并发(并行),一直以来都是一个编程语言里的核心主题之一,也是被开发者关注最多的话题;Go 语言作为一个出道以来就自带 『高并发』光环的富二代编程语言,它的并发(并行)编程肯定是值得开发者去探究的,而 Go 语言中的并发(并行)编程是经由 goroutine 实现的,goroutine 是 golang 最重要的特性之一,具有使用成本低、消耗资源低、能效高等特点,官方宣称原生 goroutine 并发成千上万不成问题,于是它也成为 Gopher 们经常使用的特性。
Goroutine 是优秀的,但不是完美的,在极大规模的高并发场景下,也可能会暴露出问题,什么问题呢?又有什么可选的解决方案?本文将通过 runtime 对 goroutine 的调度分析,帮助大家理解它的机理和发现一些内存和调度的原理和问题,并且基于此提出一种个人的解决方案 — 一个高性能的 Goroutine Pool(协程池)。
Goroutine & Scheduler
Goroutine,Go 语言基于并发(并行)编程给出的自家的解决方案。goroutine 是什么?通常 goroutine 会被当做 coroutine(协程)的 golang 实现,从比较粗浅的层面来看,这种认知也算是合理,但实际上,goroutine 并非传统意义上的协程,现在主流的线程模型分三种:内核级线程模型、用户级线程模型和两级线程模型(也称混合型线程模型),传统的协程库属于用户级线程模型,而 goroutine 和它的 Go Scheduler 在底层实现上其实是属于两级线程模型,因此,有时候为了方便理解可以简单把 goroutine 类比成协程,但心里一定要有个清晰的认知 — goroutine 并不等同于协程。
线程那些事儿
互联网时代以降,由于在线用户数量的爆炸,单台服务器处理的连接也水涨船高,迫使编程模式由从前的串行模式升级到并发模型,而几十年来,并发模型也是一代代地升级,有 IO 多路复用、多进程以及多线程,这几种模型都各有长短,现代复杂的高并发架构大多是几种模型协同使用,不同场景应用不同模型,扬长避短,发挥服务器的最大性能,而多线程,因为其轻量和易用,成为并发编程中使用频率最高的并发模型,而后衍生的协程等其他子产品,也都基于它,而我们今天要分析的 goroutine 也是基于线程,因此,我们先来聊聊线程的三大模型:
线程的实现模型主要有 3 种:内核级线程模型、用户级线程模型和两级线程模型(也称混合型线程模型),它们之间最大的差异就在于用户线程与内核调度实体(KSE,Kernel Scheduling Entity)之间的对应关系上。而所谓的内核调度实体 KSE 就是指可以被操作系统内核调度器调度的对象实体(这说的啥玩意儿,敢不敢通俗易懂一点?)。简单来说 KSE 就是内核级线程,是操作系统内核的最小调度单元,也就是我们写代码的时候通俗理解上的线程了(这么说不就懂了嘛!装什么 13)。
用户级线程模型
用户线程与内核线程 KSE 是多对一(N : 1)的映射模型,多个用户线程的一般从属于单个进程并且多线程的调度是由用户自己的线程库来完成,线程的创建、销毁以及多线程之间的协调等操作都是由用户自己的线程库来负责而无须借助系统调用来实现。一个进程中所有创建的线程都只和同一个 KSE 在运行时动态绑定,也就是说,操作系统只知道用户进程而对其中的线程是无感知的,内核的所有调度都是基于用户进程。许多语言实现的 协程库 基本上都属于这种方式(比如 python 的 gevent)。由于线程调度是在用户层面完成的,也就是相较于内核调度不需要让 CPU 在用户态和内核态之间切换,这种实现方式相比内核级线程可以做的很轻量级,对系统资源的消耗会小很多,因此可以创建的线程数量与上下文切换所花费的代价也会小得多。但该模型有个原罪:并不能做到真正意义上的并发,假设在某个用户进程上的某个用户线程因为一个阻塞调用(比如 I/O 阻塞)而被 CPU 给中断(抢占式调度)了,那么该进程内的所有线程都被阻塞(因为单个用户进程内的线程自调度是没有 CPU 时钟中断的,从而没有轮转调度),整个进程被挂起。即便是多 CPU 的机器,也无济于事,因为在用户级线程模型下,一个 CPU 关联运行的是整个用户进程,进程内的子线程绑定到 CPU 执行是由用户进程调度的,内部线程对 CPU 是不可见的,此时可以理解为 CPU 的调度单位是用户进程。所以很多的协程库会把自己一些阻塞的操作重新封装为完全的非阻塞形式,然后在以前要阻塞的点上,主动让出自己,并通过某种方式通知或唤醒其他待执行的用户线程在该 KSE 上运行,从而避免了内核调度器由于 KSE 阻塞而做上下文切换,这样整个进程也不会被阻塞了。
内核级线程模型
用户线程与内核线程 KSE 是一对一(1 : 1)的映射模型,也就是每一个用户线程绑定一个实际的内核线程,而线程的调度则完全交付给操作系统内核去做,应用程序对线程的创建、终止以及同步都基于内核提供的系统调用来完成,大部分编程语言的线程库(比如 Java 的 java.lang.Thread、C++11 的 std::thread 等等)都是对操作系统的线程(内核级线程)的一层封装,创建出来的每个线程与一个独立的 KSE 静态绑定,因此其调度完全由操作系统内核调度器去做,也就是说,一个进程里创建出来的多个线程每一个都绑定一个 KSE。这种模型的优势和劣势同样明显:优势是实现简单,直接借助操作系统内核的线程以及调度器,所以 CPU 可以快速切换调度线程,于是多个线程可以同时运行,因此相较于用户级线程模型它真正做到了并行处理;但它的劣势是,由于直接借助了操作系统内核来创建、销毁和以及多个线程之间的上下文切换和调度,因此资源成本大幅上涨,且对性能影响很大。
两级线程模型
两级线程模型是博采众长之后的产物,充分吸收前两种线程模型的优点且尽量规避它们的缺点。在此模型下,用户线程与内核 KSE 是多对多(N : M)的映射模型:首先,区别于用户级线程模型,两级线程模型中的一个进程可以与多个内核线程 KSE 关联,也就是说一个进程内的多个线程可以分别绑定一个自己的 KSE,这点和内核级线程模型相似;其次,又区别于内核级线程模型,它的进程里的线程并不与 KSE 唯一绑定,而是可以多个用户线程映射到同一个 KSE,当某个 KSE 因为其绑定的线程的阻塞操作被内核调度出 CPU 时,其关联的进程中其余用户线程可以重新与其他 KSE 绑定运行。所以,两级线程模型既不是用户级线程模型那种完全靠自己调度的也不是内核级线程模型完全靠操作系统调度的,而是中间态(自身调度与系统调度协同工作),也就是 — 『薛定谔的模型』(误),因为这种模型的高度复杂性,操作系统内核开发者一般不会使用,所以更多时候是作为第三方库的形式出现,而 Go 语言中的 runtime 调度器就是采用的这种实现方案,实现了 Goroutine 与 KSE 之间的动态关联,不过 Go 语言的实现更加高级和优雅;该模型为何被称为两级?即用户调度器实现用户线程到 KSE 的『调度』,内核调度器实现 KSE 到 CPU 上的『调度』。
G-P-M 模型概述
每一个 OS 线程都有一个固定大小的内存块(一般会是 2MB)来做栈,这个栈会用来存储当前正在被调用或挂起(指在调用其它函数时)的函数的内部变量。这个固定大小的栈同时很大又很小。因为 2MB 的栈对于一个小小的 goroutine 来说是很大的内存浪费,而对于一些复杂的任务(如深度嵌套的递归)来说又显得太小。因此,Go 语言做了它自己的『线程』。
在 Go 语言中,每一个 goroutine 是一个独立的执行单元,相较于每个 OS 线程固定分配 2M 内存的模式,goroutine 的栈采取了动态扩容方式, 初始时仅为 2KB,随着任务执行按需增长,最大可达 1GB(64 位机器最大是 1G,32 位机器最大是 256M),且完全由 golang 自己的调度器 Go Scheduler 来调度。此外,GC 还会周期性地将不再使用的内存回收,收缩栈空间。 因此,Go 程序可以同时并发成千上万个 goroutine 是得益于它强劲的调度器和高效的内存模型。Go 的创造者大概对 goroutine 的定位就是屠龙刀,因为他们不仅让 goroutine 作为 golang 并发编程的最核心组件(开发者的程序都是基于 goroutine 运行的)而且 golang 中的许多标准库的实现也到处能见到 goroutine 的身影,比如 net/http 这个包,甚至语言本身的组件 runtime 运行时和 GC 垃圾回收器都是运行在 goroutine 上的,作者对 goroutine 的厚望可见一斑。
任何用户线程最终肯定都是要交由 OS 线程来执行的,goroutine(称为 G)也不例外,但是 G 并不直接绑定 OS 线程运行,而是由 Goroutine Scheduler 中的 P - Logical Processor (逻辑处理器)来作为两者的『中介』,P 可以看作是一个抽象的资源或者一个上下文,一个 P 绑定一个 OS 线程,在 golang 的实现里把 OS 线程抽象成一个数据结构:M,G 实际上是由 M 通过 P 来进行调度运行的,但是在 G 的层面来看,P 提供了 G 运行所需的一切资源和环境,因此在 G 看来 P 就是运行它的 “CPU”,由 G、P、M 这三种由 Go 抽象出来的实现,最终形成了 Go 调度器的基本结构:
- G: 表示 Goroutine,每个 Goroutine 对应一个 G 结构体,G 存储 Goroutine 的运行堆栈、状态以及任务函数,可重用。G 并非执行体,每个 G 需要绑定到 P 才能被调度执行。
- P: Processor,表示逻辑处理器, 对 G 来说,P 相当于 CPU 核,G 只有绑定到 P(在 P 的 local runq 中)才能被调度。对 M 来说,P 提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等,P 的数量决定了系统内最大可并行的 G 的数量(前提:物理 CPU 核数 >= P 的数量),P 的数量由用户设置的 GOMAXPROCS 决定,但是不论 GOMAXPROCS 设置为多大,P 的数量最大为 256。
- M: Machine,OS 线程抽象,代表着真正执行计算的资源,在绑定有效的 P 后,进入 schedule 循环;而 schedule 循环的机制大致是从 Global 队列、P 的 Local 队列以及 wait 队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 goexit 做清理工作并回到 M,如此反复。M 并不保留 G 状态,这是 G 可以跨 M 调度的基础,M 的数量是不定的,由 Go Runtime 调整,为了防止创建过多 OS 线程导致系统调度不过来,目前默认最大限制为 10000 个。
关于 P,我们需要再絮叨几句,在 Go 1.0 发布的时候,它的调度器其实 G-M 模型,也就是没有 P 的,调度过程全由 G 和 M 完成,这个模型暴露出一些问题:
- 单一全局互斥锁(Sched.Lock)和集中状态存储的存在导致所有 goroutine 相关操作,比如:创建、重新调度等都要上锁;
- goroutine 传递问题:M 经常在 M 之间传递『可运行』的 goroutine,这导致调度延迟增大以及额外的性能损耗;
- 每个 M 做内存缓存,导致内存占用过高,数据局部性较差;
- 由于 syscall 调用而形成的剧烈的 worker thread 阻塞和解除阻塞,导致额外的性能损耗。
这些问题实在太扎眼了,导致 Go1.0 虽然号称原生支持并发,却在并发性能上一直饱受诟病,然后,Go 语言委员会中一个核心开发大佬看不下了,亲自下场重新设计和实现了 Go 调度器(在原有的 G-M 模型中引入了 P)并且实现了一个叫做 work-stealing 的调度算法:
- 每个 P 维护一个 G 的本地队列;
- 当一个 G 被创建出来,或者变为可执行状态时,就把他放到 P 的可执行队列中;
- 当一个 G 在 M 里执行结束后,P 会从队列中把该 G 取出;如果此时 P 的队列为空,即没有其他 G 可以执行, M 就随机选择另外一个 P,从其可执行的 G 队列中取走一半。
该算法避免了在 goroutine 调度时使用全局锁。
至此,Go 调度器的基本模型确立:
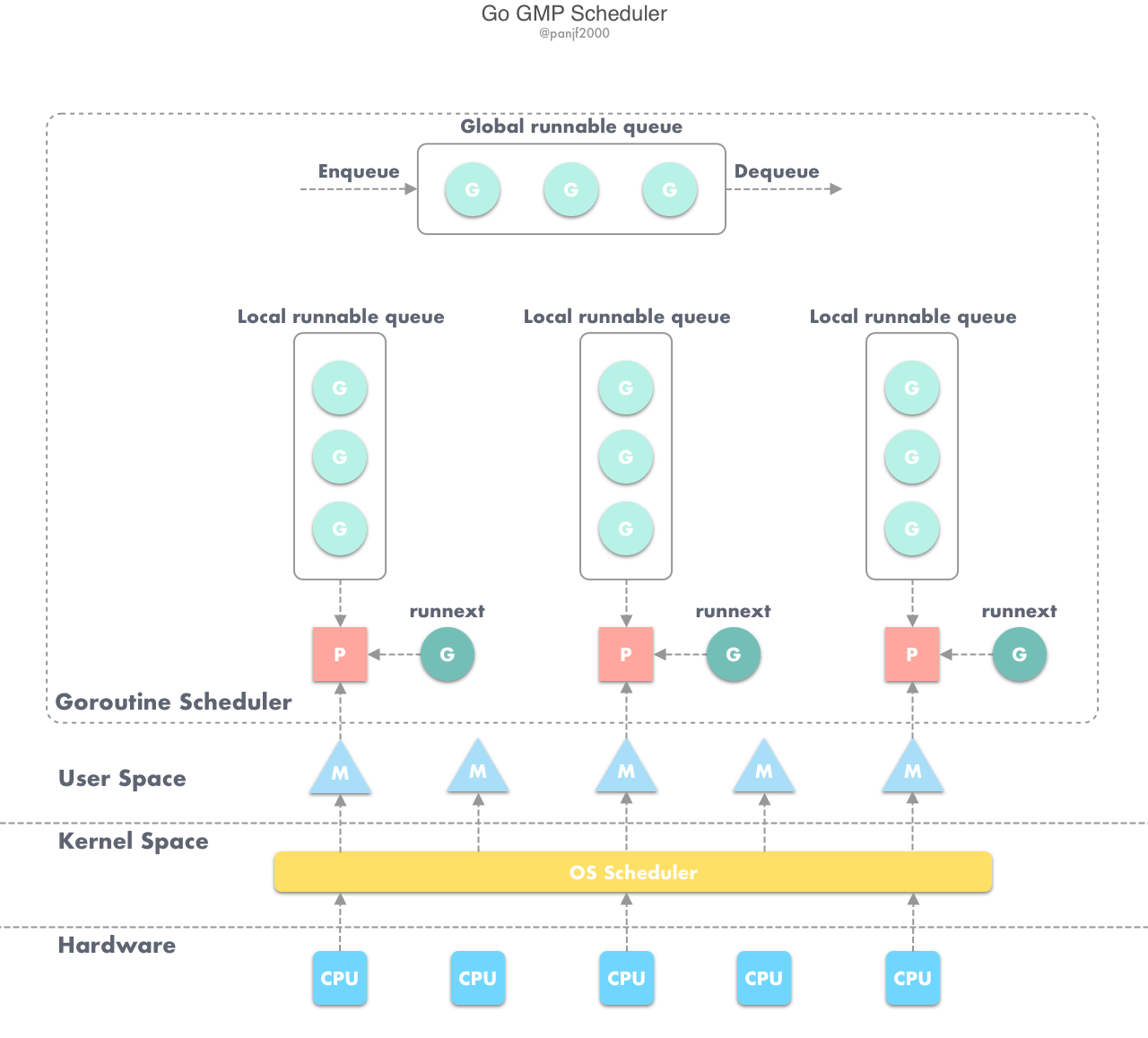
G-P-M 模型调度
Go 调度器工作时会维护两种用来保存 G 的任务队列:一种是一个 Global 任务队列,一种是每个 P 维护的 Local 任务队列。
当通过 go 关键字创建一个新的 goroutine 的时候,它会优先被放入 P 的本地队列。为了运行 goroutine,M 需要持有(绑定)一个 P,接着 M 会启动一个 OS 线程,循环从 P 的本地队列里取出一个 goroutine 并执行。当然还有上文提及的 work-stealing 调度算法:当 M 执行完了当前 P 的 Local 队列里的所有 G 后,P 也不会就这么在那躺尸啥都不干,它会先尝试从 Global 队列寻找 G 来执行,如果 Global 队列为空,它会随机挑选另外一个 P,从它的队列里中拿走一半的 G 到自己的队列中执行。
如果一切正常,调度器会以上述的那种方式顺畅地运行,但这个世界没这么美好,总有意外发生,以下分析 goroutine 在两种例外情况下的行为。
Go runtime 会在下面的 goroutine 被阻塞的情况下运行另外一个 goroutine:
- blocking syscall (for example opening a file)
- network input
- channel operations
- primitives in the sync package
这四种场景又可归类为两种类型:
用户态阻塞/唤醒
当 goroutine 因为 channel 操作或者 network I/O 而阻塞时(实际上 golang 已经用 netpoller 实现了 goroutine 网络 I/O 阻塞不会导致 M 被阻塞,仅阻塞 G,这里仅仅是举个栗子),对应的 G 会被放置到某个 wait 队列(如 channel 的 waitq),该 G 的状态由 _Gruning 变为 _Gwaitting ,而 M 会跳过该 G 尝试获取并执行下一个 G,如果此时没有 runnable 的 G 供 M 运行,那么 M 将解绑 P,并进入 sleep 状态;当阻塞的 G 被另一端的 G2 唤醒时(比如 channel 的可读/写通知),G 被标记为 runnable,尝试加入 G2 所在 P 的 runnext,然后再是 P 的 Local 队列和 Global 队列。
系统调用阻塞
当 G 被阻塞在某个系统调用上时,此时 G 会阻塞在 _Gsyscall 状态,M 也处于 block on syscall 状态,此时的 M 可被抢占调度:执行该 G 的 M 会与 P 解绑,而 P 则尝试与其它 idle 的 M 绑定,继续执行其它 G。如果没有其它 idle 的 M,但 P 的 Local 队列中仍然有 G 需要执行,则创建一个新的 M;当系统调用完成后,G 会重新尝试获取一个 idle 的 P 进入它的 Local 队列恢复执行,如果没有 idle 的 P,G 会被标记为 runnable 加入到 Global 队列。
以上就是从宏观的角度对 Goroutine 和它的调度器进行的一些概要性的介绍,当然,Go 的调度中更复杂的抢占式调度、阻塞调度的更多细节,大家可以自行去找相关资料深入理解,本文只讲到 Go 调度器的基本调度过程,为后面自己实现一个 Goroutine Pool 提供理论基础,这里便不再继续深入上述说的那几个调度了,事实上如果要完全讲清楚 Go 调度器,一篇文章的篇幅也实在是捉襟见肘,所以想了解更多细节的同学可以去看看 Go 调度器 G-P-M 模型的设计者 Dmitry Vyukov 写的该模型的设计文档《Go Preemptive Scheduler Design》以及直接去看源码,G-P-M 模型的定义放在 src/runtime/runtime2.go 里面,而调度过程则放在了 src/runtime/proc.go 里。
大规模 Goroutine 的瓶颈
既然 Go 调度器已经这么牛逼优秀了,我们为什么还要自己去实现一个 golang 的 Goroutine Pool 呢?事实上,优秀不代表完美,任何不考虑具体应用场景的编程模式都是耍流氓!有基于 G-P-M 的 Go 调度器背书,go 程序的并发编程中,可以任性地起大规模的 goroutine 来执行任务,官方也宣称用 golang 写并发程序的时候随便起个成千上万的 goroutine 毫无压力。
然而,你起 1000 个 goroutine 没有问题,10000 也没有问题,10w 个可能也没问题;那,100w 个呢?1000w 个呢?(这里只是举个极端的例子,实际编程起这么大规模的 goroutine 的例子极少)这里就会出问题,什么问题呢?
- 首先,即便每个 goroutine 只分配 2KB 的内存,但如果是恐怖如斯的数量,聚少成多,内存暴涨,就会对 GC 造成极大的负担,写过 Java 的同学应该知道 jvm GC 那万恶的 STW(Stop The World)机制,也就是 GC 的时候会挂起用户程序直到垃圾回收完,虽然 Go1.8 之后的 GC 已经去掉了 STW 以及优化成了并行 GC,性能上有了不小的提升,但是,如果太过于频繁地进行 GC,依然会有性能瓶颈;
- 其次,还记得前面我们说的 runtime 和 GC 也都是 goroutine 吗?是的,如果 goroutine 规模太大,内存吃紧,runtime 调度和垃圾回收同样会出问题,虽然 G-P-M 模型足够优秀,韩信点兵,多多益善,但你不能不给士兵发口粮(内存)吧?巧妇难为无米之炊,没有内存,Go 调度器就会阻塞 goroutine,结果就是 P 的 Local 队列积压,又导致内存溢出,这就是个死循环...,甚至极有可能程序直接 Crash 掉,本来是想享受 golang 并发带来的
快感效益,结果却得不偿失。
一个 http 标准库引发的血案
我想,作为 golang 拥趸的 Gopher 们一定都使用过它的 net/http 标准库,很多人都说用 golang 写 Web server 完全可以不用借助第三方的 Web framework,仅用 net/http 标准库就能写一个高性能的 Web server,的确,我也用过它写过 Web server,简洁高效,性能表现也相当不错,除非有比较特殊的需求否则一般的确不用借助第三方 Web framework,但是天下没有白吃的午餐,net/http 为啥这么快?要搞清这个问题,从源码入手是最好的途径。孔子曾经曰过:源码面前,如同裸奔。所以,高清无码是阻碍程序猿发展大大滴绊脚石啊,源码才是我们进步阶梯,切记切记!
接下来我们就来先看看 net/http 内部是怎么实现的。
net/http 接收请求且开始处理的源码放在 src/net/http/server.go 里,先从入口函数 ListenAndServe 进去:
func (srv *Server) ListenAndServe() error {
addr := srv.Addr
if addr == "" {
addr = ":http"
}
ln, err := net.Listen("tcp", addr)
if err != nil {
return err
}
return srv.Serve(tcpKeepAliveListener{ln.(*net.TCPListener)})
}
看到最后那个 srv.Serve 调用了吗?没错,这个 Serve 方法里面就是实际处理 http 请求的逻辑,我们再进入这个方法内部:
func (srv *Server) Serve(l net.Listener) error {
defer l.Close()
...
// 不断循环取出TCP连接
for {
// 看我看我!!!
rw, e := l.Accept()
...
// 再看我再看我!!!
go c.serve(ctx)
}
}
首先,这个方法的参数(l net.Listener) ,是一个 TCP 监听的封装,负责监听网络端口, rw, e := l.Accept() 则是一个阻塞操作,从网络端口取出一个新的 TCP 连接进行处理,最后 go c.serve(ctx) 就是最后真正去处理这个 http 请求的逻辑了,看到前面的 go 关键字了吗?没错,这里启动了一个新的 goroutine 去执行处理逻辑,而且这是在一个无限循环体里面,所以意味着,每来一个请求它就会开一个 goroutine 去处理,相当任性粗暴啊…,不过有 Go 调度器背书,一般来说也没啥压力,然而,如果,我是说如果哈,突然一大波请求涌进来了(比方说黑客搞了成千上万的肉鸡 DDOS 你,没错!就这么倒霉!),这时候,就很成问题了,他来 10w 个请求你就要开给他 10w 个 goroutine,来 100w 个你就要老老实实开给他 100w 个,线程调度压力陡升,内存爆满,再然后,你就跪了…
釜底抽薪
有问题,就一定有解决的办法,那么,有什么方案可以减缓大规模 goroutine 对系统的调度和内存压力?要想解决问题,最重要的是找到造成问题的根源,这个问题根源是什么?goroutine 的数量过多导致资源侵占,那要解决这个问题就要限制运行的 goroutine 数量,合理复用,节省资源,具体就是 — goroutine 池化。
超大规模并发的场景下,不加限制的大规模的 goroutine 可能造成内存暴涨,给机器带来极大的压力,吞吐量下降和处理速度变慢还是其次,更危险的是可能使得程序 crash。所以,goroutine 池化是有其现实意义的。
首先,100w 个任务,是不是真的需要 100w 个 goroutine 来处理?未必!用 1w 个 goroutine 也一样可以处理,让一个 goroutine 多处理几个任务就是了嘛,池化的核心优势就在于对 goroutine 的复用。此举首先极大减轻了 runtime 调度 goroutine 的压力,其次,便是降低了对内存的消耗。

有一个商场,来了 1000 个顾客买东西,那么该如何安排导购员服务这 1000 人呢?有两种方案:
第一,我雇 1000 个导购员实行一对一服务,这种当然是最高效的,但是太浪费资源了,雇 1000 个人的成本极高且管理困难,这些可以先按下不表,但是每个顾客到商场买东西也不是一进来就马上买,一般都得逛一逛,选一选,也就是得花时间挑,1000 个导购员一对一盯着,效率极低;这就引出第二种方案:我只雇 10 个导购员,就在商场里待命,有顾客需要咨询的时候招呼导购员过去进行处理,导购员处理完之后就回来,等下一个顾客需要咨询的时候再去,如此往返反复...
第二种方案有没有觉得很眼熟?没错,其基本思路就是模拟一个 I/O 多路复用,通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。关于多路复用,不在本文的讨论范围之内,便不再赘述,详细原理可以参考 I/O多路复用。
第一种方案就是 net/http 标准库采用的:来一个请求开一个 goroutine 处理;第二种方案就是 Goroutine Pool(I/O 多路复用)。
实现一个 Goroutine Pool
因为上述陈列的一些由于 goroutine 规模过大而可能引发的问题,需要有方案来解决这些问题,上文已经分析过,把 goroutine 池化是一种行之有效的方案,基于此,可以实现一个 Goroutine Pool,复用 goroutine,减轻 runtime 的调度压力以及缓解内存压力,依托这些优化,在大规模 goroutine 并发的场景下可以极大地提高并发性能。
哎玛!前面絮絮叨叨了这么多,终于进入正题了,接下来就开始讲解如何实现一个高性能的 Goroutine Pool,秒杀原生并发的 goroutine,在执行速度和占用内存上提高并发程序的性能。好了,话不多说,开始
装逼分析。
设计思路
Goroutine Pool 的实现思路大致如下:
启动服务之时先初始化一个 Goroutine Pool 池,这个 Pool 维护了一个类似栈的 LIFO 队列 ,里面存放负责处理任务的 Worker,然后在 client 端提交 task 到 Pool 中之后,在 Pool 内部,接收 task 之后的核心操作是:
- 检查当前 Worker 队列中是否有可用的 Worker,如果有,取出执行当前的 task;
- 没有可用的 Worker,判断当前在运行的 Worker 是否已超过该 Pool 的容量:{是 —> 再判断工作池是否为非阻塞模式:[是 ——> 直接返回 nil,否 ——> 阻塞等待直至有 Worker 被放回 Pool],否 —> 新开一个 Worker(goroutine)处理};
- 每个 Worker 执行完任务之后,放回 Pool 的队列中等待。
核心调度流程如下:
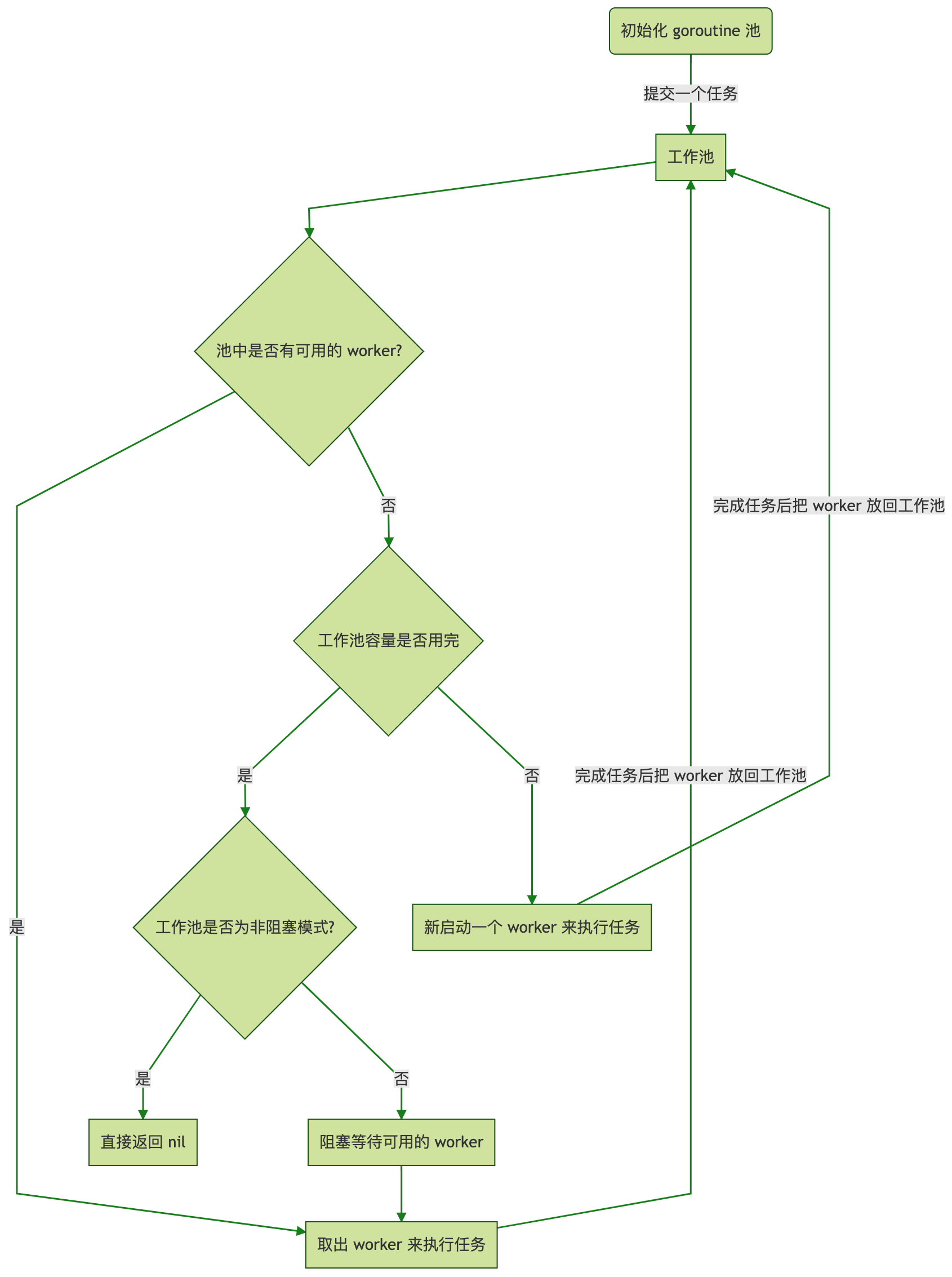
按照这个设计思路,我实现了一个高性能的 Goroutine Pool,较好地解决了上述的大规模调度和资源占用的问题,在执行速度和内存占用方面相较于原生 goroutine 并发占有明显的优势,尤其是内存占用,因为复用,所以规避了无脑启动大规模 goroutine 的弊端,可以节省大量的内存。
此外,该调度系统还有一个清理过期 Worker 的定时任务,该任务在初始化一个 Pool 之时启动,每隔一定的时间间隔去检查空闲 Worker 队列中是否有已经过期的 Worker,有则清理掉,通过定时清理过期 worker,进一步节省系统资源。
完整的项目代码可以在我的 GitHub 上获取:传送门,也欢迎提意见和交流。
实现细节
Goroutine Pool 的设计原理前面已经讲过了,整个调度过程相信大家应该可以理解了,但是有一句老话说得好,空谈误国,实干兴邦,设计思路有了,具体实现的时候肯定会有很多细节、难点,接下来我们通过分析这个 Goroutine Pool 的几个核心实现以及它们的联动来引导大家过一遍 Goroutine Pool 的原理。
首先是 Pool struct :
type sig struct{}
type f func() error
// Pool accept the tasks from client,it limits the total
// of goroutines to a given number by recycling goroutines.
type Pool struct {
// capacity of the pool.
capacity int32
// running is the number of the currently running goroutines.
running int32
// expiryDuration set the expired time (second) of every worker.
expiryDuration time.Duration
// workers is a slice that store the available workers.
workers []*Worker
// release is used to notice the pool to closed itself.
release chan sig
// lock for synchronous operation.
lock sync.Mutex
once sync.Once
}
Pool 是一个通用的协程池,支持不同类型的任务,亦即每一个任务绑定一个函数提交到池中,批量执行不同类型任务,是一种广义的协程池;本项目中还实现了另一种协程池 — 批量执行同类任务的协程池 PoolWithFunc ,每一个 PoolWithFunc 只会绑定一个任务函数 pf ,这种 Pool 适用于大批量相同任务的场景,因为每个 Pool 只绑定一个任务函数,因此 PoolWithFunc 相较于 Pool 会更加节省内存,但通用性就不如前者了,为了让大家更好地理解协程池的原理,这里我们用通用的 Pool 来分析。
capacity 是该 Pool 的容量,也就是开启 worker 数量的上限,每一个 worker 绑定一个 goroutine; running 是当前正在执行任务的 worker 数量; expiryDuration 是 worker 的过期时长,在空闲队列中的 worker 的最新一次运行时间与当前时间之差如果大于这个值则表示已过期,定时清理任务会清理掉这个 worker; workers 是一个 slice,用来存放空闲 worker,请求进入 Pool 之后会首先检查 workers 中是否有空闲 worker,若有则取出绑定任务执行,否则判断当前运行的 worker 是否已经达到容量上限,是—阻塞等待,否—新开一个 worker 执行任务; release 是当关闭该 Pool 支持通知所有 worker 退出运行以防 goroutine 泄露; lock 是一个锁,用以支持 Pool 的同步操作; once 用在确保 Pool 关闭操作只会执行一次。
初始化 Pool 并启动定期清理过期 worker 任务
// NewPool generates a instance of ants pool
func NewPool(size int) (*Pool, error) {
return NewTimingPool(size, DefaultCleanIntervalTime)
}
// NewTimingPool generates a instance of ants pool with a custom timed task
func NewTimingPool(size, expiry int) (*Pool, error) {
if size <= 0 {
return nil, ErrInvalidPoolSize
}
if expiry <= 0 {
return nil, ErrInvalidPoolExpiry
}
p := &Pool{
capacity: int32(size),
freeSignal: make(chan sig, math.MaxInt32),
release: make(chan sig, 1),
expiryDuration: time.Duration(expiry) * time.Second,
}
// 启动定期清理过期worker任务,独立goroutine运行,
// 进一步节省系统资源
p.monitorAndClear()
return p, nil
}
提交任务到 Pool
p.Submit(task f) 如下:
// Submit submit a task to pool
func (p *Pool) Submit(task f) error {
if len(p.release) > 0 {
return ErrPoolClosed
}
w := p.getWorker()
w.task <- task
return nil
}
第一个 if 判断当前 Pool 是否已被关闭,若是则不再接受新任务,否则获取一个 Pool 中可用的 worker,绑定该 task 执行。
获取可用 worker(核心)
p.getWorker() 源码:
// getWorker returns a available worker to run the tasks.
func (p *Pool) getWorker() *Worker {
var w *Worker
// 标志变量,判断当前正在运行的worker数量是否已到达Pool的容量上限
waiting := false
// 加锁,检测队列中是否有可用worker,并进行相应操作
p.lock.Lock()
idleWorkers := p.workers
n := len(idleWorkers) - 1
// 当前队列中无可用worker
if n < 0 {
// 判断运行worker数目已达到该Pool的容量上限,置等待标志
waiting = p.Running() >= p.Cap()
// 当前队列有可用worker,从队列尾部取出一个使用
} else {
w = idleWorkers[n]
idleWorkers[n] = nil
p.workers = idleWorkers[:n]
}
// 检测完成,解锁
p.lock.Unlock()
// Pool容量已满,新请求等待
if waiting {
// 利用锁阻塞等待直到有空闲worker
for {
p.lock.Lock()
idleWorkers = p.workers
l := len(idleWorkers) - 1
if l < 0 {
p.lock.Unlock()
continue
}
w = idleWorkers[l]
idleWorkers[l] = nil
p.workers = idleWorkers[:l]
p.lock.Unlock()
break
}
// 当前无空闲worker但是Pool还没有满,
// 则可以直接新开一个worker执行任务
} else if w == nil {
w = &Worker{
pool: p,
task: make(chan f, 1),
}
w.run()
// 运行worker数加一
p.incRunning()
}
return w
}
上面的源码中加了较为详细的注释,结合前面的设计思路,相信大家应该能理解获取可用 worker 绑定任务执行这个协程池的核心操作,主要就是实现一个 LIFO 队列用来存取可用 worker 达到资源复用的效果,之所以采用 LIFO 后进先出队列是因为后进先出可以保证空闲 worker 队列是按照每个 worker 的最后运行时间从远到近的顺序排列,方便在后续定期清理过期 worker 时排序以及清理完之后重新分配空闲 worker 队列,这里还要关注一个地方:达到 Pool 容量限制之后,额外的任务请求需要阻塞等待 idle worker,这里是为了防止无节制地创建 goroutine,事实上 Go 调度器有一个复用机制,每次使用 go 关键字的时候它会检查当前结构体 M 中的 P 中,是否有可用的结构体 G。如果有,则直接从中取一个,否则,需要分配一个新的结构体 G。如果分配了新的 G,需要将它挂到 runtime 的相关队列中,但是调度器却没有限制 goroutine 的数量,这在瞬时性 goroutine 爆发的场景下就可能来不及复用 G 而依然创建了大量的 goroutine,所以 ants 除了复用还做了限制 goroutine 数量。
其他部分可以依照注释理解,这里不再赘述。
任务执行
// Worker is the actual executor who runs the tasks,
// it starts a goroutine that accepts tasks and
// performs function calls.
type Worker struct {
// pool who owns this worker.
pool *Pool
// task is a job should be done.
task chan f
// recycleTime will be update when putting a worker back into queue.
recycleTime time.Time
}
// run starts a goroutine to repeat the process
// that performs the function calls.
func (w *Worker) run() {
go func() {
// 循环监听任务列表,一旦有任务立马取出运行
for f := range w.task {
if f == nil {
// 退出goroutine,运行worker数减一
w.pool.decRunning()
return
}
f()
// worker回收复用
w.pool.putWorker(w)
}
}()
}
结合前面的 p.Submit(task f) 和 p.getWorker() ,提交任务到 Pool 之后,获取一个可用 worker,每新建一个 worker 实例之时都需要调用 w.run() 启动一个 goroutine 监听 worker 的任务列表 task ,一有任务提交进来就执行;所以,当调用 worker 的 sendTask(task f) 方法提交任务到 worker 的任务队列之后,马上就可以被接收并执行,当任务执行完之后,会调用 w.pool.putWorker(w *Worker) 方法将这个已经执行完任务的 worker 从当前任务解绑放回 Pool 中,以供下个任务可以使用,至此,一个任务从提交到完成的过程就此结束,Pool 调度将进入下一个循环。
Worker 回收(goroutine 复用)
// putWorker puts a worker back into free pool, recycling the goroutines.
func (p *Pool) putWorker(worker *Worker) {
// 写入回收时间,亦即该worker的最后一次结束运行的时间
worker.recycleTime = time.Now()
p.lock.Lock()
p.workers = append(p.workers, worker)
p.lock.Unlock()
}
动态扩容或者缩小池容量
// ReSize change the capacity of this pool
func (p *Pool) ReSize(size int) {
if size == p.Cap() {
return
}
atomic.StoreInt32(&p.capacity, int32(size))
diff := p.Running() - size
if diff > 0 {
for i := 0; i < diff; i++ {
p.getWorker().task <- nil
}
}
}
定期清理过期 Worker
// clear expired workers periodically.
func (p *Pool) periodicallyPurge() {
heartbeat := time.NewTicker(p.expiryDuration)
for range heartbeat.C {
currentTime := time.Now()
p.lock.Lock()
idleWorkers := p.workers
if len(idleWorkers) == 0 && p.Running() == 0 && len(p.release) > 0 {
p.lock.Unlock()
return
}
n := 0
for i, w := range idleWorkers {
if currentTime.Sub(w.recycleTime) <= p.expiryDuration {
break
}
n = i
w.task <- nil
idleWorkers[i] = nil
}
n++
if n >= len(idleWorkers) {
p.workers = idleWorkers[:0]
} else {
p.workers = idleWorkers[n:]
}
p.lock.Unlock()
}
}
定期检查空闲 worker 队列中是否有已过期的 worker 并清理:因为采用了 LIFO 后进先出队列存放空闲 worker,所以该队列默认已经是按照 worker 的最后运行时间由远及近排序,可以方便地按顺序取出空闲队列中的每个 worker 并判断它们的最后运行时间与当前时间之差是否超过设置的过期时长,若是,则清理掉该 goroutine,释放该 worker,并且将剩下的未过期 worker 重新分配到当前 Pool 的空闲 worker 队列中,进一步节省系统资源。
概括起来, ants Goroutine Pool 的调度过程图示如下:

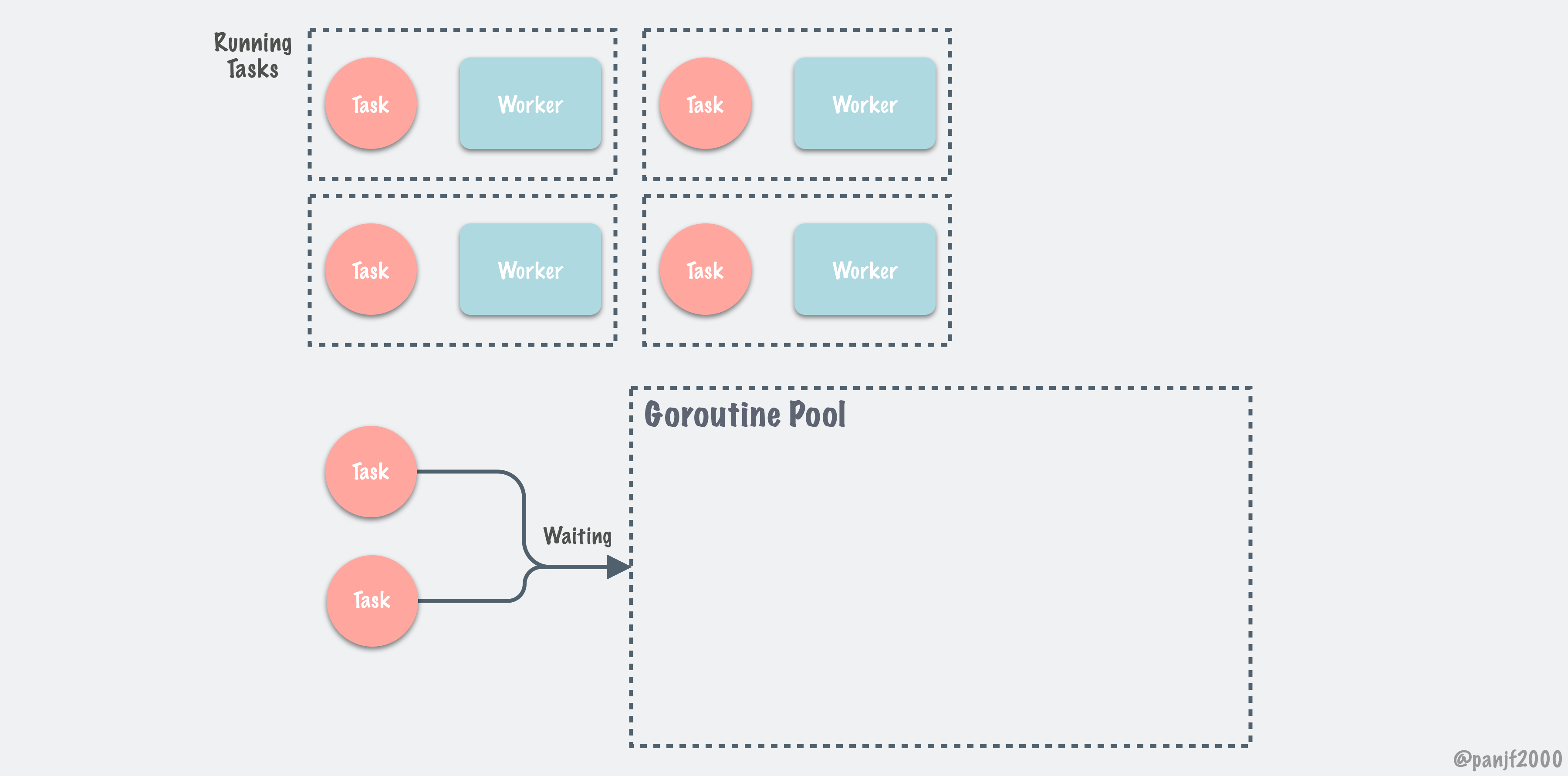
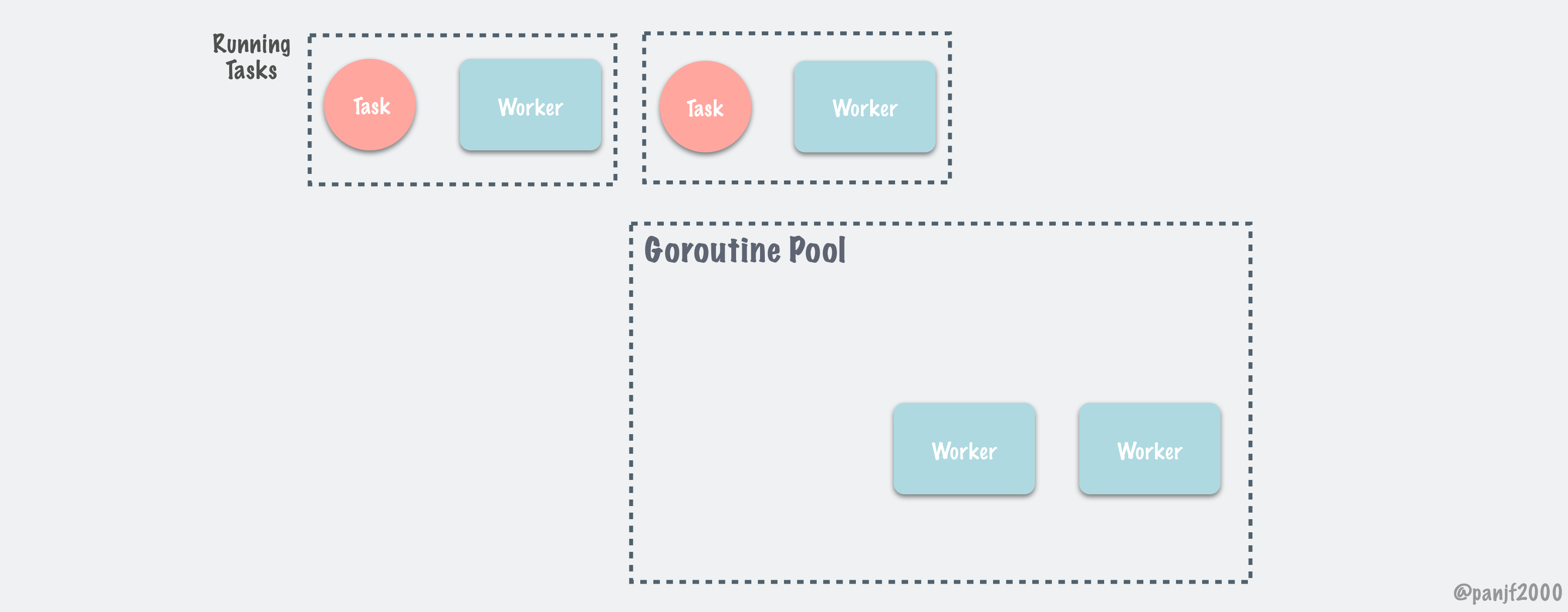
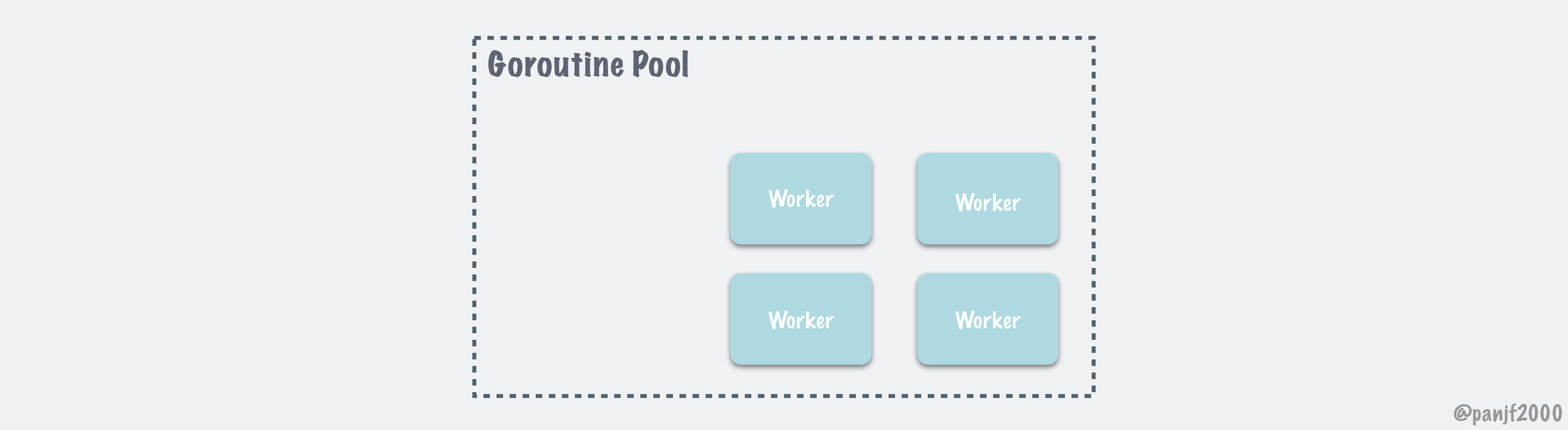
彩蛋
还记得前面我说除了通用的 Pool struct 之外,本项目还实现了一个 PoolWithFunc struct —一个执行批量同类任务的协程池, PoolWithFunc 相较于 Pool ,因为一个池只绑定一个任务函数,省去了每一次 task 都需要传送一个任务函数的代价,因此其性能优势比起 Pool 更明显,这里我们稍微讲一下一个协程池只绑定一个任务函数的细节:
上码!
type pf func(interface{}) error
// PoolWithFunc accept the tasks from client,it limits the total
// of goroutines to a given number by recycling goroutines.
type PoolWithFunc struct {
// capacity of the pool.
capacity int32
// running is the number of the currently running goroutines.
running int32
// expiryDuration set the expired time (second) of every worker.
expiryDuration time.Duration
// workers is a slice that store the available workers.
workers []*WorkerWithFunc
// release is used to notice the pool to closed itself.
release chan sig
// lock for synchronous operation.
lock sync.Mutex
// pf is the function for processing tasks.
poolFunc pf
once sync.Once
}
PoolWithFunc struct 中的大部分字段和 Pool struct 基本一致,重点关注 poolFunc pf ,这是一个函数类型,也就是该 Pool 绑定的指定任务函数,而 client 提交到这种类型的 Pool 的数据就不再是一个任务函数 task f 了,而是 poolFunc pf 任务函数的形参,然后交由 WorkerWithFunc 处理:
// WorkerWithFunc is the actual executor who runs the tasks,
// it starts a goroutine that accepts tasks and
// performs function calls.
type WorkerWithFunc struct {
// pool who owns this worker.
pool *PoolWithFunc
// args is a job should be done.
args chan interface{}
// recycleTime will be update when putting a worker back into queue.
recycleTime time.Time
}
// run starts a goroutine to repeat the process
// that performs the function calls.
func (w *WorkerWithFunc) run() {
go func() {
for args := range w.args {
if args == nil {
w.pool.decRunning()
return
}
w.pool.poolFunc(args)
w.pool.putWorker(w)
}
}()
}
上面的源码可以看到 WorkerWithFunc 是一个类似 Worker 的结构,只不过监听的是函数的参数队列,每接收到一个参数包,就直接调用 PoolWithFunc 绑定好的任务函数 poolFunc pf 任务函数执行任务,接下来的流程就和 Worker 是一致的了,执行完任务后就把 worker 放回协程池,等待下次使用。
至于其他逻辑如提交 task 、获取 Worker 绑定任务等基本复用自 Pool struct ,具体细节有细微差别,但原理一致,万变不离其宗,有兴趣的同学可以看我在 GitHub 上的源码:Goroutine Pool 协程池 ants 。
Benchmarks
吹了这么久的 Goroutine Pool,那都是虚的,理论上池化可以复用 goroutine,提升性能节省内存,没有 benchmark 数据之前,好像也不能服众哈!所以,本章就来进行一次实测,验证一下再大规模 goroutine 并发的场景下,Goroutine Pool 的表现是不是真的比原生 Goroutine 并发更好!
测试机器参数:
Pool 测试
测试结果:
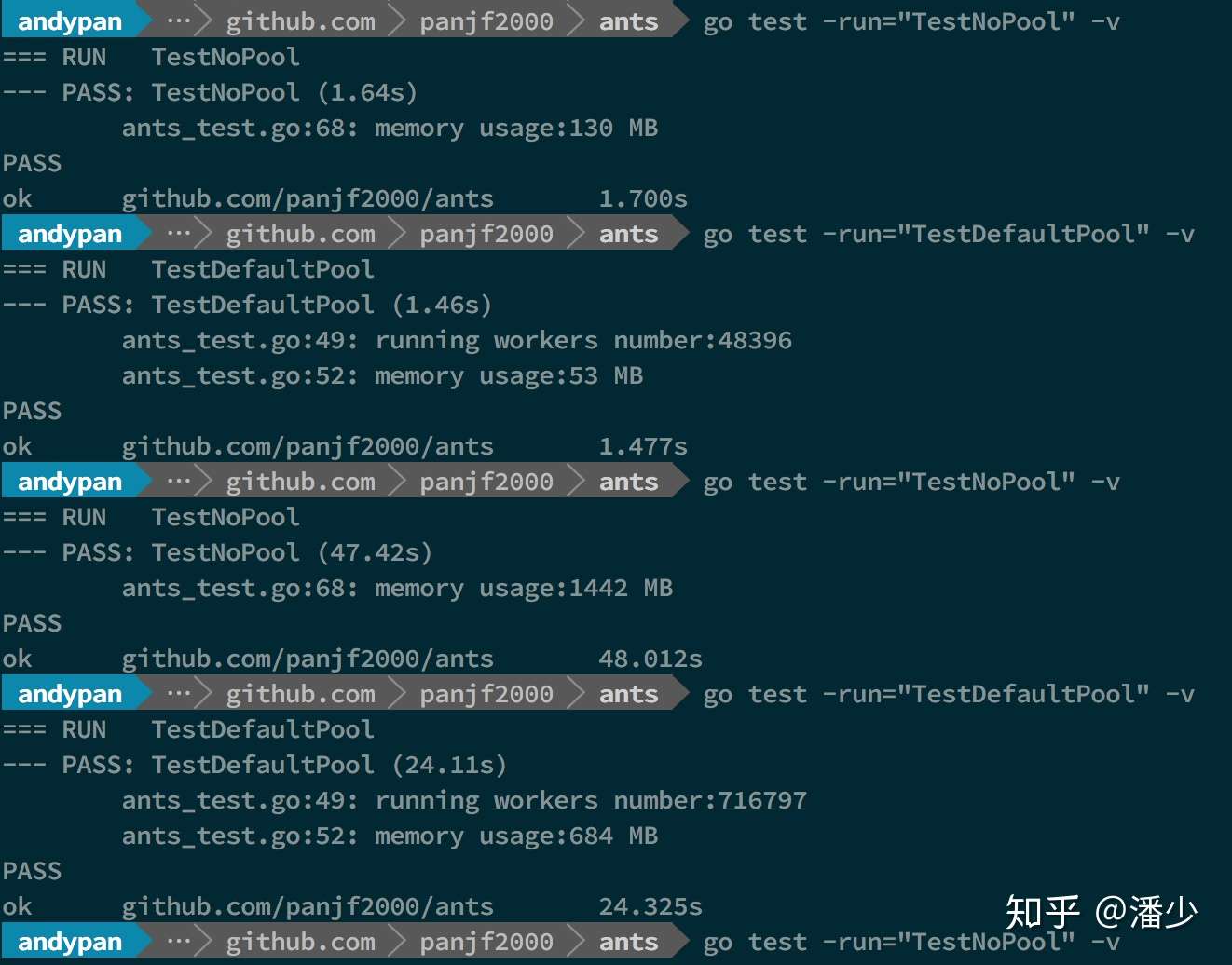 这里为了模拟大规模 goroutine 的场景,两次测试的并发次数分别是 100w 和 1000w,前两个测试分别是执行 100w 个并发任务不使用 Pool 和使用了
这里为了模拟大规模 goroutine 的场景,两次测试的并发次数分别是 100w 和 1000w,前两个测试分别是执行 100w 个并发任务不使用 Pool 和使用了 ants 的 Goroutine Pool 的性能,后两个则是 1000w 个任务下的表现,可以直观的看出在执行速度和内存使用上, ants 的 Pool 都占有明显的优势。100w 的任务量,使用 ants ,执行速度与原生 goroutine 相当甚至略快,但只实际使用了不到 5w 个 goroutine 完成了全部任务,且内存消耗仅为原生并发的 40%;而当任务量达到 1000w,优势则更加明显了:用了 70w 左右的 goroutine 完成全部任务,执行速度比原生 goroutine 提高了 100%,且内存消耗依旧保持在不使用 Pool 的 40% 左右。
PoolWithFunc 测试
测试结果:
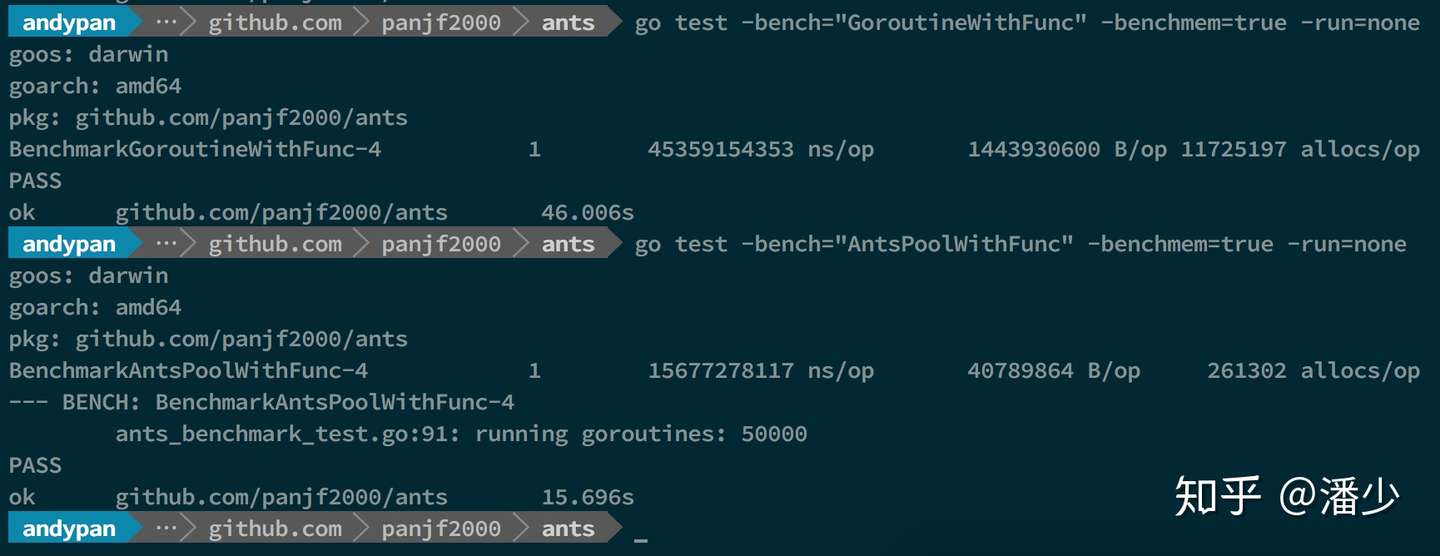
- Benchmarkxxx-4 格式为
基准测试函数名-GOMAXPROCS,后面的-4 代表测试函数运行时对应的 CPU 核数 - 1 表示执行的次数
- xx ns/op 表示每次的执行时间
- xx B/op 表示每次执行分配的总字节数(内存消耗)
- xx allocs/op 表示每次执行发生了多少次内存分配
因为 PoolWithFunc 这个 Pool 只绑定一个任务函数,也即所有任务都是运行同一个函数,所以相较于 Pool 对原生 goroutine 在执行速度和内存消耗的优势更大,上面的结果可以看出,执行速度可以达到原生 goroutine 的 300%,而内存消耗的优势已经达到了两位数的差距,原生 goroutine 的内存消耗达到了 ants 的 35 倍且原生 goroutine 的每次执行的内存分配次数也达到了 ants 45 倍,1000w 的任务量, ants 的初始分配容量是 5w,因此它完成了所有的任务依旧只使用了 5w 个 goroutine!事实上, ants 的 Goroutine Pool 的容量是可以自定义的,也就是说使用者可以根据不同场景对这个参数进行调优直至达到最高性能。
吞吐量测试
上面的 benchmarks 出来以后,我当时的内心是这样的:

但是太顺利反而让我疑惑,因为结合我过去这 20 几年的坎坷人生来看,事情应该不会这么美好才对,果不其然,细细一想,虽然 ants Groutine Pool 能在大规模并发下执行速度和内存消耗都对原生 goroutine 占有明显优势,但前面的测试 demo 相信大家注意到了,里面使用了 WaitGroup,也就是用来对 goroutine 同步的工具,所以上面的 benchmarks 中主进程会等待所有子 goroutine 完成任务后才算完成一次性能测试,然而又有多少场景是单台机器需要扛 100w 甚至 1000w 同步任务的?基本没有啊!结果就是造出了屠龙刀,可是世界上没有龙啊!也是无情...
彼时,我内心变成了这样:

幸好, ants 在同步批量任务方面有点曲高和寡,但是如果是异步批量任务的场景下,就有用武之地了,也就是说,在大批量的任务无须同步等待完成的情况下,可以再测一下 ants 和原生 goroutine 并发的性能对比,这个时候的性能对比也即是吞吐量对比了,就是在相同大规模数量的请求涌进来的时候, ants 和原生 goroutine 谁能用更快的速度、更少的内存『吞』完这些请求。
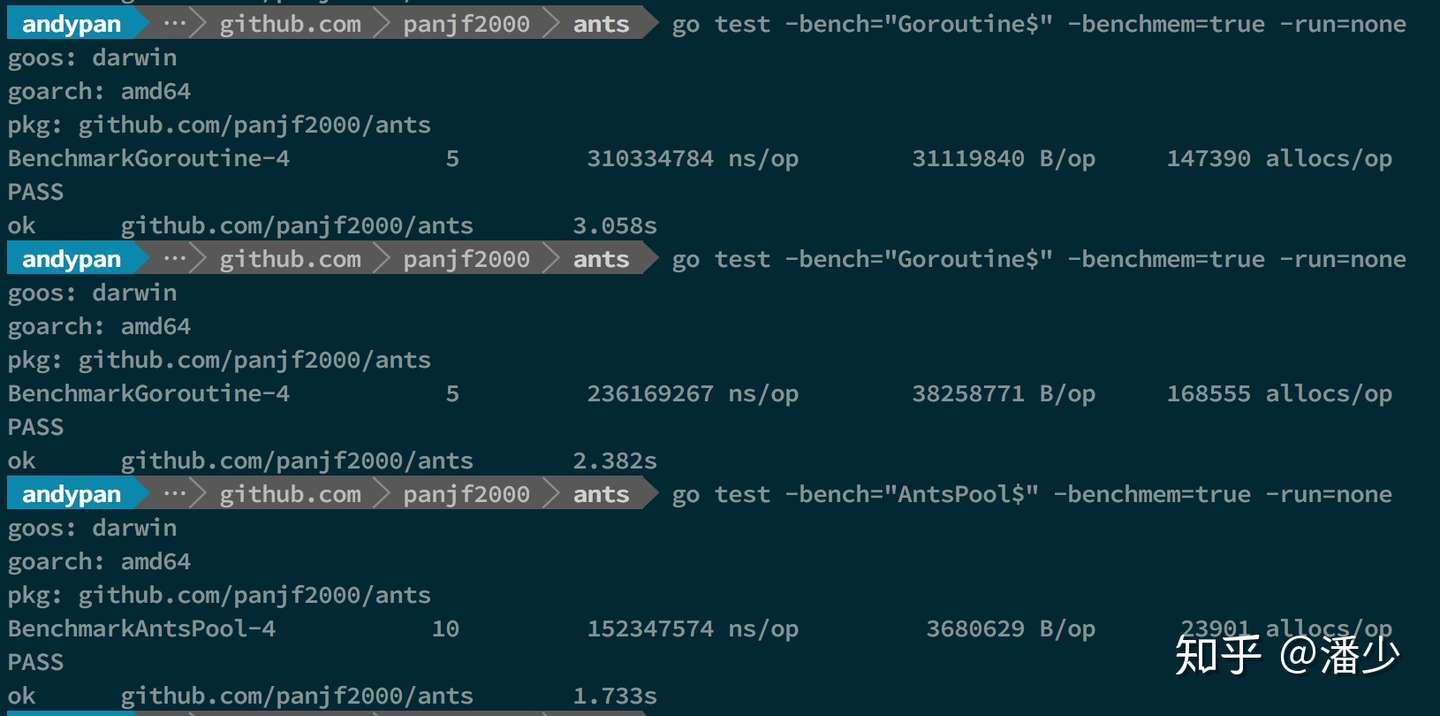
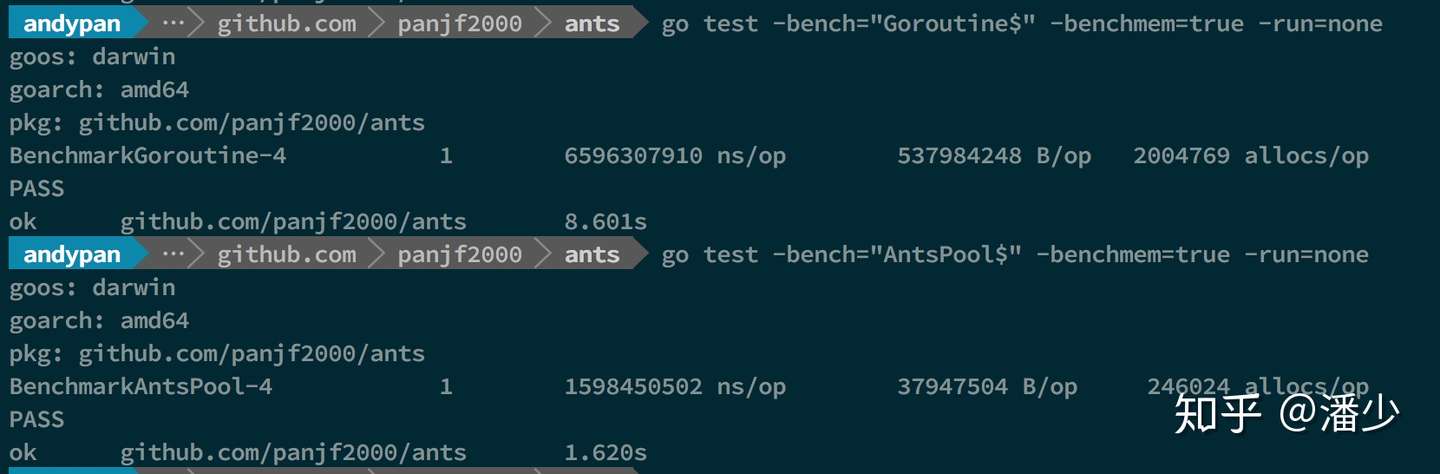
测试结果:
10w 吞吐量
100w 吞吐量
1000w 吞吐量
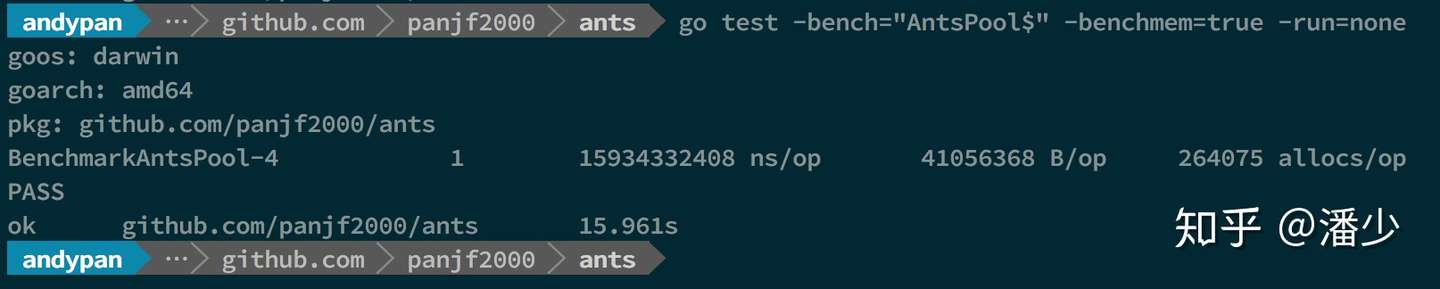
因为在我的电脑上测试 1000w 吞吐量的时候原生 goroutine 已经到了极限,因此程序直接把电脑拖垮了,无法正常测试了,所以 1000w 吞吐的测试数据只有 ants Pool 的。
从该 demo 测试吞吐性能对比可以看出,使用ants 的吞吐性能相较于原生 goroutine 可以保持在 2~6 倍的性能压制,而内存消耗则可以达到 10~20 倍的节省优势。
总结
至此,一个高性能的 Goroutine Pool 开发就完成了,事实上,原理不难理解,总结起来就是一个『复用』,具体落实到代码细节就是锁同步、原子操作、channel 通信等这些技巧的使用, ant 这整个项目没有借助任何第三方的库,用 golang 的标准库就完成了所有功能,因为本身 golang 的语言原生库已经足够优秀,很多时候开发 golang 项目的时候是可以保持轻量且高性能的,未必事事需要借助第三方库。
关于 ants 的价值,其实前文也提及过了, ants 在大规模的异步&同步批量任务处理都有着明显的性能优势(特别是异步批量任务),而单机上百万上千万的同步批量任务处理现实意义不大,但是在异步批量任务处理方面有很大的应用价值,所以我个人觉得,Goroutine Pool 真正的价值还是在:
- 限制并发的 goroutine 数量;
- 复用 goroutine,减轻 runtime 调度压力,提升程序性能;
- 规避过多的 goroutine 侵占系统资源(CPU&内存)。
后记
Go 语言的三位最初的缔造者 — Rob Pike、Robert Griesemer 和 Ken Thompson 中,Robert Griesemer 参与设计了 Java 的 HotSpot 虚拟机和 Chrome 浏览器的 JavaScript V8 引擎,Rob Pike 在大名鼎鼎的 bell lab 侵淫多年,参与了 Plan9 操作系统、C 编译器以及多种语言编译器的设计和实现,Ken Thompson 更是图灵奖得主、Unix 之父、C 语言之父。这三人在计算机史上可是元老级别的人物,特别是 Ken Thompson ,是一手缔造了 Unix 和 C 语言计算机领域的上古大神,所以 Go 语言的设计哲学有着深深的 Unix 烙印:简单、模块化、正交、组合、pipe、功能短小且聚焦等;而令许多开发者青睐于 Go 的简洁、高效编程模式的原因,也正在于此。

本文从三大线程模型到 Go 并发调度器再到自定制的 Goroutine Pool,算是较为完整的窥探了整个 Go 语言并发模型的前世今生,我们也可以看到,Go 的设计当然不完美,比如一直被诟病的 error 处理模式、不支持泛型、差强人意的包管理以及面向对象模式的过度抽象化等等,实际上没有任何一门编程语言敢说自己是完美的,还是那句话,任何不考虑应用场景和语言定位的争执都毫无意义,而 Go 的定位从出道开始就是系统编程语言&云计算编程语言(这个有点模糊),而 Go 的作者们也一直坚持的是用最简单抽象的工程化设计完成最复杂的功能,所以如果从这个层面去看 Go 的并发模型,就可以看出其实除了 G-P-M 模型中引入的 P ,并没有太多革新的原创理论,两级线程模型是早已成熟的理论,抢占式调度更不是什么新鲜的调度模式,Go 的伟大之处是在于它诞生之初就是依照Go在谷歌:以软件工程为目的的语言设计而设计的,Go 其实就是将这些经典的理论和技术以一种优雅高效的工程化方式组合了起来,并用简单抽象的 API 或语法糖开放给使用者,Go 一直致力于找寻一个高性能&开发效率的双赢点,目前为止,它做得远不够完美,但足够优秀。另外 Go 通过引入 channel 与 goroutine 协同工作,将一种区别于锁&原子操作的并发编程模式 — CSP 带入了 Go 语言,对开发人员在并发编程模式上的思考有很大的启发。
从本文中对 Go 调度器的分析以及 ants Goroutine Pool 的设计与实现过程,对 Go 的并发模型做了一次解构和优化思考,在 ants 中的代码实现对锁同步、原子操作、channel 通信的使用也做了一次较为全面的实践,希望对 Gopher 们在 Go 语言并发模型与并发编程的理解上能有所裨益。
感谢阅读。