (pipe->buffers - 1);
struct pipe_buffer *buf = pipe->bufs + newbuf;
// 写入数据到管道,没有真正拷贝数据,而是内存地址指针的移动,
// 把物理页框、偏移量和数据长度赋值给 pipe_buffer 完成数据入队操作
buf->page = spd->pages[page_nr];
buf->offset = spd->partial[page_nr].offset;
buf->len = spd->partial[page_nr].len;
buf->private = spd->partial[page_nr].private;
buf->ops = spd->ops;
if (spd->flags & SPLICE_F_GIFT)
buf->flags |= PIPE_BUF_FLAG_GIFT;
pipe->nrbufs++;
page_nr++;
ret += buf->len;
if (pipe->files)
do_wakeup = 1;
if (!--spd->nr_pages)
break;
if (pipe->nrbufs < pipe->buffers)
continue;
break;
}
...
}
这里可以清楚地看到 splice() 所谓的写入数据到管道其实并没有真正地拷贝数据,而是玩了个 tricky 的操作:只进行内存地址指针的拷贝而不真正去拷贝数据。所以,数据 splice() 在内核中并没有进行真正的数据拷贝,因此 splice() 系统调用也是零拷贝。
还有一点需要注意,前面说过管道的容量是 16 个内存页,也就是 16 * 4KB = 64 KB,也就是说一次往管道里写数据的时候最好不要超过 64 KB,否则的话会 splice() 会阻塞住,除非在创建管道的时候使用的是 pipe2() 并通过传入 O_NONBLOCK 属性将管道设置为非阻塞。
即使 splice() 通过内存地址指针避免了真正的拷贝开销,但是算起来它还要使用额外的管道来完成数据传输,也就是比 sendfile() 多了两次系统调用,这不是又增加了上下文切换的开销吗?为什么不直接在内核创建管道并调用那两次 splice(),然后只暴露给用户一次系统调用呢?实际上因为 splice() 利用管道而非硬件来完成零拷贝的实现比 sendfile() + DMA Scatter/Gather 的门槛更低,因此后来的 sendfile() 的底层实现就已经替换成 splice() 了。
至于说 splice() 本身的 API 为什么还是这种使用模式,那是因为 Linux 内核开发团队一直想把基于管道的这个限制去掉,但不知道因为什么一直搁置,所以这个 API 也就一直没变化,只能等内核团队哪天想起来了这一茬,然后重构一下使之不再依赖管道,在那之前,使用 splice() 依然还是需要额外创建管道来作为中间缓冲。事实上,内核中有一个 splice 的工具函数,使用当前进程自带的 pipe,这样调用者就无需创建并传入 pipe 了,但是很可惜这个 helper function 只在内部使用 ( sendfile() 的底层实现),没有开放给上层开发者:
// 系统调用入口
SYSCALL_DEFINE4(sendfile, int, out_fd, int, in_fd, off_t __user *, offset, size_t, count)
{
loff_t pos;
off_t off;
ssize_t ret;
if (offset) {
if (unlikely(get_user(off, offset)))
return -EFAULT;
pos = off;
// 真正执行数据复制的函数
ret = do_sendfile(out_fd, in_fd, &pos, count, MAX_NON_LFS);
if (unlikely(put_user(pos, offset)))
return -EFAULT;
return ret;
}
// 同上
return do_sendfile(out_fd, in_fd, NULL, count, 0);
}
// sendfile() 的底层实现函数
static ssize_t do_sendfile(int out_fd, int in_fd, loff_t *ppos,
size_t count, loff_t max)
{
...
opipe = get_pipe_info(out.file, true);
// 目标对象不是 pipe,调用 do_splice_direct()
// 使用进程自带的 pipe 借助 splice() 进行数据复制
if (!opipe) {
retval = rw_verify_area(WRITE, out.file, &out_pos, count);
if (retval < 0)
goto fput_out;
retval = do_splice_direct(in.file, &pos, out.file, &out_pos,
count, fl);
} else {
if (out.file->f_flags & O_NONBLOCK)
fl |= SPLICE_F_NONBLOCK;
// 目标对象是 pipe,则可以直接使用 splice() 复制数据
retval = splice_file_to_pipe(in.file, opipe, &pos, count, fl);
}
...
}
/**
* do_splice_direct - splices data directly between two files
* @in: file to splice from
* @ppos: input file offset
* @out: file to splice to
* @opos: output file offset
* @len: number of bytes to splice
* @flags: splice modifier flags
*
* Description:
* For use by do_sendfile(). splice can easily emulate sendfile, but
* doing it in the application would incur an extra system call
* (splice in + splice out, as compared to just sendfile()). So this helper
* can splice directly through a process-private pipe.
*
* Callers already called rw_verify_area() on the entire range.
*/
ssize_t do_splice_direct(struct file *in, loff_t *ppos, struct file *out,
loff_t *opos, size_t len, unsigned int flags)
{
// do_splice_direct_actor() 函数里会先把数据复制到进程自带的 pipe,
// 然后使用 direct_splice_actor() 回调把数据从 pipe 复制到目标对象
return do_splice_direct_actor(in, ppos, out, opos, len, flags,
direct_splice_actor);
}
EXPORT_SYMBOL(do_splice_direct);
/**
* splice_direct_to_actor - splices data directly between two non-pipes
* @in: file to splice from
* @sd: actor information on where to splice to
* @actor: handles the data splicing
*
* Description:
* This is a special case helper to splice directly between two
* points, without requiring an explicit pipe. Internally an allocated
* pipe is cached in the process, and reused during the lifetime of
* that process.
*
*/
ssize_t splice_direct_to_actor(struct file *in, struct splice_desc *sd,
splice_direct_actor *actor)
{
...
/*
* neither in nor out is a pipe, setup an internal pipe attached to
* 'out' and transfer the wanted data from 'in' to 'out' through that
*/
pipe = current->splice_pipe;
if (unlikely(!pipe)) {
pipe = alloc_pipe_info();
if (!pipe)
return -ENOMEM;
/*
* We don't have an immediate reader, but we'll read the stuff
* out of the pipe right after the splice_to_pipe(). So set
* PIPE_READERS appropriately.
*/
pipe->readers = 1;
current->splice_pipe = pipe;
}
...
while (len) {
size_t read_len;
loff_t pos = sd->pos, prev_pos = pos;
ret = do_splice_read(in, &pos, pipe, len, flags);
if (unlikely(ret <= 0))
goto read_failure;
...
ret = actor(pipe, sd);
...
}
}
// 把数据从 pipe 复制到目标对象
static int direct_splice_actor(struct pipe_inode_info *pipe,
struct splice_desc *sd)
{
struct file *file = sd->u.file;
long ret;
file_start_write(file);
ret = do_splice_from(pipe, file, sd->opos, sd->total_len, sd->flags);
file_end_write(file);
return ret;
}
---
static inline struct task_struct *get_current(void)
{
return(current_thread_info()->task);
}
#define current get_current()
上面的代码注释应该已经把整个流程都叙述清楚了,可以看到 splice_direct_to_actor() 里调用了 get_current() 来获取当前的用户进程的任务 (current 代表的是调用这个系统调用的用户进程62) 并使用它自带的 pipe 来调用 splice(),可能有些读者会担心如果在进程中使用多线程调用 sendfile() 会不会导致这个 pipe 里的数据错乱,其实不用担心,因为这个 task_struct 实际上是 thread storage 级别的,从源码可以看到 get_current() 是通过调用 current_thread_info() 来实现的;另外,这个工具函数 do_splice_direct() 用了 EXPORT_SYMBOL 来修饰,说明它是开放给所有其他的内核模块调用的,也就是说如果你编写内核模块的时候可以用,编写完模块之后装载进内核之后运行就行了,但很遗憾应用层开发者就没法用了。
如果你的业务场景很适合使用 splice(),但又是性能敏感的,不想频繁地创建销毁 pipe buffer 管道缓冲区,那么可以参考一下 HAProxy 使用 splice() 时采用的优化方案:预先分配一个 pipe buffer pool 缓存管道,每次调用 spclie() 的时候去缓存池里取一个管道,用完就放回去,循环利用,提升性能。这样的话虽然使用 splice() 需要三次系统调用,比 sendfile() 还多一次,但是现在 pipe 被复用了,那么只要 splice() 的调用次数足够多,多出来的一次 pipe()/pipe2() 也就显得无足轻重了。
最后,关于 splice() 的 SPLICE_F_NONBLOCK 有一个使用方面的坑值得一提:如果希望在调用 splice() 时是非阻塞的,那么除了 fd_in 和 fd_out 这两个文件描述符要设置成 non-blocking 的之外,还必须将 SPLICE_F_NONBLOCK 设置到 splice() 函数的 flags 参数里,否则的话系统调用还是有可能会在内核中的某些地方阻塞从而导致用户空间也阻塞。这是因为 SPLICE_F_NONBLOCK 这个 flag 影响的是 splice() 系统调用本身的行为,而不是 fd_in/fd_out,所以即便这两个文件描述符都是非阻塞的,但 splice() 本身还是有可能阻塞的,所以才需要这个 flag 来控制其本身不阻塞。从内核 5.1 开始,如果调用 splice() 时传入的 pipe 一端是非阻塞的,那么内核就会自动把 SPLICE_F_NONBLOCK 加上,所以也就不需要调用者显式地传入这个 flag 了;但是如果你的内核版本小于 5.1 而且希望 splice() 不阻塞,那么除了将 fd_in/fd_out 提前设置成非阻塞,还必须显式地把 SPLICE_F_NONBLOCK 传给 splice()。Go 语言的官方团队踩过这个坑63,调用 splice() 时去掉了 SPLICE_F_NONBLOCK,导致有一些内核 <5.1 的机器出现 bug,最后我提交了一个 patch 修复了这个问题,修复方法也很简单,就是把 SPLICE_F_NONBLOCK 加回去。
这是我当时给 Go 语言针对这个问题做的分析64:
Actually, I believe that the
SPLICE_F_NONBLOCKflag was removed by mistake.As far as I can tell, the original intent of
SPLICE_F_NONBLOCKadded by Linus Torvalds in this commit was for the flag to affect the buffering, not the endpoints. As you can see in that commit, it took effect after the data transfer, even though it doesn't make the splice itself necessarily nonblocking, but it could, withO_NONBLOCKset in file descriptors.Furthermore, the Linux kernel added
SPLICE_F_NONBLOCKalong withO_NONBLOCKimplicitly since kernel v5.1, to avoid the inconsistent behaviors with pipe file descriptors withO_NONBLOCKinsplice, check out this commit for more details, which means that we don't need to explicitly assignSPLICE_F_NONBLOCKforsplicesince kernel v5.1 while we still have to do it in versions before v5.1.
copy_file_range() & FICLONE & FICLONERANGE
Linux 内核 4.5 引入了一个新的零拷贝系统调用 —— copy_file_range(),主要用于文件系统上的文件之间的数据复制,比如磁盘文件之间的拷贝。这个系统调用可谓是命途多舛,有过一段疯狂的历史65,它在内核 4.5 版本推出,但是那之后爆出了很多 bugs,一直修修补补到 5.3 版本才算真正变成一个生产级别的系统调用。其定义如下66:
#define _GNU_SOURCE
#define _FILE_OFFSET_BITS 64
#include <unistd.h>
ssize_t copy_file_range(int fd_in, off_t *_Nullable off_in,
int fd_out, off_t *_Nullable off_out,
size_t len, unsigned int flags);

这个系统调用支持拷贝文件的某个范围,可以指定要拷贝到目标文件的源文件的偏移量和长度。前文提及的另一个系统调用 sendfile() 也支持类似的功能。与 sendfile() 一样,copy_file_range() 也是一种内核内 (in-kernel) 的复制,数据拷贝的过程中也同样不需要跨越内核态和用户态的边界,因此也是一种零拷贝技术。为什么 Linux 在已经有了 sendfile() 的情况下,还要开发功能类似另一个系统调用 copy_file_range 呢?
首先最直观的就是数据粒度的问题了,从函数签名也能看出来,copy_file_range() 支持指定数据拷贝的时候源文件的起始位置和长度以及目标文件的起始位置和长度 (和源文件的长度一样),而 sendfile() 只能指定源文件的起始位置和长度,之所以是这样是因为 sendfile() 这个系统调用最开始是为了拷贝文件到网络 socket 而创造出来的,所以一开始 out_fd 只支持 socket 类型,内核 2.6.33 版本解除了这个限制,所以从这个版本开始,目标文件可以是任意类型的文件描述符。
其次是 man pages66 上提到的一段话:
copy_file_range()gives filesystems an opportunity to implement “copy acceleration” techniques, such as the use of reflinks (i.e., two or more inodes that share pointers to the same copy-on-write disk blocks) or server-side-copy (in the case of NFS).
这段话具体是什么意思呢?这个要从 copy offload 这件事说起,简单来说,这项技术简单来说就是将数据拷贝从内核继续下沉到硬件设备上,让硬件来完成拷贝,而不需要经过内核 (或者说计算机)。Linux 上的这项工作从十年前开始,现在还在持续开发中67。而在前面介绍的诸多 Linux 零拷贝系统调用中只有 copy_file_range() 提供了这样的支持,目前主要依靠文件系统来实现。我们看看内核中的源码是如何实现的44:
SYSCALL_DEFINE6(copy_file_range, int, fd_in, loff_t __user *, off_in,
int, fd_out, loff_t __user *, off_out,
size_t, len, unsigned int, flags)
{
...
ret = vfs_copy_file_range(f_in.file, pos_in, f_out.file, pos_out, len,
flags);
...
return ret;
}
ssize_t vfs_copy_file_range(struct file *file_in, loff_t pos_in,
struct file *file_out, loff_t pos_out,
size_t len, unsigned int flags)
{
...
// 先尝试使用具体的文件系统提供的 copy_file_range 实现,
// 如果文件系统没有提供这些实现,或者调用的时候出现问题,再
// 或者是跨文件系统的拷贝,那么改用备用方案,使用 splice()
/*
* Cloning is supported by more file systems, so we implement copy on
* same sb using clone, but for filesystems where both clone and copy
* are supported (e.g. nfs,cifs), we only call the copy method.
*/
if (!splice && file_out->f_op->copy_file_range) {
ret = file_out->f_op->copy_file_range(file_in, pos_in,
file_out, pos_out,
len, flags);
} else if (!splice && file_in->f_op->remap_file_range && samesb) {
ret = file_in->f_op->remap_file_range(file_in, pos_in,
file_out, pos_out,
min_t(loff_t, MAX_RW_COUNT, len),
REMAP_FILE_CAN_SHORTEN);
/* fallback to splice */
if (ret <= 0)
splice = true;
} else if (samesb) {
/* Fallback to splice for same sb copy for backward compat */
splice = true;
}
file_end_write(file_out);
if (!splice)
goto done;
// 文件系统没有支持 copy_file_range,使用 splice 完成这次操作。
/*
* We can get here for same sb copy of filesystems that do not implement
* ->copy_file_range() in case filesystem does not support clone or in
* case filesystem supports clone but rejected the clone request (e.g.
* because it was not block aligned).
*
* In both cases, fall back to kernel copy so we are able to maintain a
* consistent story about which filesystems support copy_file_range()
* and which filesystems do not, that will allow userspace tools to
* make consistent desicions w.r.t using copy_file_range().
*
* We also get here if caller (e.g. nfsd) requested COPY_FILE_SPLICE
* for server-side-copy between any two sb.
*
* In any case, we call do_splice_direct() and not splice_file_range(),
* without file_start_write() held, to avoid possible deadlocks related
* to splicing from input file, while file_start_write() is held on
* the output file on a different sb.
*/
ret = do_splice_direct(file_in, &pos_in, file_out, &pos_out,
min_t(size_t, len, MAX_RW_COUNT), 0);
done:
...
return ret;
}
可以看到系统调用的底层实现是 vfs_copy_file_range(),看到这个 vfs_ 开头的函数应该感到很熟悉吧,没错,这又是一个 VFS 的通用函数,这个函数的核心逻辑可以分成两大部分:
- 检查
file_operations的copy_file_range和remap_file_range这两个函数指针,copy_file_range函数指针通常是一般的 data copy (实际复制数据) 实现,remap_file_range则是对copy_file_range()执行了特殊优化的实现 —— data clone ("伪"复制数据,不会实际复制数据,通常只是创建一个引用指向原数据,比如 CoW),这两个函数通常只需要实现其中一个即可,说明该文件系统专门为这个系统调用提供了优化支持,如果是在同一个文件系统上则进行 data clone 而不是 data copy。 - 如果上述的两个函数指针没有实现,或者调用的时候返回了错误,再或者是跨文件系统调用的话,则改用备用方案 ——
splice()完成这次数据拷贝。
这里我们看一下 Btrfs 文件系统是如何支持 copy_file_range() 系统调用的68 69:
const struct file_operations btrfs_file_operations = {
...
.remap_file_range = btrfs_remap_file_range,
.fop_flags = FOP_BUFFER_RASYNC | FOP_BUFFER_WASYNC,
};
loff_t btrfs_remap_file_range(struct file *src_file, loff_t off,
struct file *dst_file, loff_t destoff, loff_t len,
unsigned int remap_flags)
{
...
// 做一些前置工作,主要是检查两个文件的 inodes 是否支持这次拷贝、请求拷贝的数据范围
// 是否合法,比如有没有溢出之类的,最后 flush 现有的脏页。
ret = btrfs_remap_file_range_prep(src_file, off, dst_file, destoff,
&len, remap_flags);
if (ret < 0 || len == 0)
goto out_unlock;
// 这个分支处理 FIDEDUPERANGE
if (remap_flags & REMAP_FILE_DEDUP)
ret = btrfs_extent_same(src_inode, off, len, dst_inode, destoff);
else // 这个分支则是通用的逻辑
ret = btrfs_clone_files(dst_file, src_file, off, len, destoff);
out_unlock:
...
return ret < 0 ? ret : len;
}
这里的核心逻辑主要是 btrfs_clone_files() 这个函数,可以看到其文件名里有一个 clone 的字样,这是和 copy 不一样的概念,要理解 Linux 里的 data clone,要先介绍另外两个系统调用和参数 —— ioctl_ficlone()70 和 ioctl_ficlonerange()70:
#include <linux/fs.h> /* Definition of FICLONE* constants */
#include <sys/ioctl.h>
int ioctl(int dest_fd, FICLONERANGE, struct file_clone_range *arg);
int ioctl(int dest_fd, FICLONE, int src_fd);
主要是 FICLONE 和 FICLONERANGE 这两个 ioctl() 函数的文件参数。这两个参数的主要作用是在那些支持多文件底层硬件设备共享的文件系统上将 src_fd 指向的文件内容通过底层设备共享给 dest_fd 指向的文件。 FICLONE 是共享整个文件,FICLONERANGE 则支持通过指定范围共享一部分文件内容。这个特性主要依赖于文件系统的支持,比如在 Btrfs 中就是通过它的 reflink71 特性来实现的,这个 reflink 的本质就是一种前面介绍过的 CoW (写时复制) 技术,也就是两个文件指向块设备上的同一片数据,当对文件进行读操作的时候访问的也是同一个地址的数据,不会拷贝数据,这样能节省很多存储空间以及提高效率,只有当执行写操作时才会真正地进行数据拷贝。还有另一个 FIDEDUPERANGE72,这个参数和 FICLONERANGE 类似,但两者的使用场景不一样,后者是把一个 src_fd 指向的有内容的文件共享给一个 dest_fd 指向的空文件,这样的话使用 dest_fd 就能直接读 src_fd 里内容了,前者是要求 src_fd 和 dest_fd 中在给定的文件内容范围内的数据是重复,然后执行完系统调用之后就会删除掉重复的数据而只在存储设备上保留一份,二者共享。
再回到 Btrfs 的这个 btrfs_clone_files(),本质上就是利用了和上述技术一样的原理,从内核源码就能看出来73,因为这三个参数在内核中的调用链如下:
FICLONE—>ioctl_file_clone()—>vfs_clone_file_range()—>btrfs_file_operations.remap_file_range()FICLONERANGE—>ioctl_file_clone_range()—>ioctl_file_clone()—>vfs_clone_file_range()—>btrfs_file_operations.remap_file_range()FIDEDUPERANGE—>ioctl_file_dedupe_range()—>vfs_dedupe_file_range()—>vfs_dedupe_file_range_one()—>btrfs_file_operations.remap_file_range()
这系统调用使用的参数最终和 copy_file_range() 殊途同归,都是调用 btrfs_remap_file_range() 这个函数,然后利用 Btrfs 提供的基于 CoW 原理的 reflink 技术实现"伪"复制,也就是共享底层存储的数据。这就是 man pages 里提及具体文件系统的 “copy acceleration” (拷贝加速) 技术。目前已经有不少文件系统已经对 copy_file_range() 做了优化支持74。
总而言之,在那些支持 file cloning (比如 Btrfs 的 reflink 技术和 NFS 的 Server-Side-Copy (如果服务端同时支持 CoW 也会一起应用)) 的文件系统上拷贝磁盘文件的场景,copy_file_range() 和 FICLONE/FICLONERANGE 是最快的,毕竟这几个系统调用在底层实际做的事情本质上就是创建了一个指向原数据的引用,没有真正地拷贝数据,如果文件系统没有针对这个系统调用做优化,那么它就会使用 splice() 拷贝数据,此时就和 sendfile() 没有什么区别了。copy_file_range() 在内核 5.3 版本65 开始支持跨文件系统拷贝数据,底层是通过 splice() 实现的,但是发布之后出现了不少 bugs,因此从 5.19 版本66 开始就追加了一个限制:只支持同类型的文件系统之间的文件数据拷贝。
send() with MSG_ZEROCOPY
Linux 内核在 2017 年的 v4.14 版本引入了来自 Google 工程师 Willem de Bruijn 实现的 MSG_ZEROCOPY 特性,支持以零拷贝的方式将用户空间的数据发送给 TCP socket75。利用这个新功能,用户进程就能够把用户缓冲区的数据通过零拷贝的方式经过内核空间发送到网络套接字中去,这个新技术和前文介绍的几种零拷贝方式相比更加先进,因为前面几种零拷贝技术都是要求用户进程不能处理加工数据而是直接转发到目标文件描述符中去的。
Willem de Bruijn 在他的论文里给出的压测数据是:采用 netperf 大包发送测试,性能提升 39%,而线上环境的数据发送性能则提升了 5%~8%,官方文档陈述说这个特性通常只在发送 10KB 左右大包的场景下才会有显著的性能提升。一开始这个特性只支持 TCP,到内核 v5.0 版本之后才支持 UDP。
这个功能的使用模式如下76:
if (setsockopt(socket_fd, SOL_SOCKET, SO_ZEROCOPY, &one, sizeof(one)))
error(1, errno, "setsockopt zerocopy");
ret = send(socket_fd, buffer, sizeof(buffer), MSG_ZEROCOPY);
首先第一步,先给要发送数据的 socket 设置一个 SOCK_ZEROCOPY option,然后在调用 send() 发送数据时再设置一个 MSG_ZEROCOPY option,其实理论上来说只需要调用 setsockopt() 或者 send() 时传递这个 zero-copy 的 option 即可,两者选其一,但是这里却要设置同一个 option 两次,官方的说法是为了兼容 send() API 以前的设计上的一个错误:send() 以前的实现会忽略掉未知的 option,为了兼容那些可能已经不小心设置了 MSG_ZEROCOPY option 的程序,故而设计成了两步设置。不过我猜还有一种可能:就是给使用者提供更灵活的使用模式,因为这个新功能只在大包场景下才可能会有显著的性能提升,但是现实场景是很复杂的,不仅仅是全部大包或者全部小包的场景,有可能是大包小包混合的场景,因此使用者可以先调用 setsockopt() 设置 SOCK_ZEROCOPY option,然后再根据实际业务场景中的网络包尺寸选择是否要在调用 send() 时使用 MSG_ZEROCOPY 进行 zero-copy 传输。
因为 send() 可能是异步发送数据,因此使用 MSG_ZEROCOPY 有一个需要特别注意的点是:调用 send() 之后不能立刻重用或释放 buffer,因为 buffer 中的数据不一定已经被内核读走了,所以还需要从 socket 关联的错误队列里读取一下通知消息,看看 buffer 中的数据是否已经被内核读走了76:
pfd.fd = fd;
pfd.events = 0;
if (poll(&pfd, 1, -1) != 1 || pfd.revents & POLLERR == 0)
error(1, errno, "poll");
ret = recvmsg(fd, &msg, MSG_ERRQUEUE);
if (ret == -1)
error(1, errno, "recvmsg");
read_notification(msg);
uint32_t read_notification(struct msghdr *msg)
{
struct sock_extended_err *serr;
struct cmsghdr *cm;
cm = CMSG_FIRSTHDR(msg);
if (cm->cmsg_level != SOL_IP &&
cm->cmsg_type != IP_RECVERR)
error(1, 0, "cmsg");
serr = (void *) CMSG_DATA(cm);
if (serr->ee_errno != 0 ||
serr->ee_origin != SO_EE_ORIGIN_ZEROCOPY)
error(1, 0, "serr");
return serr->ee _ data;
}
这个技术是基于 redhat 红帽在 2010 年给 Linux 内核提交的 virtio-net zero-copy 技术之上实现的,至于底层原理,简单来说就是通过 send() 把数据在用户缓冲区中的分段指针发送到 socket 中去,利用 page pinning 页锁定机制锁住用户缓冲区的内存页,然后利用 DMA 直接在用户缓冲区通过内存地址指针进行数据读取,实现零拷贝;具体的细节可以通过阅读 Willem de Bruijn 的论文深入了解。
目前来说,这种技术的主要缺陷有:
- 只适用于大文件 (10KB 左右) 的场景,小文件场景因为 page pinning 页锁定和等待缓冲区释放的通知消息这些机制,甚至可能比直接 CPU 拷贝更耗时;
- 因为可能异步发送数据,需要额外调用
poll()和recvmsg()系统调用等待 buffer 被释放的通知消息,增加代码复杂度,以及会导致多次用户态和内核态的上下文切换; - MSG_ZEROCOPY 目前只支持发送端,接收端暂不支持。
绕过内核的直接 I/O (Direct I/O)
可以看出,前面种种的 zero-copy 的方法,都是在想方设法地优化减少或者去掉用户态和内核态之间以及内核态和内核态之间的数据拷贝,为了实现避免这些拷贝可谓是八仙过海,各显神通,采用了各种各样的手段,那么如果我们换个思路:其实这么费劲地去消除这些拷贝不就是因为有内核在掺和吗?如果我们绕过内核直接进行 I/O 不就没有这些烦人的拷贝问题了吗?这就是绕过内核直接 I/O 技术:
这种方案有两种实现方式:
- 用户直接访问硬件
- 内核控制访问硬件
用户直接访问硬件
这种技术赋予用户进程直接访问硬件设备的权限,这让用户进程能有直接读写硬件设备,在数据传输过程中只需要内核做一些虚拟内存配置相关的工作。这种无需数据拷贝和内核干预的直接 I/O,理论上是最高效的数据传输技术,但是正如前面所说的那样,并不存在能解决一切问题的银弹,这种直接 I/O 技术虽然有可能非常高效,但是它的适用性也非常窄,目前只适用于诸如 MPI 高性能通信、丛集计算系统中的远程共享内存等有限的场景。
这种技术实际上破坏了现代计算机操作系统最重要的概念之一 —— 硬件抽象,我们之前提过,抽象是计算机领域最最核心的设计思路,正式由于有了抽象和分层,各个层级才能不必去关心很多底层细节从而专注于真正的工作,才使得系统的运作更加高效和快速。此外,网卡通常使用功能较弱的 CPU,例如只包含简单指令集的 MIPS 架构处理器 (没有不必要的功能,如浮点数计算等) ,也没有太多的内存来容纳复杂的软件。因此,通常只有那些基于以太网之上的专用协议会使用这种技术,这些专用协议的设计要比远比 TCP/IP 简单得多,而且多用于局域网环境中,在这种环境中,数据包丢失和损坏很少发生,因此没有必要进行复杂的数据包确认和流量控制机制。而且这种技术还需要定制的网卡,所以它是高度依赖硬件的。
与传统的通信设计相比,直接硬件访问技术给程序设计带来了各种限制:由于设备之间的数据传输是通过 DMA 完成的,因此用户空间的数据缓冲区内存页必须进行 page pinning (页锁定) ,这是为了防止其物理页框地址被交换到磁盘或者被移动到新的地址而导致 DMA 去拷贝数据的时候在指定的地址找不到内存页从而引发缺页错误,而页锁定的开销并不比 CPU 拷贝小,所以为了避免频繁的页锁定系统调用,应用程序必须分配和注册一个持久的内存池,用于数据缓冲。
用户直接访问硬件的技术可以得到极高的 I/O 性能,但是其应用领域和适用场景也极其的有限,如集群或网络存储系统中的节点通信。它需要定制的硬件和专门设计的应用程序,但相应地对操作系统内核的改动比较小,可以很容易地以内核模块或设备驱动程序的形式实现出来。直接访问硬件还可能会带来严重的安全问题,因为用户进程拥有直接访问硬件的极高权限,所以如果你的程序设计没有做好的话,可能会消耗本来就有限的硬件资源或者进行非法地址访问,可能也会因此间接地影响其他正在使用同一设备的应用程序,而因为绕开了内核,所以也无法让内核替你去控制和管理。
内核控制访问硬件
相较于用户直接访问硬件技术,通过内核控制的直接访问硬件技术更加的安全,它比前者在数据传输过程中会多干预一点,但也仅仅是作为一个代理人这样的角色,不会参与到实际的数据传输过程,内核会控制 DMA 引擎去替用户进程做缓冲区的数据传输工作。同样的,这种方式也是高度依赖硬件的,比如一些集成了专有网络栈协议的网卡。这种技术的一个优势就是用户集成去 I/O 时的接口不会改变,就和普通的 read()/write() 系统调用那样使用即可,所有的脏活累活都在内核里完成,用户接口友好度很高,不过需要注意的是,使用这种技术的过程中如果发生了什么不可预知的意外从而导致无法使用这种技术进行数据传输的话,则内核会自动切换为最传统 I/O 模式,也就是性能最差的那种模式。
这种技术也有着和用户直接访问硬件技术一样的问题:DMA 传输数据的过程中,用户进程的缓冲区内存页必须进行 page pinning 页锁定,数据传输完成后才能解锁。CPU 高速缓存内保存的多个内存地址也会被冲刷掉以保证 DMA 传输前后的数据一致性。这些机制有可能会导致数据传输的性能变得更差,因为 read()/write() 系统调用的语义并不能提前通知 CPU 用户缓冲区要参与 DMA 数据传输传输,因此也就无法像内核缓冲区那样可依提前加载进高速缓存,提高性能。由于用户缓冲区的内存页可能分布在物理内存中的任意位置,因此一些实现不好的 DMA 控制器引擎可能会有寻址限制从而导致无法访问这些内存区域。一些技术比如 AMD64 架构中的 IOMMU,允许通过将 DMA 地址重新映射到内存中的物理地址来解决这些限制,但反过来又可能会导致可移植性问题,因为其他的处理器架构,甚至是 Intel 64 位 x86 架构的变种 EM64T 都不具备这样的特性单元。此外,还可能存在其他限制,比如 DMA 传输的数据对齐问题,又会导致无法访问用户进程指定的任意缓冲区内存地址。
Linux O_DIRECT
Linux 在 open() 系统调用上提供了 O_DIRECT 文件标志,通过它为上层用户程序提供 Direct I/O,绕过 page cache 直接和块设备交互。这样就能规避掉用户空间和内核空间之间的数据拷贝,用户空间的内存数据直接写入磁盘,磁盘的数据也可以直接读到用户空间的内存中。这样的话,也就不需要内核里的一些复杂的内存管理机制如 readahead 和 writeback 等。
使用 Linux 的 O_DIRECT 要注意以下事项:
- 对使用了
O_DIRECT打开的文件进行写操作虽然是绕过 page cache 直达磁盘的同步 I/O,但在内核层面并不会自动保证write()系统调用返回后数据就一定存入了磁盘,因此用open()系统调用打开文件的时候指定O_DIRECT的同时通常也要指定O_SYNC以保证可靠性。 - 如果使用了
mmap()而且指定了MAP_PRIVATE,而且需要调用fork()创建多进程的话,那么O_DIRECTI/O 禁止在多进程间使用,否则的话可能会导致数据污染以及出现未知的问题。如果父进程使用了O_DIRECT,那么在调用fork()前一定要完成所有O_DIRECTI/O 操作。(使用MAP_SHARED的mmap()和shmat()则没有这个限制) O_DIRECT需要文件系统的支持,有一些文件系统不支持 Direct I/O,这种情况下,调用open()时指定O_DIRECT就会返回EINVAL错误。- 对同一文件不要混合使用 Direct I/O 和 Buffered I/O,不然很容易出现数据不一致的问题,就算有一些文件系统解决了这种场景下的数据一致性问题,这种使用方式大概率也会导致性能大幅下降。同理,也不要混合
mmap()和O_DIRECT一起使用。 - 使用
O_DIRECT的过程中需要用户程序自己进行块对齐 (见下一节),如果用户程序不处理块对齐的话,根据不同内核版本和不同文件系统的实现,write()要么返回EINVAL错误,要么切换回 Buffered I/O。
总而言之,Linux 的 O_DIRECT 是一个应该谨慎使用的特性,用对了就是一个提升性能的强大工具,如果用不好,则会有各种各样的问题。
Direct I/O 限制
使用 Direct I/O 最麻烦的一个地方就是块对齐 (block alignment)。对于块设备来说,在上面读写数据的一个最佳实践就是块对齐:也就是数据分布要按照块大小对齐,磁盘管理存储的最小单位是块,所以块对齐能让磁盘更好管理数据和执行 I/O。
这是一个块不对齐的例子77 (注意,图中的灰色的 Page 页其实是代表 Block 块,每一个绿色的方框代表(机械硬盘上的)一个扇区):

这是一个块对齐的例子77:

区别就在于前者的数据分布跨越了磁盘块,因为磁盘的最小读写单位是块,跨块的数据读写本来只需要一次 I/O,现在变成了两次,如果这样的块不对齐的情况越来越多,最终就会导致磁盘上的数据分布很混乱,而且很多容量比较小的块之间空白扇区就可能会被浪费掉,导致存储利用率也变低了。因此,块设备会要求其使用者在读写数据的时候进行块对齐,如果数据没有对齐,如上面的第一张图,现在我要更新这一片数据,就会触发一次 RMW (Read-Modify-Write) 流程:先把数据所在这两个块都读出来,剔除掉不需要的部分 (图中的 56 ~ 62 范围的扇区),更新数据,然后写回到块设备。这个操作非常耗时,会导致 I/O 性能下降最高 25 倍77。因此,在块设备上执行 I/O 时必须要进行块对齐。这个原理对于 SSD 硬盘来说也是一样的,HDD 最小的数据存储单位是 sector (扇区),多个 sectors 组成其最小的数据操作单位 block (块),而 SSD 最小的数据存储单位是 page (页),多个 pages 组成其最小的数据操作单位 block (块)。读写 SSD 时如果不进行块大小对齐的话,同样会触发 RMW 从而导致性能下降。
对于 Buffered I/O 来说,用户程序不需要操心块对齐的问题。因为 page cache 层会自动地把用户程序的 I/O 数据进行对齐之后才发送到块设备上去处理。但是如果使用 Direct I/O 的话,则需要用户程序自己处理块对齐的问题。
Direct I/O 的使用场景
对于绝大部分应用来说,绝大多数时候都不要使用 Direct I/O,因为切换成 Direct I/O 之后不仅会使得程序更加复杂,而且大概率会导致性能下降,大部分上层应用应该基于 Buffered I/O 这种通用性最强的 I/O 模式才能有最好的表现。Direct I/O 的应用场景比较窄,通常更适合那些有自己独立的缓存层的系统,比如数据库,这就是一个很典型的使用 Direct I/O 的场景。
对于数据库系统来说,Linux 的 page cache 层在很多时候不仅没有帮助其发挥出最大的 I/O 性能,反而拖累了数据库。比如,Linux 默认使用 4KB 的页作为 page cache 的最小 I/O 单位,但是数据库很多时候都需要管理一些小于 4KB 的数据,也就是说就算要读一块远小于 4KB 的数据,在 page cache 中也必须用一个 page 来存,这对于数据库来说就是一个很大的成本。另外,数据库一般都会有自研的缓存层,而且是专门针对本数据的使用场景而优化的,因此这个自研的缓存层肯定要比 Linux 那种通用的 page cache 在管理数据库的数据上更加的有针对性从而能做到更好的优化,这个时候,如果还开启 page cache,那么就相当于有上下两个缓存层,在数据库和磁盘之间又多了一层数据拷贝,性能肯定更加差,因此对于数据库系统来说,Direct I/O 是一个绝佳的操作系统特性。有很多数据库都应用了 Direct I/O:MySQL78、PostgreSQL79 80、RocksDB81、ScyllaDB82 等等。
虽然 Linux 提供了 O_DIRECT 这样的 Direct I/O 实现,但是 Linus 本人却很不喜欢这个特性。他在 Linux kernel 的 mailing list 中吐槽过这个特性83:
The thing that has always disturbed me about O_DIRECT is that the whole
interface is just stupid, and was probably designed by a deranged monkey
on some serious mind-controlling substances.— Linus Torvalds
这话说的还有点难听,把 O_DIRECT 的作者也一起骂了...,他后来还就 Linux 的异步 I/O 框架 AIO 方面的问题吐槽过"数据库开发者都没什么品味"84:
So I think this is ridiculously ugly.
AIO is a horrible ad-hoc design, with the main excuse being "other,
less gifted people, made that design, and we are implementing it for
compatibility because database people - who seldom have any shred of
taste - actually use it".But AIO was always really really ugly.
— Linus Torvalds
而之前的 O_DIRECT 也是数据库开发者用得最多,看来 Linus 对这个群体还真是颇有微词。
内核态和用户态之间的传输优化
到目前为止,我们讨论的 zero-copy 技术都是基于减少甚至是避免用户空间和内核空间之间的 CPU 数据拷贝的,虽然有一些技术非常高效,但是大多都有适用性很窄的问题,比如 sendfile()、splice() 这些,效率很高,但是都只适用于那些用户进程不需要直接处理数据的场景,比如静态文件服务器或者是直接转发数据的代理服务器。
现在我们已经知道,硬件设备之间的数据可以通过 DMA 进行传输,然而却并没有这样的传输机制可以应用于用户缓冲区和内核缓冲区之间的数据传输。不过另一方面,广泛应用在现代的 CPU 架构和操作系统上的虚拟内存机制表明,通过在不同的虚拟地址上重新映射页面可以实现在用户进程和内核之间虚拟复制和共享内存,尽管一次传输的内存颗粒度相对较大:4KB 或 8KB。
因此如果要在实现在用户进程内处理数据 (这种场景比直接转发数据更加常见) 之后再发送出去的话,用户空间和内核空间的数据传输就是不可避免的,既然避无可避,那就只能选择优化了,因此本章节我们要介绍两种优化用户空间和内核空间数据传输的技术:
- 动态重映射与写时拷贝 (Copy-on-Write)
- 缓冲区共享 (Buffer Sharing)
动态重映射与写时拷贝 (Copy-on-Write)
前面我们介绍过利用内存映射技术 mmap 来减少数据在用户空间和内核空间之间的复制,通常简单模式下,用户进程是对共享的缓冲区进行同步阻塞读写的,这样不会有 data race 问题,但是这种模式下效率并不高,而提升效率的一种方法就是异步地对共享缓冲区进行读写,而这样的话就必须引入保护机制来避免数据冲突问题,写时复制 (CoW, Copy-on-Write) 就是这样的一种技术。
写入时复制 (Copy-on-write,CoW) 是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者 (callers) 同时请求相同资源 (如内存或磁盘上的数据存储) ,他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本 (private copy) 给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本 (private copy) 被创建,因此多个调用者只是读取操作时可以共享同一份资源。
举一个例子,引入了 CoW 技术之后,用户进程读取磁盘文件进行数据处理最后写到网卡,首先使用内存映射技术 mmap() 让用户缓冲区和内核缓冲区共享了一段内存地址并标记为只读 (read-only),避免数据拷贝,而当要把数据写到网卡的时候,用户进程选择了异步写的方式,系统调用会直接返回,数据传输就会在内核里异步进行,而用户进程就可以继续其他的工作,并且共享缓冲区的内容可以随时再进行读取,效率很高,但是如果该进程又尝试往共享缓冲区写入数据,则会产生一个 CoW 事件,让试图写入数据的进程把数据复制到自己的缓冲区去修改,这里只需要复制要修改的内存页即可,无需所有数据都复制过去,而如果其他访问该共享内存的进程不需要修改数据则可以永远不需要进行数据拷贝。
CoW 是一种建构在虚拟内存重映射技术之上的技术,因此它需要 MMU 的硬件支持,MMU 会记录当前哪些内存页被标记成只读,当有进程尝试往这些内存页中写数据的时候,MMU 就会抛一个异常给操作系统内核,内核处理该异常时为该进程分配一份物理内存并复制数据到此内存地址,重新向 MMU 发出执行该进程的写操作。
CoW 最大的优势是节省内存和减少数据拷贝,不过却是通过增加操作系统内核 I/O 过程复杂性作为代价的。当确定采用 CoW 来复制页面时,重要的是注意空闲页面的分配位置。许多操作系统为这类请求提供了一个空闲的页面池。当进程的堆栈或堆要扩展时或有写时复制页面需要管理时,通常分配这些空闲页面。操作系统分配这些页面通常采用称为按需填零的技术。按需填零页面在需要分配之前先填零,因此会清除里面旧的内容。
局限性:
CoW 这种零拷贝技术比较适用于那种多读少写从而使得 CoW 事件发生较少的场景,因为 CoW 事件所带来的系统开销要远远高于一次 CPU 拷贝所产生的。此外,在实际应用的过程中,为了避免频繁的内存映射,可以重复使用同一段内存缓冲区,因此,你不需要在只用过一次共享缓冲区之后就解除掉内存页的映射关系,而是重复循环使用,从而提升性能,不过这种内存页映射的持久化并不会减少由于页表往返移动和 TLB 冲刷所带来的系统开销,因为每次接收到 CoW 事件之后对内存页而进行加锁或者解锁的时候,页面的只读标志 (read-ony) 都要被更改为 (write-only)。
缓冲区共享 (Buffer Sharing)
从前面的介绍可以看出,传统的 Linux I/O接口,都是基于数据拷贝的:数据需要在操作系统内核空间和用户空间的缓冲区之间进行拷贝。在进行 I/O 操作之前,用户进程需要预先分配好一个内存缓冲区,使用 read() 系统调用时,内核会将从存储设备或者网卡等设备读入的数据拷贝到这个用户缓冲区里;而使用 write() 系统调用时,则是把用户内存缓冲区的数据拷贝至内核缓冲区。
为了实现这种传统的 I/O 模式,Linux 必须要在每一个 I/O 操作时都进行内存虚拟映射和解除。这种内存页重映射的机制的效率严重受限于缓存体系结构、MMU 地址转换速度和 TLB 命中率。如果能够避免处理 I/O 请求的虚拟地址转换和 TLB 刷新所带来的开销,则有可能极大地提升 I/O 性能。而缓冲区共享就是用来解决上述问题的一种技术。
fbufs 就是一种在上世纪九十年代提出的 buffer sharing 的框架85,全称是快速缓冲区 (Fast Buffers),在提出来之后没两年之后,Solaris 操作系统就率先开发实现了 fbufs86。后来,Linux 上也开始有一些 buffer sharing 实验性的项目,然而可惜的是时至今日依然还是停留在实验阶段。
fbufs 框架使用一个 fbuf 缓冲区作为数据传输的最小单位,使用这种技术需要调用新的操作系统 API (系统调用),用户空间与内核空间之间以及内核空间与内核空间之间的数据都必须严格地在 fbufs 这个体系下进行通信。fbufs 为每一个用户进程分配一个 buffer pool,里面会储存预分配 (也可以使用的时候再分配) 好的 buffers,这些 buffers 会被同时映射到用户内存空间和内核内存空间。fbufs 只需通过一次虚拟内存映射操作即可创建缓冲区,有效地消除那些由存储一致性维护所引发的大多数性能损耗。
传统的 Linux I/O 接口是通过把数据在用户缓冲区和内核缓冲区之间进行拷贝传输来完成的,这种数据传输过程中需要进行大量的数据拷贝,同时由于虚拟内存技术的存在,I/O 过程中还需要频繁地通过 MMU 进行虚拟内存地址到物理内存地址的转换,高速缓存的汰换以及 TLB 的刷新,这些操作均会导致性能的损耗。而如果利用 fbufs 框架来实现数据传输的话,首先可以把 buffers 都缓存到 pool 里循环利用,而不需要每次都去重新分配,而且缓存下来的不止有 buffers 本身,而且还会把虚拟内存地址到物理内存地址的映射关系也缓存下来,也就可以避免每次都进行地址转换,从发送接收数据的层面来说,用户进程和 I/O 子系统比如设备驱动程序、网卡等可以直接传输整个缓冲区本身而不是其中的数据内容,也可以理解成是传输内存地址指针,这样就就避免了大量的数据内容拷贝:用户进程/ IO 子系统通过发送一个个的 fbuf 写出数据到内核而非直接传递数据内容,相对应的,用户进程/ IO 子系统通过接收一个个的 fbuf 而从内核读入数据,这样就能减少传统的 read()/write() 系统调用带来的数据拷贝开销:
- 发送方用户进程调用
uf_allocate从自己的 buffer pool 获取一个fbuf缓冲区,往其中填充内容之后调用uf_write向内核区发送指向fbuf的文件描述符; - I/O 子系统接收到
fbuf之后,调用uf_allocb从接收方用户进程的 buffer pool 获取一个fubf并用接收到的数据进行填充,然后向用户区发送指向fbuf的文件描述符; - 接收方用户进程调用
uf_get接收到 fbuf,读取数据进行处理,完成之后调用uf_deallocate把fbuf放回自己的 buffer pool。
fbufs 的缺陷
共享缓冲区技术的实现需要依赖于用户进程、操作系统内核、以及 I/O 子系统 (设备驱动程序,文件系统等)之间协同工作。比如,设计得不好的用户进程容易就会修改已经发送出去的 fbuf 从而污染数据,更要命的是这种问题很难 debug。虽然这个技术的设计方案非常精彩,但是它的门槛和限制却不比前面介绍的其他技术少:首先会对操作系统 API 造成变动,需要使用新的一些 API 调用,其次还需要设备驱动程序配合改动,还有由于是内存共享,内核需要很小心谨慎地实现对这部分共享的内存进行数据保护和同步的机制,而这种并发的同步机制是非常容易出 bug 的从而又增加了内核的代码复杂度,等等。因此这一类的技术还远远没有到发展成熟和广泛应用的阶段,目前大多数的实现都还处于实验阶段。
I/O 多路复用和异步 I/O (epoll & io_uring)
Linux I/O 技术中还有两个非常重要的部分:I/O 多路复用和异步 I/O。
I/O 多路复用主要是以 epoll 为代表的几个在 Linux 现代网络服务器中占据统治地位的技术,除此之外还有 select 和 poll,但是这两个技术已经比较陈旧了,现在应该只有一些非常老旧的平台和代码还在使用,所以 epoll 就代表了 Linux 的 I/O 多路复用技术。
AIO 在内核 2.5 中首次实现,在内核 5.1 之前一直作为 Linux 平台上唯一的异步 I/O 框架。从一推出就因为其底层设计的简陋和及其不友好的 API 而一直备受批评,更糟糕的是 AIO 还只能在 Direct I/O 下使用,也就是 page cache 的优势在 AIO 程序中就荡然无存了。前面我也讲过,连 Linus 本人都不喜欢这个异步 I/O 框架,认为这个框架的设计实在是"非常丑陋"。
而 io_uring 作为内核 5.15 新进推出的异步 I/O 框架87,作为 AIO 的继任者,目前的发展可以说是炙手可热,取代 AIO 成为 Linux 的异步 I/O 标准基本上是板上钉钉的事了。
io_uring 的基本结构如下所示31:
AIO 作为一个从诞生起就饱受批判的技术,在我看来对于我们现如今学习 Linux I/O 技术已经没有多大的价值了,不过很多数据库程序员还暂时无法摆脱它,毕竟在 io_uring 出来之前,Linux 平台上的异步 I/O 框架就只有一个选择,所以很多数据库代码里还遗留了很多 AIO 相关的代码,不过我想短期内数据库开发者可能也没有太大的动力去把 AIO 的代码替换成 io_uring,这是因为 AIO 和 io_uring 的底层原理其实没有本质的区别:二者的核心原理都是共享内存、异步提交、轮询结果等技术,所以就算替换了也基本没有太大的性能提升。
io_uring 相比 AIO 更加重要贡献还是在于提供了更规范和友好的 API 以及把异步 I/O 的应用范围从数据库 (文件 I/O) 扩大到所有场景 (比如网络 I/O 等),所以对于非数据库从业者而言 AIO 真的没有太多深入研究的价值了,io_uring 现在是大势所趋,不出意外的话 Linux 未来的异步 I/O 标准就是它了,io_uring 通过 mmap() 让用户空间和内核空间共享 "提交队列" Submission Queue (SQ)、"完成队列" Completion Queue (CQ) 和 "提交队列条目数组" Submission Queue Entry (SQE) array,因此理论上也可以算作"零拷贝"技术,我希望能为这篇文章补上 io_uring 的这部分内容以及 I/O 多路复用 (同步非阻塞+事件驱动) 的代表 epoll 方面的内容。
但是这篇文章已经写了太长太长了,到目前为止已经超过了七万字,实在不适合再把 epoll 和 io_uring 这两个重磅炸弹加进来搅局,因此,epoll 和 io_uring 的方面的文章将分别独立成篇。敬请期待!
总结
本文开头的一个小篇幅先介绍了一点计算机硬件相关的知识以及虚拟内存的基本原理,这个篇幅虽然不多但是对于我们后续理解计算的分层存储体系结构及其重要,正是因为计算存储硬件的成本不同,才促成了现代计算机存储体系从上到下分层金字塔型的层次结构。
接下来是本文两大核心组成的第一部分,这里我剖析了整个 Linux I/O 栈,同时也展示了 Linux I/O 优化和改造的演进历程,勾勒出了 Linux I/O 栈从上到下的层次结构,这些不同的 Linux I/O 栈层是:
- 虚拟文件系统层
- Page Cache 层
- 映射层
- 通用块层
- I/O 调度层
- 块设备驱动层
- 块设备硬件层
每一层我们都进行了深入浅出地通过原理分析结合源码解读进行解析,理论结合实践,第一部分的最后一章通过内核源码的解读对 Linux I/O 栈的执行过程进行了揭秘,使读者能够切实地深入了解内核的具体实现细节,加深对 Linux I/O 栈的理解。
紧接着我介绍了 Linux 等操作系统中的三大基本 I/O 模式:
- 程序控制 I/O
- 中断驱动 I/O
- DMA I/O
让读者能切实地感受到用户程序中一个简单的 I/O 操作,在操作系统层面和硬件层面是如何运转和工作的。最后介绍了一下 Linux 中的通用 I/O 流程,涉及了多少次 CPU 拷贝、多少次 DMA 拷贝,结合三大 I/O 模式,为下文的零拷贝 (Zero-Copy) 技术做铺垫。
第二部分则是介绍并解析了 Linux 中一系列的 Zero Copy (零拷贝) 技术,这些技术在现在的 Linux 服务端应用中被广泛地使用,用以降低 I/O 成本,提升系统性能,可以说是 Linux I/O 技术栈在现实世界中的基石,这一部分我们同样是通过原理结合源码进行分析,不仅对 Linux I/O 零拷贝技术的现状进行了全面而详实的介绍,也通过一步一步地引导,最后还能给出 Linux 对 I/O 模块的优化和改进思路。
Linux 的 Zero Copy 技术可以归纳成以下三大类:
- 减少甚至避免用户空间和内核空间之间的数据拷贝:在一些场景下,用户进程在数据传输过程中并不需要对数据进行访问和处理,那么数据在 Linux 的
Page Cache和用户进程的缓冲区之间的传输就完全可以避免,让数据拷贝完全在内核里进行,甚至可以通过更巧妙的方式避免在内核里的数据拷贝。这一类实现一般是通过增加新的系统调用来完成的,比如 Linux 中的mmap()、sendfile()、splice()和copy_file_range()等等。这一类的零拷贝技术是应用层开发中最广泛使用的。 - 绕过内核的直接 I/O:允许在用户态进程绕过内核直接和硬件进行数据传输,内核在传输过程中只负责一些管理和辅助的工作。这种方式其实和第一种有点类似,也是试图避免用户空间和内核空间之间的数据传输,只是第一种方式是把数据传输过程放在内核态完成,而这种方式则是直接绕过内核和硬件通信,效果类似但原理完全不同。
- 内核缓冲区和用户缓冲区之间的传输优化:这种方式侧重于在用户进程的缓冲区和操作系统的页缓存之间的 CPU 拷贝的优化。这种方法延续了以往那种传统的通信方式,但更灵活。
希望通过这篇文章,读者们不仅能了解 Linux I/O 栈的设计与实现,而且还能从 Linux 的这些设计和实现,以及如此长时间的对 I/O 系统的优化和改进的思路和手段中学习到这些业界最顶尖的智慧和经验,对以后的工作中设计上层的业务系统或者底层框架过程中能有所启发和借鉴。
参考 & 延伸
- Linux Kernel Development, Third Edition
- Understanding the Linux Kernel, Third Edition
- INTRODUCTION TO THE LINUX VIRTUAL FILESYSTEM (VFS): A HIGH-LEVEL TOUR
- The future of the page cache
- I/O scheduling for single-queue devices
- Linux Block IO—present and future
- The block I/O layer I/O schedulers
- Linux I/O schedulers
- Linux block subsystem
- CPU cache
- Virtual Address Aliasing
- Zero Copy I: User-Mode Perspective
- Message Passing for Gigabit/s Networks with “Zero-Copy” under Linux
- Speculative Defragmentation – Leading Gigabit Ethernet to True Zero-Copy Communication
- ZeroCopy: Techniques, Benefits and Pitfalls
- Driver porting: Zero-copy user-space access
- It’s all about buffers: zero-copy, mmap and Java NIO
- Linux Zero Copy
- Circular pipes
- Provide a zero-copy method on KVM virtio-net
- Efficient data/file copying on modern Linux
- 数字存储完全指南 03 :固态硬盘的历史、结构与原理
- 了解 SSD 技术:NVMe、SATA、M.2
Footnotes
-
W4118 Operating Systems Interrupt and System Call in Linux Instructor ↩
-
Host managed contention avoidance storage solutions for Big Data ↩ ↩2
-
An Introduction to the Linux Kernel Block I/O Stack - Based on Linux 5.11 ↩ ↩2
-
Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems ↩ ↩2 ↩3 ↩4 ↩5
-
BFQ, Multiqueue-Deadline, or Kyber? Performance Characterization of Linux Storage Schedulers in the NVMe Era ↩
-
Linux —— src/arch/m68k/include/asm/cacheflush_mm.h:__flush_pages_to_ram() ↩
-
net: TCPConn.ReadFrom hangs when io.Reader is TCPConn or UnixConn, Linux kernel < 5.1 ↩
-
net: copy from Unix socket to os.Stdout fails with "waiting for unsupported file type" ↩