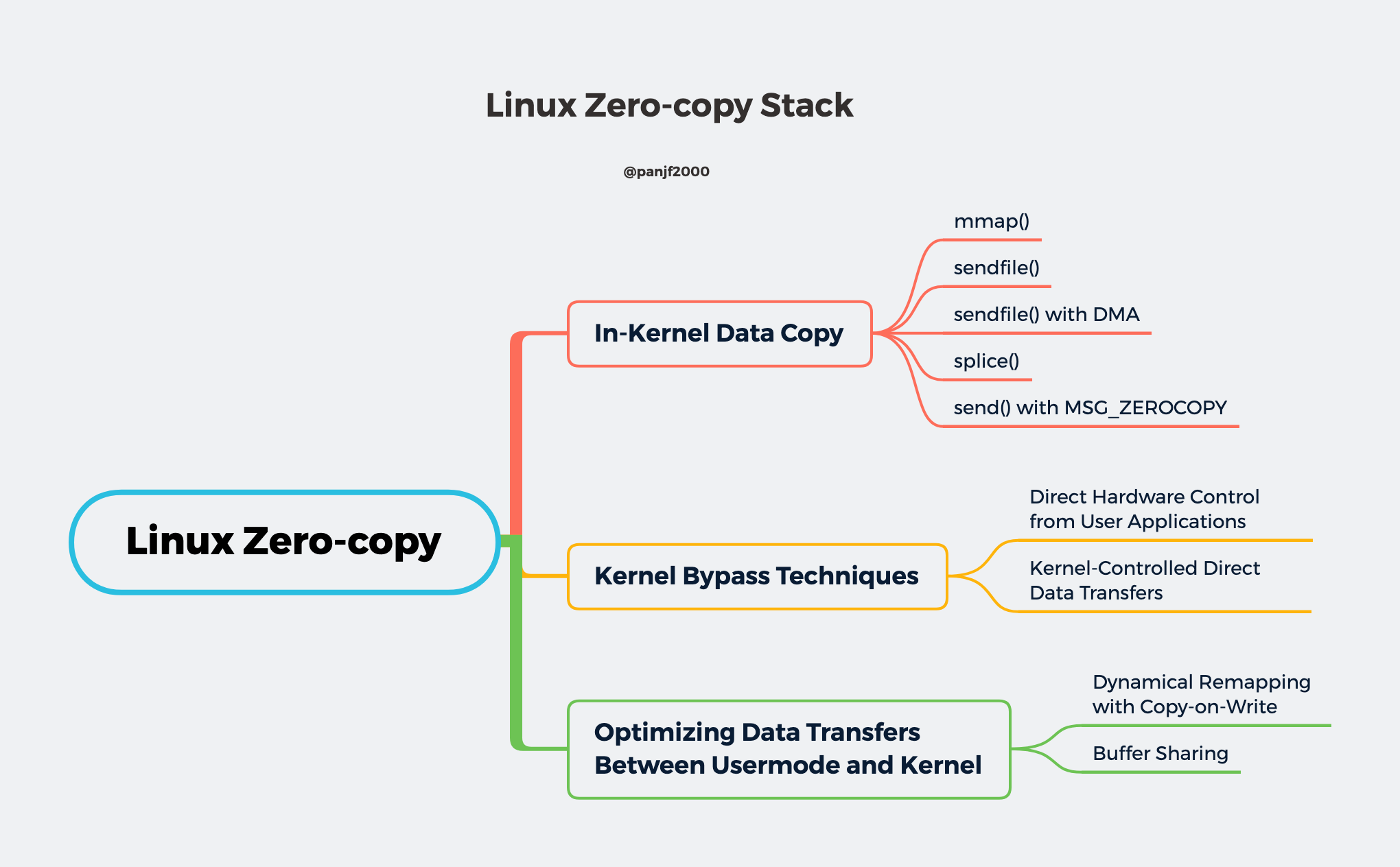
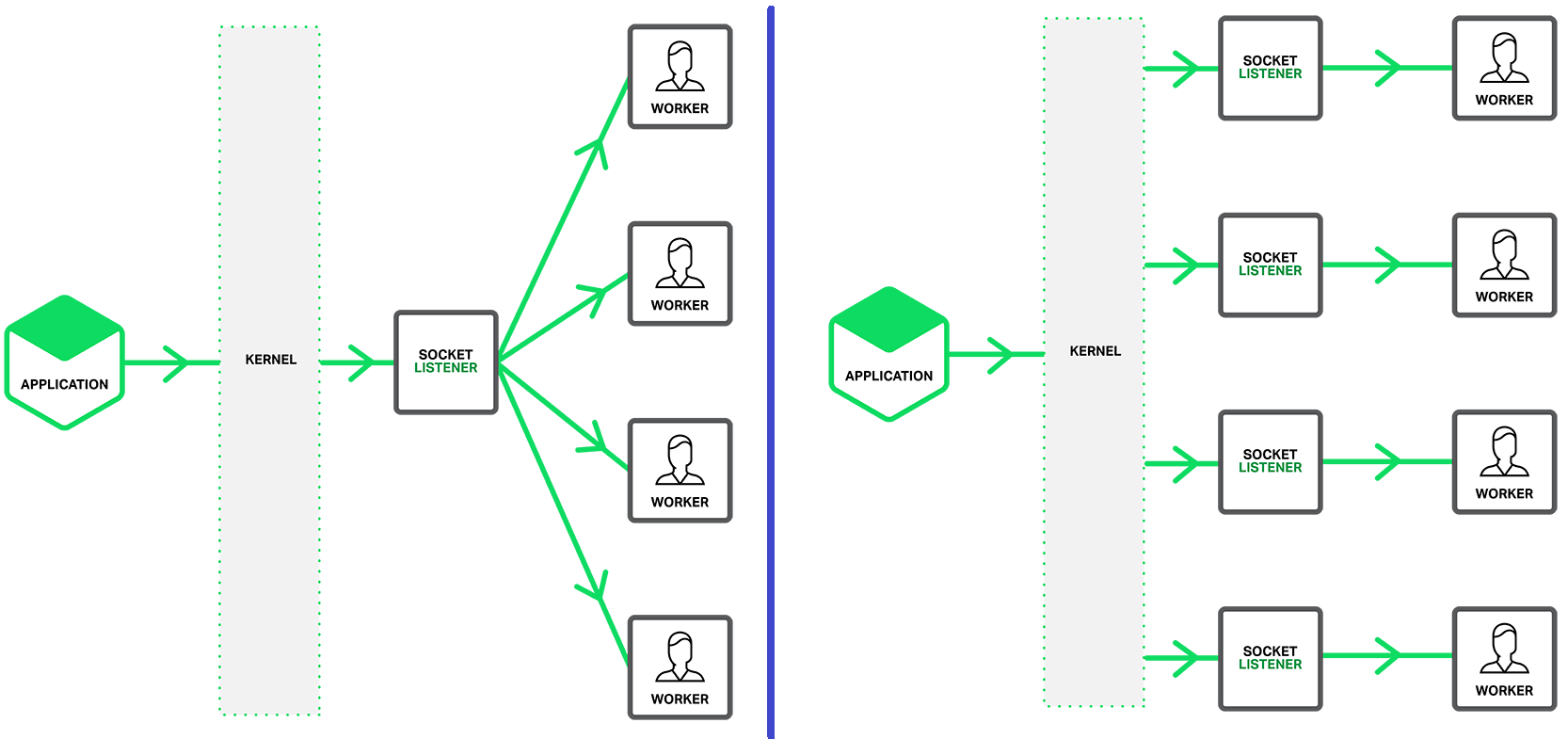
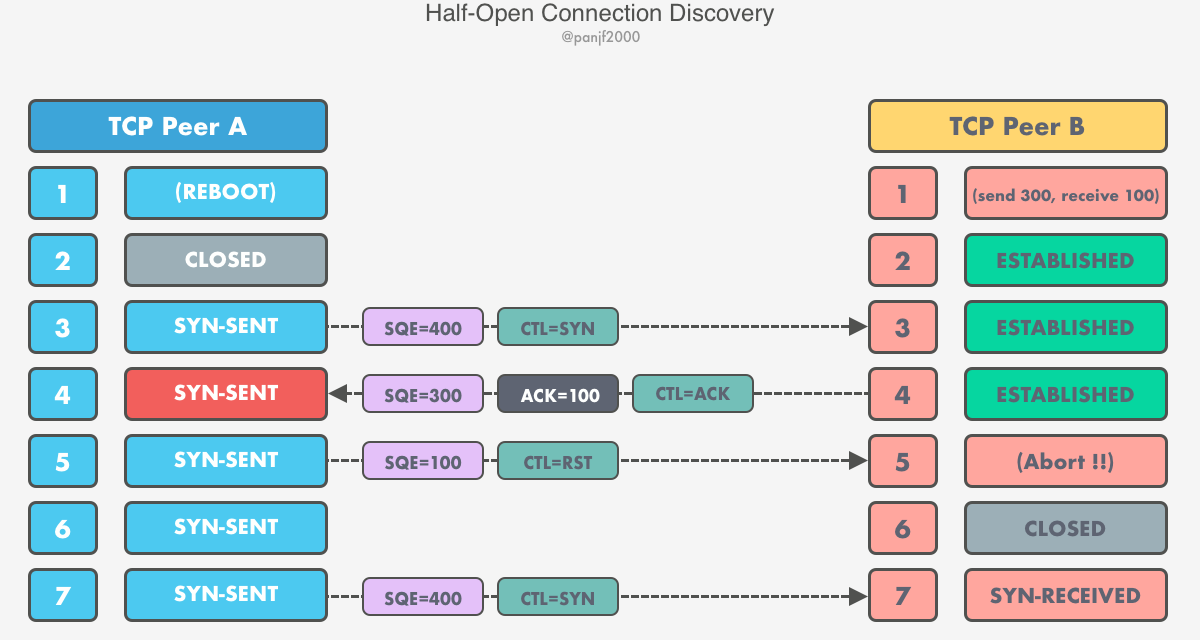
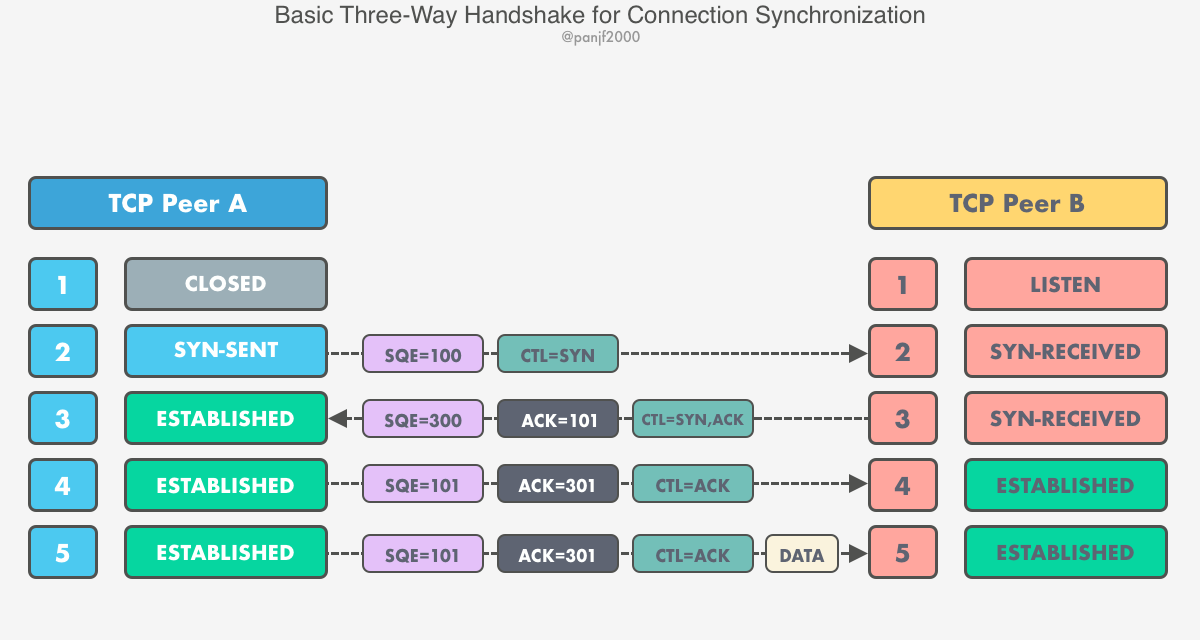
Announcing gnet v2.6.0 gnet The gnet v2.6.0 is officially released! The two major updates in this release are feat: support configurable I/O chunk to drain at a time in edge-trig
Howto deploy services with ants on DigitalOcean 技术杂谈 Introduction to ants Library ants implements a goroutine pool with fixed capacity, managing
Announcing gnet v2.5.0 gnet The v2.5.0 for gnet is officially released! The two major updates in this release are feat: support edge-triggered I/O and