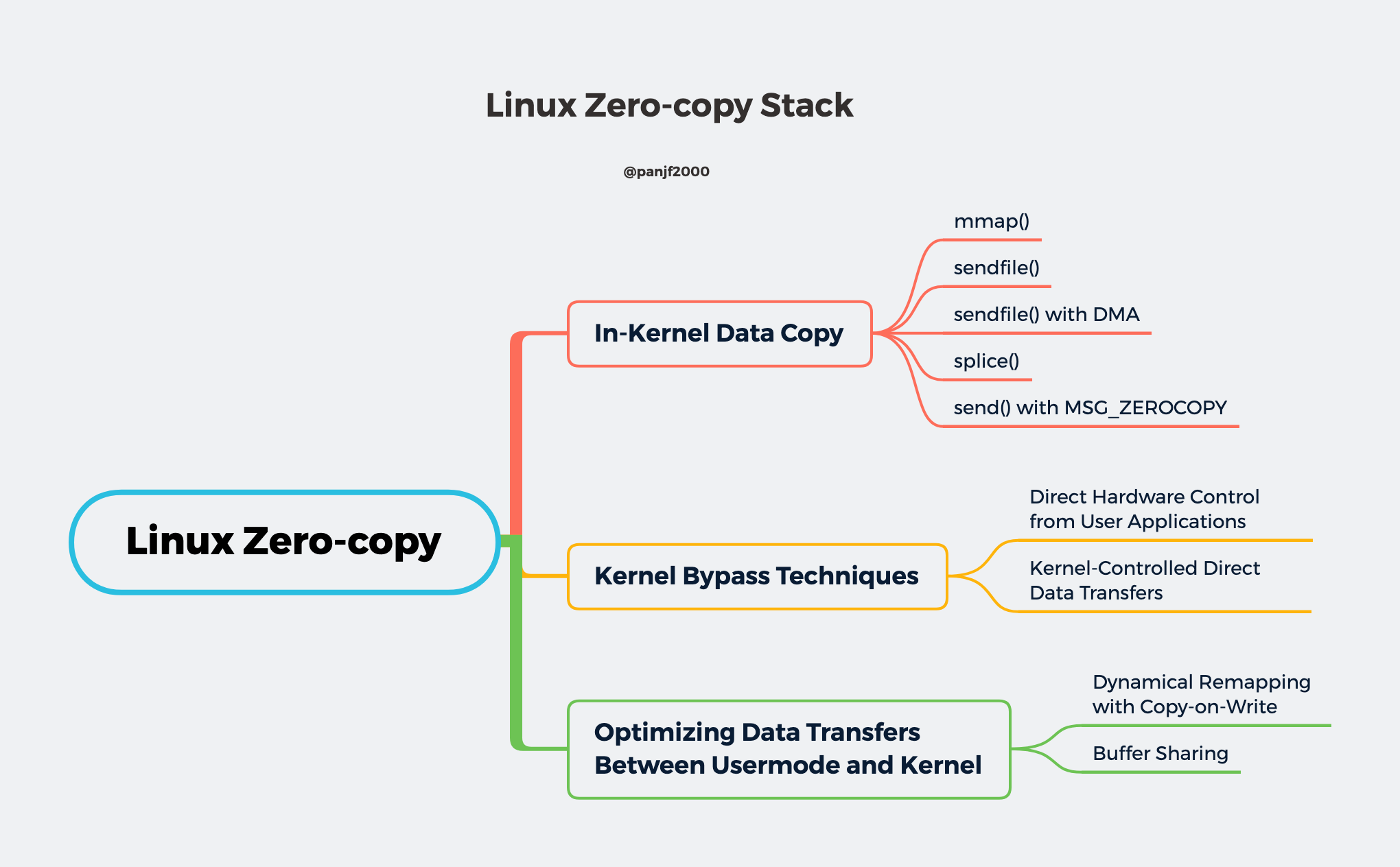
Linux I/O 栈与零拷贝技术全揭秘
从理论和源码层面全面而深入地剖析 Linux I/O 栈和零拷贝技术
从理论和源码层面全面而深入地剖析 Linux I/O 栈和零拷贝技术
全面解读 Linux 内核的调度器设计与实现,内容涵盖 O(1) 调度器、CFS 调度器以及最新一代的 EEVDF 调度器的论文导读、理论基础和代码实现。

全面而深入地剖析 Linux epoll 的 LT 和 ET 模式
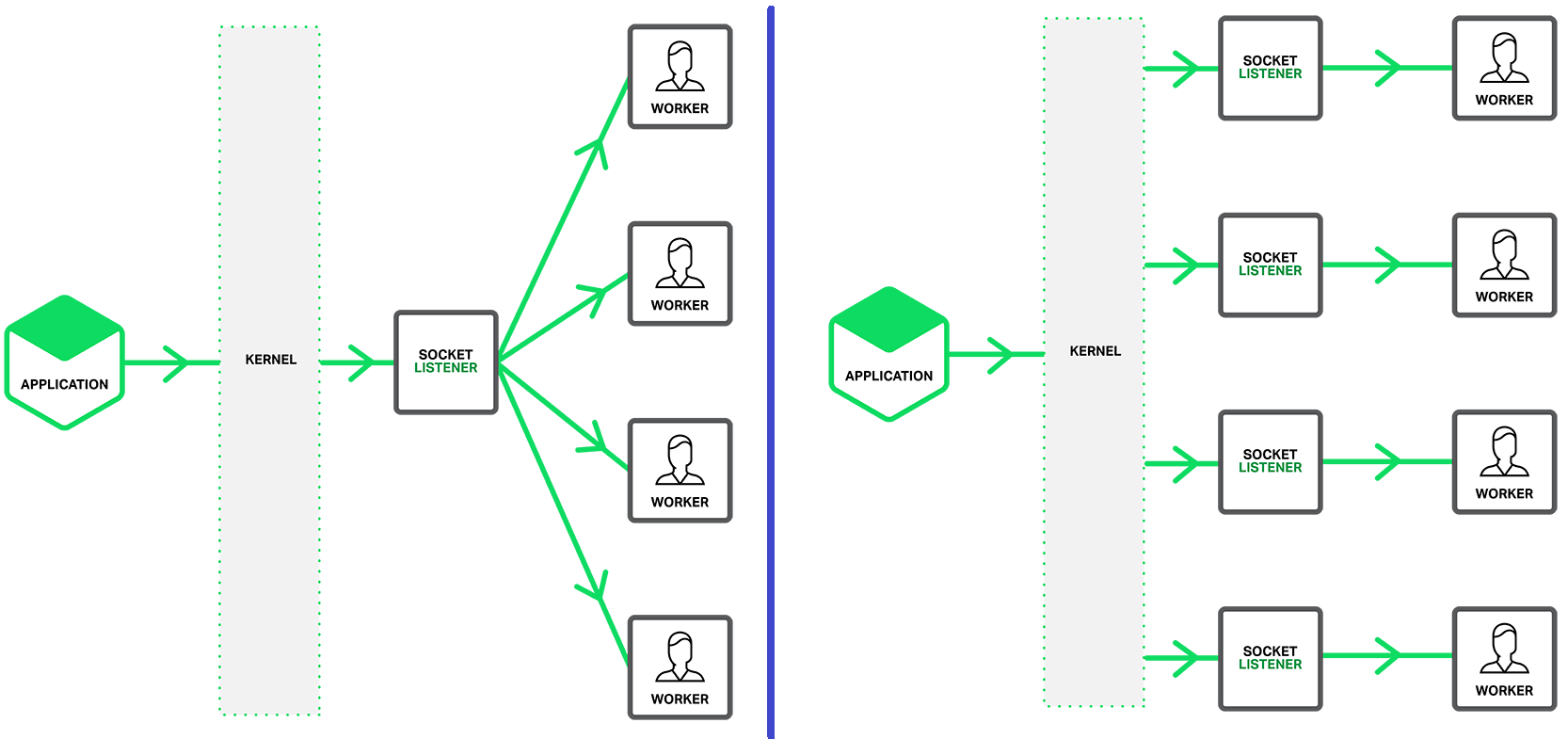
跨平台全面解析 SO_REUSEADDR 和 SO_REUSEPORT 这两个 socket 选项
全面介绍 TCP Keep-Alive 在 Unix 和 Windows 平台上的原理和应用
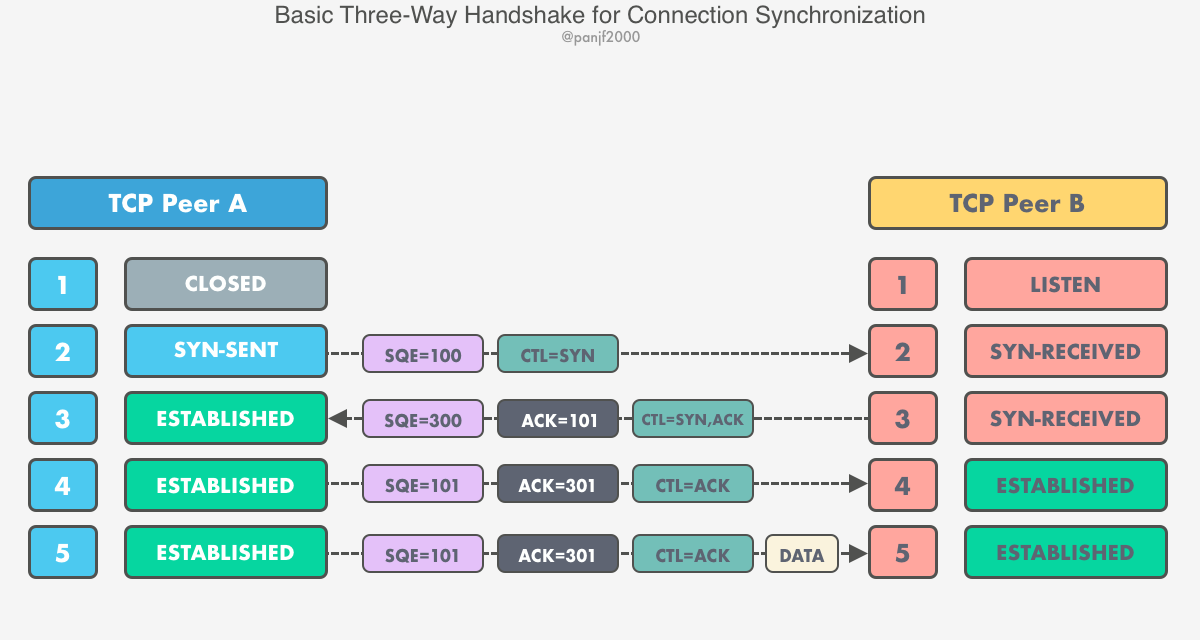
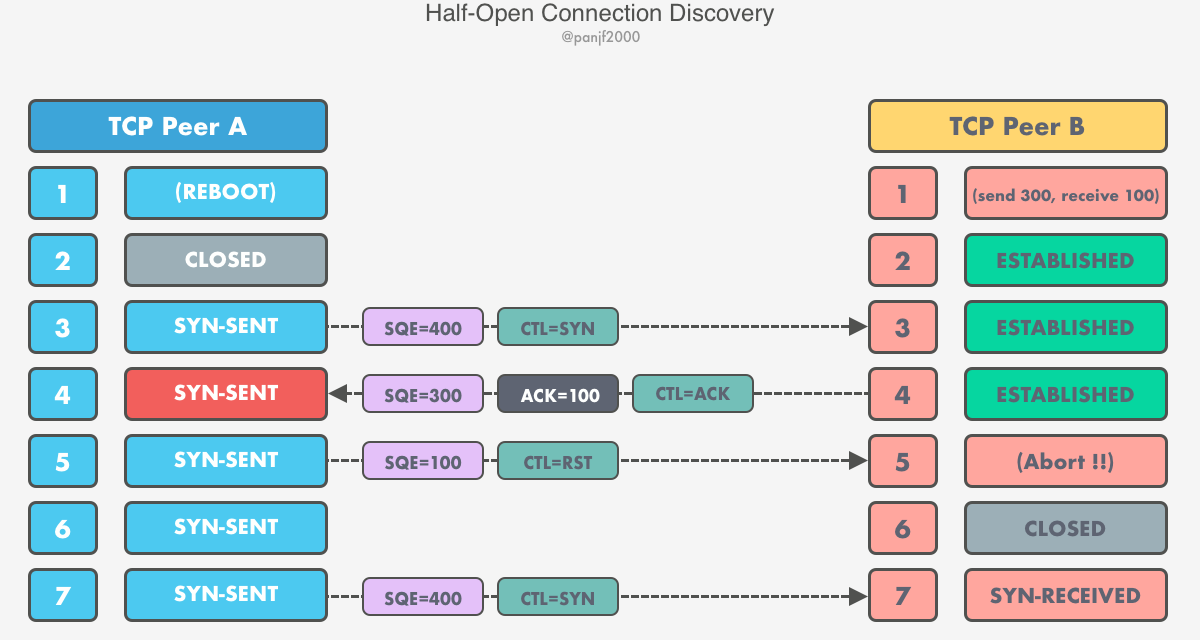
TCP 协议的设计与实现

相信那些曾经使用 Go 写过 proxy server 的同学应该对 io.Copy()/io.CopyN()/io.CopyBuffer()/io.ReaderFrom 等接口和方法不陌生,它们是使用 Go 操作各类 I/O 进行数据传输经常需要使用到的 API,其中基于 TCP 协议的 socket 在使用上述接口和方法进行数据传输时利用到了 Linux 的零拷贝技术 sendfile 和 splice。 我前段时间为 Go 语言内部的 Linux splice 零拷贝技术做了一点优化:为 splice 实现了一个 pipe pool,复用管道,减少频繁创建和销毁 pipe buffers 所带来的系统开销,理论上来说能够大幅提升 Go 的 io 标准库中基于 splice 零拷贝实现的 API 的性能。因此,我想从这个优化工作出发,分享一些我个人对多线程编程中的一些不成熟的优化思路。
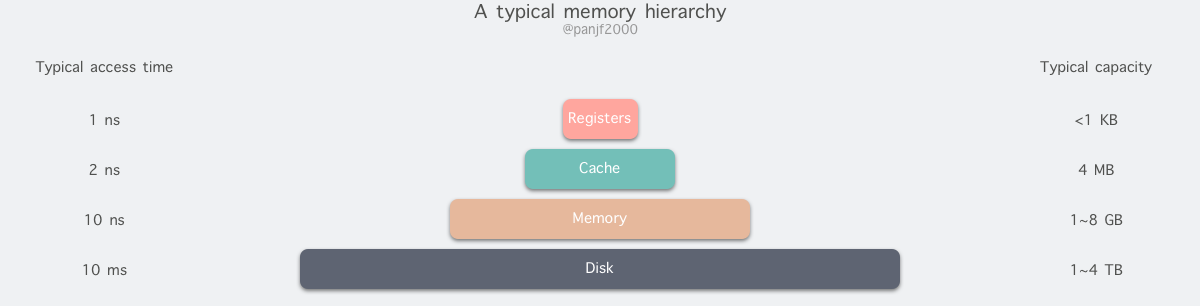
剖析计算机虚拟内存的核心原理和应用
从理论和源码层面全面剖析 Redis 6.0 新引入的多线程网络模型

深入分析 Kafka 为什么快
Strike Freedom